作者:Derrick Mwiti
编译:ronghuaiyang
导读
给大家总结了2020年以来的图像分割领域的进展,包括了结构,损失函数,数据集以及框架。

在这篇文章中,我们将深入探讨使用深度学习的图像分割。
我们将讨论:
- 什么是图像分割,图像分割的两种主要类型
- 图像分割的架构
- 用于图像分割的损失函数
- 框架,你可以用在你图像分割项目中
就让我们一探究竟吧。
什么是图像分割?
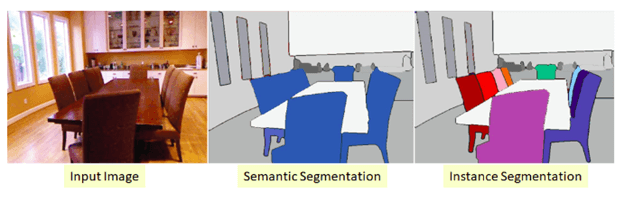
顾名思义,这是将一个图像分割成多个区块的过程。在这个过程中,图像中的每个像素都与一个目标类型相关联。图像分割主要有两种类型:语义分割和实例分割。
在语义分割中,同一类型的所有目标都使用一个类标签进行标记,而在实例分割中,相似的目标使用各自独立的标签。
图像分割架构
图像分割的基本架构包括编码器和解码器。

编码器通滤波器从图像中提取特征。解码器负责生成最终的输出,通常是一个包含目标轮廓的分割掩码。大多数体系结构都有这种体系结构或其变体。
让我们看几个例子。
U-Net
U-Net是一种卷积神经网络,最初是为分割生物医学图像而开发的。当它可视化的时候,它的结构看起来像字母U,因此取名为U-Net。它的结构由两部分组成,左边部分是下采样路径,右边部分是上采样路径。下采样路径的目的是捕获上下文,而上采样路径的作用是帮助精确定位。
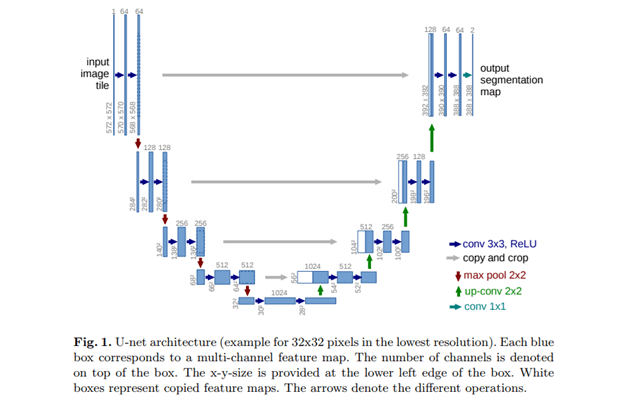
U-Net由右边的上采样路径和左边的下采样路径组成。下采样路径由两个3×3的卷积组成。卷积之后是一个ReLU和一个用于下采样的2x2的最大池化层。
你可以在这里找到U-Net的完整实现:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/。
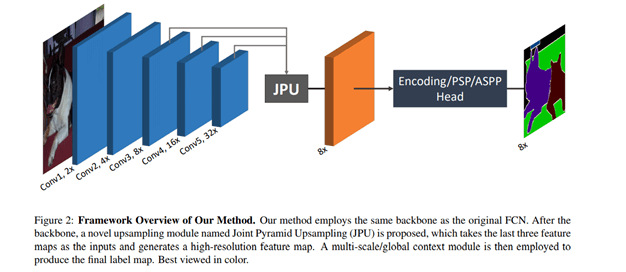
FastFCN — Fast Fully-connected network
在这个架构中,使用Joint Pyramid Upsampling(JPU)模块来代替空洞卷积,因为空洞卷积占用了很多的内存和计算时间。它的核心是一个全连接网络,同时使用JPU进行上采样。JPU将低分辨率特征图提升为高分辨率特征图。
如果你想亲自动手实现一些代码,这里:https://github.com/wuhuikai/FastFCN。
Gated-SCNN
该架构包括一个双流CNN架构组成。在这个模型中,一个单独的分支被用来处理图像形状信息。形状流用于处理边界信息。

代码:https://github.com/nv-tlabs/gscnn
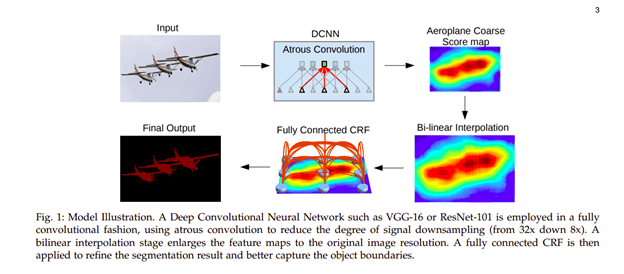
DeepLab
在这种结构中,卷积与上采样滤波器用于密集预测的任务。多尺度物体的分割是通过空间金字塔池化来完成的。最后,使用DCNNs来改进物体边界的定位。通过插入零或对输入特征图进行稀疏采样来对滤波器进行上采样,从而实现Atrous卷积。
代码:https://github.com/fregu856/deeplabv3和https://github.com/sthalles/deeplab_v3。
Mask R-CNN
在这个架构中,使用包围框和语义分割对物体进行分类和本地化,并将每个像素分类到一组类别中去。每个感兴趣的区域都有一个分割掩码。最终的输出是一个类标签和一个包围框。该架构是Faster R-CNN的扩展。

这是在COCO测试集上得到的结果的图像。

代码:https://github.com/facebookresearch/Detectron
图像分割和损失函数
语义分割模型在训练过程中通常使用一个简单的交叉熵损失函数。但是,如果你对获取图像的细粒度信息感兴趣,则必须用到稍微高级一些的损失函数。
我们来看几个例子。
Focal Loss
这种损失是对标准交叉熵的改进。这是通过改变其形状来实现的,这样分类良好的类别的损失的权重会变小。最终,这确保了不存在类别不平衡。在这个损失函数中,交叉熵损失使用一个缩放因子来进行缩放,这个因子是随着对正确的类别的置信度的增加而从0处开始衰减的。这个比例因子自动降低了训练时简单样本的权重,并将重点放在困难样本上。

Dice loss
这个损失是通过计算光滑的(dice系数)的函数。这种损失最常用在分割问题上。

Intersection over Union (IoU)-balanced Loss
IoU-balanced分类损失的目的是增加高IoU样本的梯度,降低低IoU样本的梯度。从而提高了机器学习模型的定位精度。
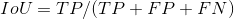
Boundary loss
boundary loss的一种变体应用于具有高度不平衡的segmentations的任务。这种损失的形式是空间等高线上的距离度量,而不是区域。通过这种方式,它解决了高度不平衡的分割任务的区域损失所带来的问题。

Weighted cross-entropy
在交叉熵的一种变体中,所有正样本都被一个确定的系数加权。它用于类别不平衡的情况。
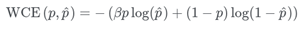
Lovász-Softmax loss
该loss基于子模块损失的凸Lovasz扩展,对神经网络的平均IOU损失进行了直接优化。

其他值得一提的损失有:
- TopK loss 其目的是确保网络在训练过程中聚焦于困难样本。
- Distance penalized CE loss 这将网络引向难以分割的边界区域。
- Sensitivity-Specificity (SS) loss 计算特异性和敏感性的均方根差的加权和。
- Hausdorff distance(HD) loss 估计了卷积神经网络的Hausdorff距离。
这些只是在图像分割中使用的一些损失函数。要了解更多,请查看这个repo:https://github.com/JunMa11/SegLoss。
图像分割数据集
如果你还在这里,你可能会问自己从哪里可以得到一些数据集来开始。
让我们看几个。
Coco数据集
COCO是一个大型的物体检测、分割和描述数据集。数据集包含91个类。它有25万标注了关键点的人,下载大小是37.57 GiB,它包含80个物体类别。
PASCAL VOC
PASCAL有20个不同的类,9963张图片。训练/验证集是一个2GB的tar文件。数据集可从:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/下载。
Cityscapes数据集
这个数据集包含城市场景的图像。该方法可用于评价视觉算法在城市场景中的性能。数据集可从:https://www.cityscapes-dataset.com/downloads/下载。
CamVid
这是一个基于动作的分割和识别数据集。它包含32个语义类。这个链接:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/包含对数据集的进一步解释和下载链接。
图像分割框架
现在你已经准备好了可能的数据集,接下来让我们介绍一些可以用于入门的工具/框架。
- FastAI library — 给定一个图像,这个库能够创建图像中物体的掩码。
- Sefexa Image Segmentation Tool — Sefexa是一个免费的工具,可以用于半自动图像分割,图像分析,并创建ground truth。
- Deepmask — Facebook的Deepmask是DeepMask 和 SharpMask的Torch实现。
- MultiPath — 这是一个来自 “A MultiPath Network for Object Detection”的物体检测网络的Torch实现。
- OpenCV — 这是一个有超过2500个优化算法的开源计算机视觉库。
- MIScnn — 是一个医学图像分割的开源库。它允许用最先进的卷积神经网络和深度学习模型在几行代码中建立管道。
- Fritz:Fritz提供了多种计算机视觉工具,包括用于移动设备的图像分割工具。
作者:Derrick Mwiti
英文原文:https://neptune.ai/blog/image-segmentation-in-2020
本文转自: AI公园,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。





