1. 参数初始化的目的是什么?
为了让神经网络在训练过程中学习到有用的信息,这意味着参数梯度不应该为0。而我们知道在全连接的神经网络中,参数梯度和反向传播得到的状态梯度以及入激活值有关。那么参数初始化应该满足以下两个条件:
① 初始化必要条件一:各层激活值不会出现饱和现象;
② 初始化必要条件二:各层激活值不为0。
2. 把参数都初始化为0会是比较好的初始化?
这样做其实会带来一个问题,经过正向传播和反向传播后,参数的不同维度之间经过相同的更新,迭代的结果是不同维度的参数是一样的,严重地影响了模型的性能。一般只在训练SLP/逻辑回归模型时才使用0初始化所有参数, 深度模型都不会使用0初始化所有参数。
3. 随机生成小的随机数
将参数初始化为小的随机数。其中randn从均值为0,标准差是1的高斯分布中取样,这样,参数的每个维度来自一个多维的高斯分布。需要注意的是参数初始值不能取得太小,因为小的参数在反向传播时会导致小的梯度,对于深度网络来说,也会产生梯度弥散问题,降低参数的收敛速度。
缺点:
一个神经元输出的方差会随着输入神经元数量的增多而变大。对于有n个输入单元的神经元来说,考虑χ2分布,每个输入的方差是1/n时,总的方差是1。
4. 标准初始化
权重参数初始化从区间均匀随机取值。即从(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量。
为什么要除以d?
这样可以确保神经元的输出有相同的分布,提高训练的收敛速度。
优点:
隐层的状态的均值为0,方差为常量1/3,和网络的层数无关,这意味着对于sigmoid函数来说,自变量落在有梯度的范围内。
5. Xavier初始化
优秀的初始化应该使得各层的激活值和状态梯度的方差在传播过程中的方差保持一致。不然更新后的激活值方差发生改变,造成数据的不稳定。
假设:
① 输入的每个特征方差一样:Var(x);
② 激活函数对称:这样就可以假设每层的输入均值都是0;
③ f′(0)=1;
④ 初始时,状态值落在激活函数的线性区域:f′(sik)≈1。
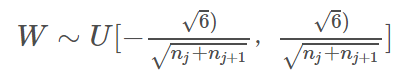
这个区间是根据以下公式得到的:

其中 nj 和 nj+1 表示输入和输出维度。
激活值的方差和层数无关,反向传播梯度的方差和层数无关。
应用:
由于ReLU无法控制数据幅度,所以可以将其与Xavier初始化搭配使用。
6. 偏置初始化
通常偏置项初始化为0,或比较小的数,如:0.01。
版权声明:本文为CSDN博主「manong_wxd」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/manong_wxd/article/details/78734725





