针对模糊图像的处理,个人觉得主要分两条路,一种是自我激发型,另外一种属于外部学习型。接下来我们一起学习这两条路的具体方式。
第一种 自我激发型
基于图像处理的方法,如图像增强和图像复原,以及曾经很火的超分辨率算法。都是在不增加额外信息的前提下的实现方式。
1. 图像增强
图像增强是图像预处理中非常重要且常用的一种方法,图像增强不考虑图像质量下降的原因,只是选择地突出图像中感兴趣的特征,抑制其它不需要的特征,主要目的就是提高图像的视觉效果。先上一张示例图:

图像增强中常见的几种具体处理方法为:
① 直方图均衡
在图像处理中,图像直方图表示了图像中像素灰度值的分布情况。为使图像变得清晰,增大反差,凸显图像细节,通常希望图像灰度的分布从暗到亮大致均匀。直方图均衡就是把那些直方图分布不均匀的图像(如大部分像素灰度集中分布在某一段)经过一种函数变换,使之成一幅具有均匀灰度分布的新图像,其灰度直方图的动态范围扩大。用于直方均衡化的变换函数不是统一的,它是输入图像直方图的积分,即累积分布函数。
② 灰度变换
灰度变换可使图像动态范围增大,对比度得到扩展,使图像清晰、特征明显,是图像增强的重要手段之一。它主要利用图像的点运算来修正像素灰度,由输入像素点的灰度值确定相应输出像素点的灰度值,可以看作是“从像素到像素”的变换操作,不改变图像内的空间关系。像素灰度级的改变是根据输入图像f(x,y)灰度值和输出图像g(x,y)灰度值之间的转换函数g(x,y)=T[f(x,y)]进行的。
灰度变换包含的方法很多,如逆反处理、阈值变换、灰度拉伸、灰度切分、灰度级修正、动态范围调整等。
③ 图像平滑
在空间域中进行平滑滤波技术主要用于消除图像中的噪声,主要有邻域平均法、中值滤波法等等。这种局部平均的方法在削弱噪声的同时,常常会带来图像细节信息的损失。
邻域平均,也称均值滤波,对于给定的图像f(x,y)中的每个像素点(x,y),它所在邻域S中所有M个像素灰度值平均值为其滤波输出,即用一像素邻域内所有像素的灰度平均值来代替该像素原来的灰度。
中值滤波,对于给定像素点(x,y)所在领域S中的n个像素值数值{f1,f2,…,fn},将它们按大小进行有序排列,位于中间位置的那个像素数值称为这n个数值的中值。某像素点中值滤波后的输出等于该像素点邻域中所有像素灰度的中值。中值滤波是一种非线性滤波,运算简单,实现方便,而且能较好的保护边界。
④ 图像锐化
采集图像变得模糊的原因往往是图像受到了平均或者积分运算,因此,如果对其进行微分运算,就可以使边缘等细节信息变得清晰。这就是在空间域中的图像锐化处理,其的基本方法是对图像进行微分处理,并且将运算结果与原图像叠加。从频域中来看,锐化或微分运算意味着对高频分量的提升。常见的连续变量的微分运算有一阶的梯度运算、二阶的拉普拉斯算子运算,它们分别对应离散变量的一阶差分和二阶差分运算。
2. 图像复原

其目标是对退化(传播过程中的噪声啊,大气扰动啊好多原因)的图像进行处理,尽可能获得未退化的原始图像。如果把退化过程当一个黑匣子(系统H),图片经过这个系统变成了一个较烂的图。这类原因可能是光学系统的像差或离焦、摄像系统与被摄物之间的相对运动、电子或光学系统的噪声和介于摄像系统与被摄像物间的大气湍流等。图像复原常用二种方法。当不知道图像本身的性质时,可以建立退化源的数学模型,然后施行复原算法除去或减少退化源的影响。当有了关于图像本身的先验知识时,可以建立原始图像的模型,然后在观测到的退化图像中通过检测原始图像而复原图像。
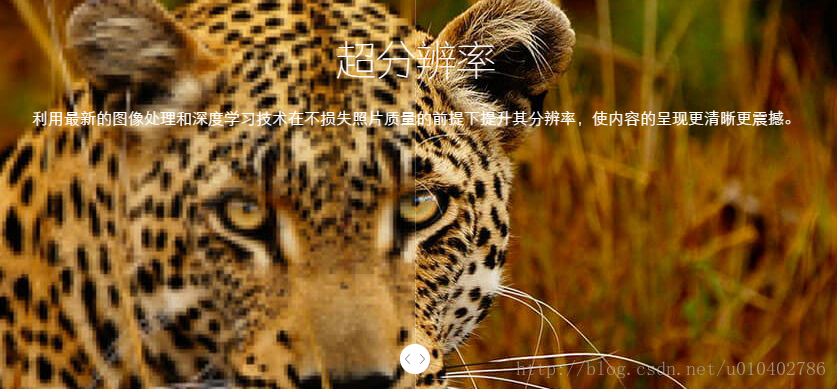
3. 图像超分辨率
一张图我们想脑补细节信息好难,但是相似的多幅图我们就能互相脑洞了。所以,我们可以通过一系列相似的低分辨图来共同脑补出一张高清晰图啊,有了这一张犯罪人的脸,我就可以画通缉令了啊。。。
超分辨率复原技术的目的就是要在提高图像质量的同时恢复成像系统截止频率之外的信息,重建高于系统分辨率的图像。继续说超分辨,它其实就是根据多幅低质量的图片间的关系以及一些先验知识来重构一个高分辨的图片。示例图如下:
第二种 外部学习型
外部学习型,就如同照葫芦画瓢一样的道理。其算法主要是深度学习中的卷积神经网络,我们在待处理信息量不可扩充的前提下(即模糊的图像本身就未包含场景中的细节信息),可以借助海量的同类数据或相似数据训练一个神经网络,然后让神经网络获得对图像内容进行理解、判断和预测的功能,这时候,再把待处理的模糊图像输入,神经网络就会自动为其添加细节,尽管这种添加仅仅是一种概率层面的预测,并非一定准确。
本文介绍一种在灰度图像复原成彩色RGB图像方面的代表性工作:《全局和局部图像的联合端到端学习图像自动着色并且同时进行分类》。利用神经网络给黑白图像上色,使其变为彩色图像。稍作解释,黑白图像,实际上只有一个通道的信息,即灰度信息。彩色图像,则为RGB图像(其他颜色空间不一一列举,仅以RGB为例讲解),有三个通道的信息。彩色图像转换为黑白图像极其简单,属于有损压缩数据;反之则很难,因为数据不会凭空增多。
搭建一个神经网络,给一张黑白图像,然后提供大量与其相同年代的彩色图像作为训练数据(色调比较接近),然后输入黑白图像,人工智能按照之前的训练结果为其上色,输出彩色图像,先来看一张效果图:

1. 本文工作
- 用户无干预的灰度图像着色方法。
- 一个新颖的端到端网络,联合学习图像的全局和局部特征。
- 一种利用分类标签提高性能的学习方法。
- 基于利用全局特征的风格转换技术。
- 通过用户研究和许多不同的例子深入评估模型,包括百年的黑白照片。
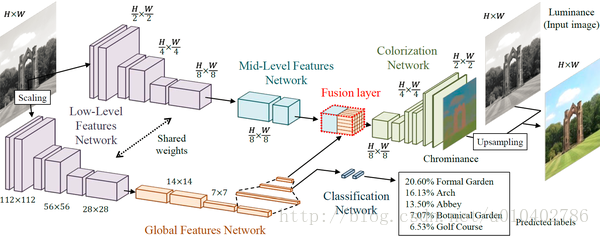
2. 着色框架
模型框架包括四个主要组件:低级特征提取网络,中级特征提取网络,全局特征提取网络和着色网络。 这些部件都以端对端的方式紧密耦合和训练。 模型的输出是图像的色度,其与亮度融合以形成输出图像。
3. 与另外两个工作对比
- Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning Representations for Automatic Colorization. In ECCV 2016.
- Richard Zhang, Phillip Isola, and Alexei A. Efros. Colorful Image Colorization. In ECCV 2016.

参考文献:
网页:http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/extra.html
代码:https://github.com/satoshiiizuka/siggraph2016_colorization
论文2:http://richzhang.github.io/colorization/
在线demo:http://demos.algorithmia.com/colorize-photos/
版权声明:本文为CSDN博主「炼丹术士」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010402786/article/details/53859569





