1. 数据增强:
旋转,翻转,裁剪和随机尺寸变换,颜色抖动,对比度和亮度变换。
优点:数据扩充有助于得到更具鲁棒性的模型以对抗光照变化和噪声问题,可以提高网络泛化能力。
2. 预处理:
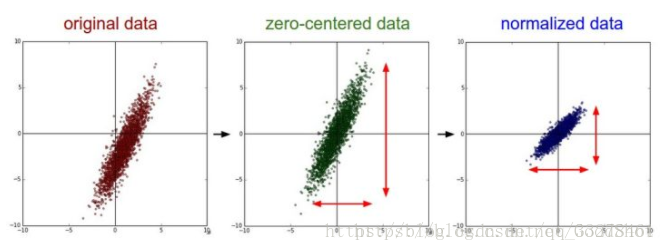
零均值化(中心化)和标准化(归一化):取消由于量纲不同、自身变异或者数值相差较大所引起的误差。
优点:标准化加速梯度下降速度(加速收敛)、有可能提高精度。
零均值化:相当于平移到中心(0,0),变量减去均值。
标准化:使得不同的特征具有相同的尺度(Scale)。如果不同维度特征尺度不一致时要用。
标准化方法:
1) min-max标准化:缺点是新数据来了后,min和max可能会变,需要重新定义。
x’=(x-min)/(max-min)
2) z-score(0-1)标准化:减去均值,除以标准差,求一个符合正态分布的数据(均值为0,标准差为1)
x’=(x-μ)/σ
注意:CNN一般不做PCA和白化;
3. 权值初始化
全0不可以:会让网络变得对称,反向传播后不同结点学到了相同参数,导致无法训练网络。
接近于0的:
随机生成的正态分布或者数值较小的均匀分布来初始化。
正态分布:
W=0.01*numpy.Random.randn(D,H)
哈维尔/Xavier 初始化(一般用这个):
随机初始化方法来初始化参数会导致输出S的方差随输入数量(X或W向量的维度)增加而变大。
为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
输入神经元多应该初始化小一些,少则应该初始化大一些,所以高斯分布除以根号n
W=np.random.randn(in,out)/np.sqrt(in)
W=np.random.randn(in,out)/np.sqrt(in/2)#relu+xavier ,因为relu小于0被截断,所有去掉一般输入
4. batch_size
batch选择会影响梯度方向,大小对结果影响还是很大的,有时候太小结果波动,效果比较差(尤其是大数据集,数据复杂的时候,小batch很难决定梯度下降方向)。
数据集小可以全数据集学习,可以更好代替样本总体,梯度下降方向更准。
数据集大,内存不够。
batch_size=1:在线学习,难收敛。每次修正以各自样本梯度方向修正。
batch_size太小(1,2),可能不收敛。
batch_size越大,处理相同数据越快,但是达到相同精度所需要的epoch越来越多。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
所以batch_size有一个饱和数值,达到时间上最优(不够尽可能大就好了)。
一般32,64 。

这部分关于batch_size参考自:https://blog.csdn.net/ycheng_sjtu/article/details/49804041
5. Batch Normalization:
每层归一化,让输入激活函数的数据分布一致。批量统计的随机不确定性也可以作为一个正则化器,它可以适用于泛化
优点:加速收敛、学习率可以改成更高、减少对初始值的依赖、正则化(可以去掉dropout)。
注意:层次太深如果每个激活函数前都加会使训练变慢,不过目前一般的网络都会用。
6. 正则化:
防止过拟合,提高泛化能力(泛化能力太弱相当于模型把数据背了下来)。
L1正则化:截断性效应:权重向量W中各个元素的绝对值之和。
能产生稀疏性,导致 W 中许多项变成零。 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。
L2正则化:缩放性效应:权重向量W中各个元素的平方和求平方根。
使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 ridge regression 并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。
Dropout:
指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
数据增强:参考1
7. 卷积核和池化参数:
输入数据一般2的整数次幂,33卷积核,步长1,0填充;池化一般22,有时候为了让特征丢失不那么快,可能前几层池化步长较小(设置1),后面在设置成大一点的(设置2)
8.学习率动态变化:
初始时设置大一些,随着训练动态改变
9. fine-tunning、预训练模型:
一般训练自己的数据都会找IMAGENET上预训练的模型在它的基础上在训练。
如果有相似度高的数据集上的模型,可能只需要微调后几层就可以达到很好的效果,而且大大节约你训练时间。

10. 激活函数:
因为线性模型的表达能力不够,引入激活函数是为了添加非线性因素。
一般都用relu,计算快,有正则化作用,缓解梯度消失。
summary:
预处理的时候0中心化,最好数据增强一下,找预训练模型,ReLU激活函数,3*3卷积核,xavier初始化,sgd+momentum或者adam比较好用,bn(可以调大学习率,收敛很快),dropout(有bn可以去掉,最好加上,会训练慢一些),batch_size大一点,另外,多尺度训练效果拔群,前几层卷积核可以多一些。
小目标检测可以用fpn结构或者强行放大图像。
误检bbox如果类别少的话(比如两类)可以在结果之后在加一个小型分类器筛选一些。
视频检测flow+rgb效果好,但是flow生成太慢,可以用flownet或者其他特征代替。
版权声明:本文为CSDN博主「星落秋风五丈原」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33278461/article/details/81123513





