随着深度卷积神经网络(CNN)在图像处理领域的快速发展,它已经成为机器视觉领域的一种标准,如图像分割、对象检测、场景标记、跟踪、文本检测等。
然而,想要熟练掌握训练神经网络的能力并不是那么容易。比如,我们常常会遇到如下问题。你的数据和硬件有什么限制?你应该是从何种网络开始?你应该建立多少与卷积层相对的密集层?你的激励函数怎样去设置?即使你使用了最流行的激活函数,你也必须要用常规激活函数。
学习速率是调整神经网络训练最重要的参数,也是最难优化的参数之一。太小,你可能永远不会得到一个合适的解决方案;太大,你可能刚好错过最优解。如果用自适应的学习速率的方法,这就意味着你要花很多钱在硬件资源上,以此来满足对计算的要求。
网络架构的选择和参数调优极大地影响了CNN的训练和性能,对于深度学习领域新入门的人来说,设计架构直觉的培养可能就是需要资源的稀缺性和分散性。
在此,作者推荐一本着重于实际调优的参考资料,供读者翻阅《神经网络:权衡技巧》。不用感谢,不过非要感谢,欢迎留言,哈哈!
那么下面,就进入我们的正式话题:14种图像分类的CNN设计模式。这14种设计模式可以帮助没有经验的研究者去尝试将深度学习与新应用结合。
一、14种图像分类的CNN设计模式
(1)网络架构遵循应用
目前,谷歌大脑或者deep Mind已经出了很多新型模型,但是这些模型中许多要么不可能实现,要么不适用于你的具体需求。那么你应该使用对应于你具体需求的模型,这些模型虽然简单,但是仍然强大。例如VGG
(2)路径的激增
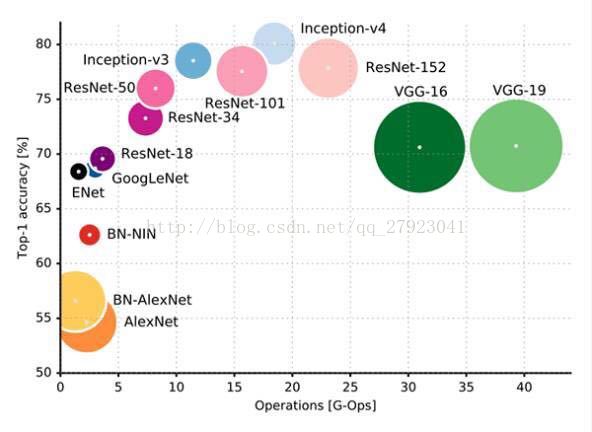
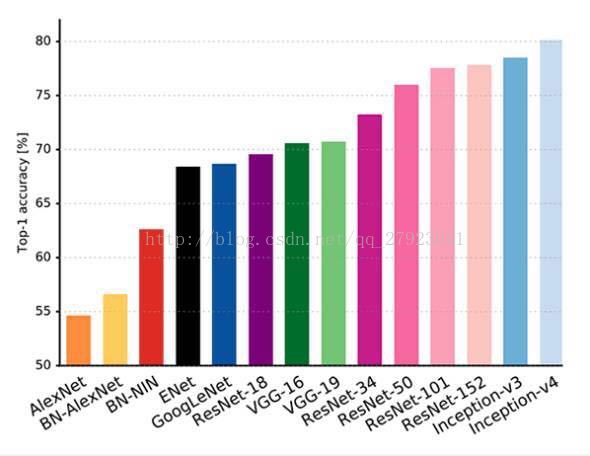
每年ImageNet Challenge的赢家都比上一年的冠军使用更加深层的网络。从AlexNet到Resnets,我们可以观察到“网络的路径数量成倍增长”趋势,而且,ResNet可以是不同长度的网络的指数集合。
(3)追求简约
“更大的并给更好的”。作者已经用自己应用证明该结论,目前也已经得到相关数据,论文撰写ing中,如果有机会,后面会与大家见面。
(4)增加对称性
类似于建筑、生物,亦或其他,对称性可以说是对质量和工艺评定的标志。用在此处,也合适。比如FractalNet。
(5)金字塔形状
你总是在表征能力和减少冗余或者无用信息之间权衡。CNNs通常会降低激活函数的采样,并会增加从输入层到最终层之间的连接通道。
(6)过渡训练
另一个权衡是训练准确度和泛化能力。用正则化的方法类似drop-out或drop-path进行提升泛化能力,这是神经网络的重要优势。用比实际用例更难的问题训练你的网络,以提高泛化性能。
(7)覆盖问题的空间
为了扩大你的训练数据和提升泛化能力,要使用噪声和人工增加训练集的大小,例如随机旋转、裁剪和一些图像操作。
(8)递增的功能结构
当架构变得成功时,它们会简化每一层的“工作”。在非常深的神经网络中,每个层只会递增地修改输入。在ResNet中,每一层的输出可能类似于输入。在ResNets中,每一层的输出可能类似于输入。
(9)标准化层的输入
标准化是可以使计算层变得更加容易的一条捷径,并且在实际中可以提升训练的准确性。简而言之,就是“标准化把所有层的输入样本放在了一个平等的基础上(类似于单位转化),这允许反向传播可以更加有效的训练”
(10)输入变换
研究表明,Wide ResNets中,性能随着通道数量的增加而提升,但是要权衡训练成本与准确性。AlexNet , VGG, Inception和ResNets都是第一层中进行输入变换,以保证多种方式检查输入数据。
(11)可用的资源决定层宽度
可供选择的输出数量并不明显,相应的是,这取决于您的硬件功能和所需的准确性
(12)Summation joining
Summation是一种比较流行的合并分支的方式。在ResNets中,使用求和作为连接机制可以让每一个分支都能计算残差和整体近似。如果输入跳跃连接始终存在,那么Summation会让每一层学到正确的东西(如,输入的差别)。在任何分支都可以被丢弃的网络中,你应该使用这种方式保持输出的平滑。
(13)下采样变化
在汇聚的时候,利用级联连接来增加输出的数量。当时用大于1的步幅时,这会同时处理加入并增加通道的数量
(14)用于竞争的Maxout
Maxout用在只需要一个激活函数的局部竞争网络中。用的方法包含所有的激活函数,不同之处在于Maxout只选择一个胜出者。maxout的一个明显的用例是每个分支具有不同大小的内核,而maxout可以尺度不变。
二、提示&技巧
除了上面所提内容,还可以参考以下技巧
(1)使用细调过得预训练网络
低水平的CNN通常可以被重复利用,因为他们大多能够检测到像线条、角点以及边缘这些常见的模式。用你自己的层替换分类层,并且用你特定的数据去训练最后的几个层。
(2)使用freeze-drop-path
drop-path会在迭代训练的过程中随机地删除一些分支。而freeze-path,则是相对于drop-path而言的,就是一些路径的权重是固定的、不可训练的,而不是整体删除。该网络可能会获得更高的精度,因为下一个分支比以前的分支包含更多的层,并且修正项更容易得到。
(3)使用循环的学习率
学习率的实验会消耗大量的时间,并且会让你遇到错误。自适应学习率在计算上可能是非常昂贵的,但是循环学习率不会。使用循环学习率时,你可以设置一组最大最小边界,并且在这个范围改变它。美国海军研究生的研究员Lesile Smith发表的关于CNN架构改进和技术提升的系统性研究论文中,提供了计算学习率的最大值和最小值的方法。
(4)在有噪音的标签中使用bootstrapping
在实践中,很多数据都是混乱的,标签都是主观性或是缺失性的,而且目标有可能是从未遇到过的。Reed等人在文章中描述了一种给网络预测目标注入一致性的方法。直观的讲,这可以实现,通过网络对环境的已知表示(隐含在参数中)来过滤可能具有不一致的训练标签的输入数据,并在训练中清理该数据。
(5)用有Maxout的ELUs,而不是ReLUs
ELUs是ReLUs的一个相对平滑的版本,它能加速收敛并提高准确度。研究调查表明,与ReLUs不同,ELUs拥有负值,这就能允许它们以更低的计算复杂度将平均单位激活推向更加接近0的值,就像批量标准化一样。如果您使用具有全连接层的Maxout,他们是特别有效的。
版权声明:本文为CSDN博主「Cche1」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_27923041/article/details/78533831





