如果你对人工智能和机器学习的理解还不是很清楚,那么本文对你来说将会很有用。我将配合图文解说来帮助你全面理解机器学习。
如果它们不能激发你的兴趣,那我也没办法了。
但是,如果你发现自己满怀激情地阅读完了全文,那么说明你对这个新世界充满兴趣和热情。后续的进一步发展就取决你自己了。
1、工业革命级的技术红利
人工智能是从一开始就伴随着电子计算机的发明而兴起的。但是直到2012年,深度学习在图像识别上引发突破,机器学习的应用才变得如此普遍。
5年来,深度学习算法使人脸识别、图像识别、语音识别、自然语言处理等各方面都发生了突飞猛进的进展。在人脸识别、图像识别等方面迅速超过人类的水平,曾经被认为计算机算法难以完成的围棋打败了世界冠军李世石和柯洁,人类最后的智力游戏失守。
深度学习的发展进步速度可以用日新月异来形容。
从深度方向来举例,2012年的AlexNet解决了8层网络的训练问题。2014年的VGGNet就达到了19层。同年的GoogLeNet为21层。而到了2015年的Resnet,就突飞猛进到152层2017年,CVPR的最佳论文 Densenet,最高可达264层。
同年,Resnet的下一代技术ResNeXt和2017年ImageNet冠军DPNet已经不再追求层数,只用100层左右的网络就可以实现超越人类的效果。
同时,深度学习向各领域进行广度的扩充。
例如,AlexNet等网络只能对已经切割好的图片进行分类,而要进行图像识别首先还需要把每个对象识别出来。这种识别当然在深度学习大兴之前早就有了,如HOG算法、SIFT算法等。
但是深度学习的CNN更有利于提取特征,于是就诞生了2014年的R-CNN算法。后来将R-CNN中的分类用深度学习实现,产生了2015年的Fast R-CNN算法。2016年,将整个算法用深度神经网络来实现的Faster R-CNN算法完成了整个对象识别的深度学习化。并不是2012年深度学习的AlexNet的想法就可以直接用来解决对象识别的问题,但是经过4年的努力,这个任务成功实现了。
这样的例子在语音识别和自然语言处理等领域中也在不断上演。这仅仅是在应用领域,更厉害的是深度学习也深刻地改变了其他算法领域,如强化学习。
2012年深度学习突破之后,2015年,Google公司的DeepMind团队在Nature杂志上发表了将深度学习与强化学习结合在一起的深度快速学习算法DQN。2016年,基于深度神经网络与树搜索算法的Alpha Go再次在Nature杂志上发表。
最后,深度学习比起传统机器学习,门槛大大降低,正是学习的好机会。
(1)深度学习的知识点较为集中,而传统机器学习需要的领域专业知识很多且非常分散,算法不通用。
(2)开源开放为深度学习的工具的普及提供了巨大红利。不管是Google大脑用TensorFlow框架,还是OpenAI的强化学习工具,都是顶尖大厂的一线工具,免费提供给全世界使用。另外,Facebook的PyTorch,微软的CNTK,百度的PaddlePaddle等工具也都开源开放,每位学习者都能很容易用到世界上最先进的工具。
(3)Google、Facebook 等企业和机构不遗余力地研发更加方便的工具,降低使用者的门槛。例如,Keras框架就是主要面向初学者,PyTorch和TensorFlow.js等工具在设计上也充分考虑了易用性。Google的TensorFlow等也在不断探索高层API。
(4)AutoML 等自动模型生成技术初现曙光。
2、中美两国为机器学习作背书
机器学习有用的最重要证据,来自中国和美国这两个大国为其进行背书。先说我国,2017年,人工智能发展写进了政府工作报告。同年7月,国务院发布了《新一代人工智能发展规划》,其主要内容如下图所示。
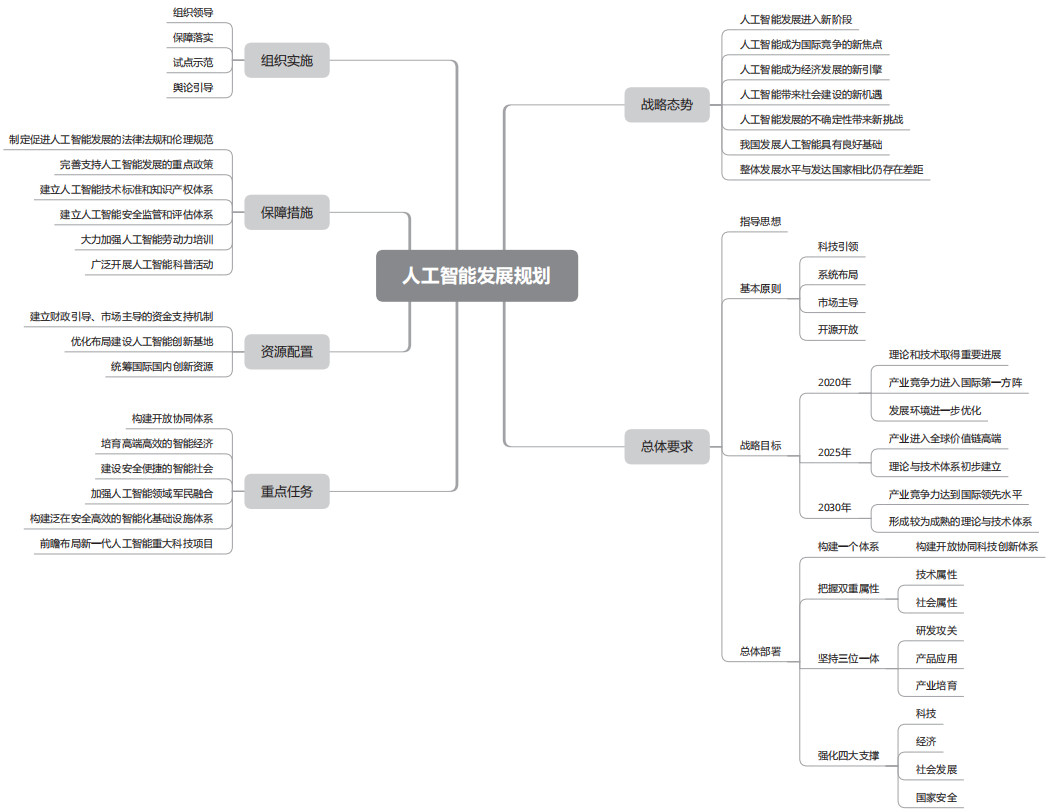
规划中首先承认了人工智能的发展进入了新阶段,给我们带来机遇,也带来了挑战。我国虽有良好的基础,但跟先进国家相比又有差距。
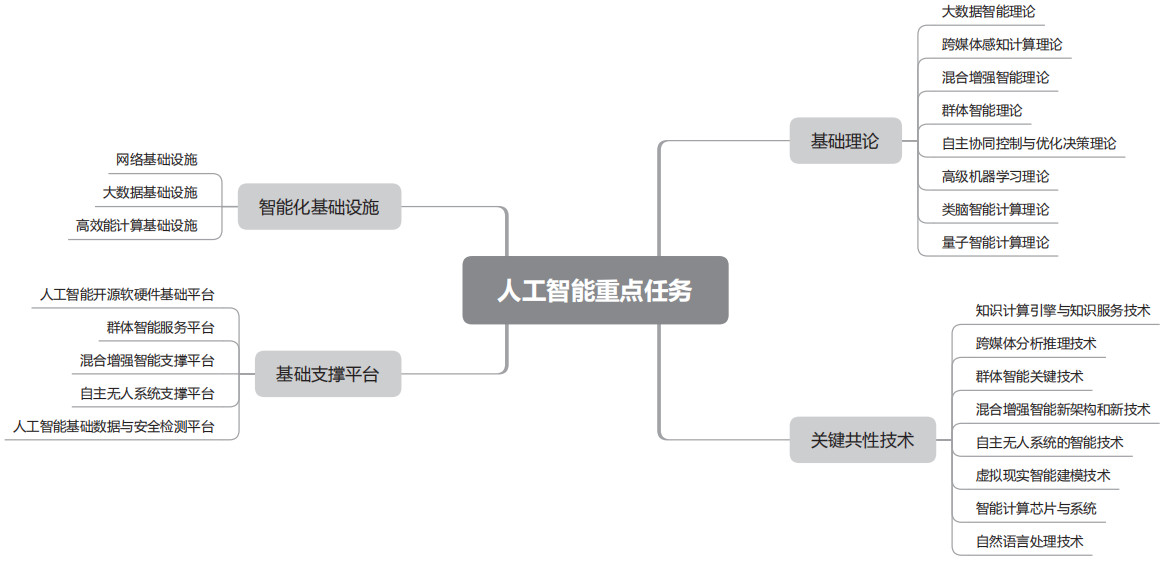
针对这个态势,国家有总体要求和重点任务,提供资源、保障,负责组织实施。这些重点任务涉及的层次比较深,比较广,不仅有基础理论研究,有关键技术攻关,还有基础支撑平台和智能化基础设施的保障。
2018年年底,美国商务部工业安全局公布了出口管制的建议公告。下面来看一下其中人工智能部分的限制出口的技术。
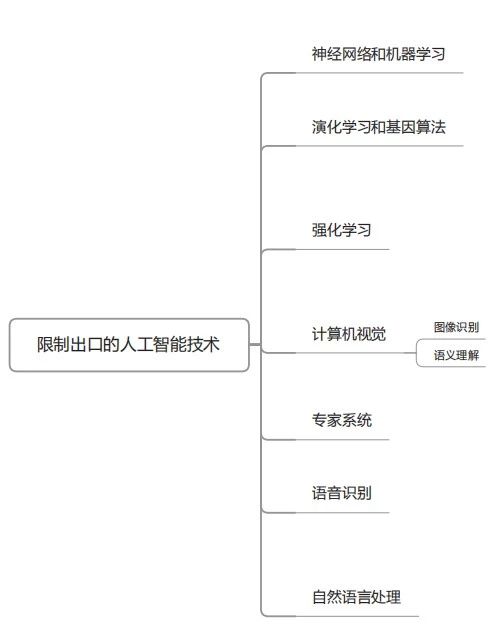
3、从编程思维向数据思维的进化
最后谈一下程序员的认知升级。
传统的软件开发方式,无论采用何种开发流程与开发模型,其代码都是确定性的指令序列。机器学习所代表的是通过数据学习、自我迭代更新,但代码不变的一种新的编程方式。
卡耐基 - 梅隆大学教授邢波说过,机器学习和传统编程的不同之处在于面对任务时,机器学习更具灵活性:传统编程是预设执行动作,按照条件触发的程序,而机器学习则没有预设执行动作,而是通过对大量场景数据的学习,自己确立触发条件和执行动作的关系,并不断迭代优化。
这段话可以说是一语道破了机器学习的本质。工具会限制人的思维,限制程序员思维的就是计算机本身。
计算机提供了指令集,将这些指令封装成汇编语言,就构成了第一代程序员的开发思维。后来出现的结构化编程、面向对象编程、面向切片编程等新思潮,本质上,还是对于机器指令的抽象与封装。这一派的典型代表是C语言,用来写作UNIX等大量的操作系统。在这一系语言中,影响最大的人物是冯·诺依曼,因为第一代计算机的指令架构就是冯·诺依曼结构。
类C语言因为本质上是计算机指令的封装,所以不管如何设计,程序代码都是核心。数据是被程序指令控制的操作数。如果程序基本没有bug,也不增加新需求,可以固化到只读硬件中,因为逻辑是确定的。
计算机硬件指令的执行,本质上只有顺序和分支两种结构:要么按顺序执行,当然固定的跳转指令也是按顺序执行;要么是if-then结构,根据条件判断来执行。
程序开发中,做得最多的事情就是根据各种情况,设计好各种分支结构。循环本质上也是一种多次执行的分支结构。
在传统编程中,数据是为程序服务的,先有程序,才能处理数据。但是在大数据时代,这种方式受到了空前的挑战。在传统方式中,编程对数据的处理本质上依赖人对数据规律的彻底了解,而在机器学习的方法中,程序除了对于现有数据规律的学习外,还要从数据的自动学习中预测没有学习到的数据的规律。
对于深度学习来讲,写代码相对比较容易。但是运行代码,需要大量的数据和计算资源。对于大型的网络来说,可能需要以天或周为单位计算,甚至更长的时间做训练。到了新的应用场景,主要用新的数据做训练,调整参数,也可能调整网络结构。但是基本很难看到像开发传统代码那样,大规模的以写机器指令为逻辑的开发工作。
举个例子来看一下两种开发模式的差别。假如,我们要开发一个自动驾驶程序,现在的问题是,我们想识别路上的交通线,但是总受路边的树的影子的影响。如何消除这个影响?
按照传统编程方式,需要定义出所有可能是树的影子的情况,然后分别通过if-then判断去处理。也就是说,还是需要人对逻辑进行梳理和控制。
而对于深度学习的方式,可能只要对网络结构做一些修改,增加一个特定的池化层就可以了。
深度学习的最大进步,就是通过大量数据的训练,可以减少传统机器学习对于算法工程师对领域问题理解的依赖,而且很多场景下效果比传统算法手工做得还要好。
好的算法是有泛化能力的,可以根据有限的数据,推断出未知的情况。而这是对现有的基于每种问题定制策略的policy base方法的重大改进。
编程方法的革命影响的将不是一个行业,而是一个元行业,因为它影响的是基础的软件技术。软件开发测试方法的变革,将深刻影响互联网、移动互联网、物联网、区块链等传统方法开发的技术。从而对于依托于这些底层技术的各行各业造成二次影响。
在传统方式下,代码一旦写好,除非升级软件,否则逻辑就是一成不变的。例如,小米的MIUI几年前之所以成功,就是迭代开发速度快,用户提了意见就马上改,每周一更新,有意见继续改。
而在基于数据智能的软件开发方法下,用户使用的数据就可能为现有的软件提供更多的增强功能。这并不需要付出多少额外的工作量,主要是思维模式需要转变。
最后一点人生启示,算法是我们应对如此复杂的世界的一个新的视角和思路。
本文转自:部分内容来源于网络,转载此文目的在于传递更多信息,版权归原作者所有。





