图形学中经常要涉及使用各种格式的浮点数类型,如float,half,也会经常用到各种格式的浮点数类型PixelFormat,例如R10G10B10A2,R11G11B10,RGBHalf...。在合适的情况下使用合适的浮点数类型,是保证效率和效果的基础。虽然有些是大学本科课程,但牢记于脑海并时刻保持对每种浮点数精度的敏感也不易,此文总结并详细讨论一下各种常见浮点数的精度,范围,精度分布及应用特点。
1. 小数的二进制表示
首先浮点数只是一种小数的表示方式,整数的二进制表示是一个简单的十进制到二进制的转换,即从右到左,每个二进制的1表示1,2 ,4 , 8 , 16,例如111即7,而小数的二进制则是从从左到右的每个1依次表示为1/2, 1/4, 1/8, 1/16,例如111.111即表示了1+2+4+0.5+0.25+0.125即7.875。
我们知道小数和整数不一样,小数在一段区间内是无限多个的,所以无论怎样都不能连续的表示出一段区间内的所有小数,即小数的表示存在一个最低精度的,如果向上面那样用三位表示小数部分,那小数的精度就只有1/8,即7.875可以表示,但是7.876就表示不出来了,也会变成7.875.
上面这种表示方法小数点的位置是固定的,固定小数点前有多少bit表示整数,小数点后有多少bit表示小数,所以叫做定点数表示法,定点数的特点是表示的小数的精度是均衡的,例如fixed 11类型的定点数,在-2到2区间内的精度一直是1/256,因为他有8位表示小数。
而浮点数是把小数拆成尾数(mantissa -M)和指数(exponent- E)来表示,根据IEEE754标准,表示一个小数的方法为,拿float32为例子,s占用1位,M占用23位,E占用8位,下面设M有m位,E有e位。
其中S是1bit的符号位,表正负
M是1.xxxxx的一个小数,而M正是对这个小数部分XXXX的二进制表示
其中E是指数部分,E就相当于将二进制的M中的小数点向右(E为正),或向左(E为负)移动e个位,这也是浮点数中浮点的意义,即浮点数是通过浮动1.xxx的小数点的位数来表示任意大小的小数,E的移动是2倍的改变,所以浮点数可以表示的范围很大,但是是以损失精度为代价的。
浮点数中的E的正负同整数的正负表示不一样,它不是补码表示法,即不用首位表正负,而是按照无符号处理的值减去整个值域的中位数成为最终的值,例如8位的E的中间数是127,那么00000000就表示-127,而11111110则表示127,E的范围是 到 。(全1有特殊意义),float32 就是[-127,127]
此外浮点数的表示有一些特例,大部分浮点数类型要求可以表示一个无穷大值,所以浮点数在一些情况下不只是按照上面的公式计算数值,还有下面几个特殊情况:
E全为0,此时M将变成0.xxxxx的形式,不然永远不能表示0,所以M为全零,E为全零就是表示的浮点数0,如果E全零,而M不全零,那么也按照上面公式将0.xxxxx向左移最大的127位,这个时候相当于表示了一个非常接近于0的一个小数(小数点后充填了127个0)。
E全为1,此时不按上面公式,如果M全为0,表示正负无穷大,如果M不全为0,表示不是一个合理的数字(NAN,not a number)。
2. 浮点数的精度和范围
浮点数的精度由整数部分的精度和小数部分的精度组成:
关于整数部分的精度,浮点数可以保证在正负范围内的整数连续,这个+1是因为M的整数部分是1导致的(当然要保证E的最大表示范围要大于等于M的位数),所以float32可以保证在正负2^24 之间的整数是同int32是可以对应的,但是超过 2^24的部分不能保证所有的整数部分都可以被表示,超过的部分只能表示2^24以内整数的2^N倍(因为这时没有有效的尾数,只能继续偏移小数点了,当然N还要取决于E的范围),所以从float 强转到int要保证准确的话,float的值最多就在2^24以内,即16777216以内,同样double转long时保证正确性,double的值最多也在2^53以内。
相对于整数部分的精度,其实我们往往更关心小数部分的精度,因为通常浮点数的E的最大值要大于M的位数,所以在相当大的范围内整数是能连续不丢失精度的,所以小数部分的精度就很关键。浮点数相比于定点数,在同样bit数下面表示了更大的范围,但是损失了精度,且有个特点,浮点数的精度随着绝对值的增大而大幅度降低。
M的bit数就定了这个小数最大的精度,因为M里面存在了一个1,所以 浮点数的小数部分最多的有效数字是m+1 位,出现在-1到1之间,即0.xxx的时候xxx最多可能有m+1位,精度至少可以到达,float32 就是,当然如果e可以再往左浮动,还可以精确到更小,在E为全0时,可以表示到的最接近0 的那个正数是小数点之后有127+22=149个0,即2^-150,随着浮点数的增大,其小数部分的有效数字随着值增大而减少,1.xxxx的时候精度最多只能到1/2^m了,2.xxxx就最多只能到1/2^(m-1).
所以总体上看,浮点数在-1到1之间,也就是0.xxxx的部分精度非常高,最少可以到1/2^(m+1),无限接近0的过程中对于float32最高可以到达1/2^(127+23)。随着整数部分变大,小数精度就逐渐丧失,直到2^(m+1) -1 将完全没有小数位。
至于浮点数可以表示的极限值,首先它可以表示一个形式上的正负无穷大,除了无穷大之外,最大值出现在E为2^(e+1)-2 (对于float32即e为127,128是无穷大) 并且M为全1 的时候,这时候的值对于float32来说是(2^24 -1)* 2^(127-23),即2^128 - 2^104,最小值同样。这个值大约是3.4e+38,其实讨论这个极大值在多数情况意义并不是很大,因为它的精度已经降到了1.7e+38,所以对于浮点数如果抛开精度去谈范围已经没有太大意义,使用浮点数一定要考察它在不同值区间上的精度变化。
3. 图形编程中常用的几种浮点数及其精度随值域的改变
图形学中用于无压缩的贴图或者rt中,常用的浮点类型有很多,无论是R10G10B10A2,R11G11B10,RGBHalf,从组成的基础上看,都是归结到这几种浮点格式:
32bit, 即上面举例讨论的最代表性的float类型,1位符号位,23位M,8位E,例如RGBA32F格式
16bit,即half,半精度的浮点型,1位符号位,10位M,5位E,例如RGBA16F格式
11bit,无符号浮点数,6位M,5位E,例如R11F_B11F_G10F格式
10bit,无符号浮点数,5位M,5位E,例如RGB10_A2格式
上面这些通常都可以表达HDR信息,即可以大于1,而LDR格式类型如RGBA8则用8位表示小数,它就不是浮点数,可以理解是定点数,表示精度恒定间隔1/256的一些小数。
以10bit的浮点数为例子,绘制出它的精度误差如下
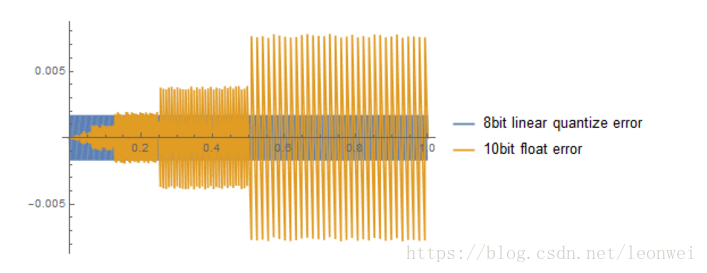
其中蓝色是8bit顶点数的误差,黄色是10bit浮点数的,可以看到,随着0.25,0.5,1的提升,它的误差会变得非常大,
10bit的浮点数在1.xxxx之内的精度也只有1/32,大约0.03,要进入0.25以下才能精确到百分位,在7.xxx左右就降低到只有十分位了
11bit的浮点数在1.xxxx之内的精度有1/64,只有在0.5以内能保证百分位,在15.xxx左右降低到十分位。
而16bit的浮点数在15.xxxx之内都能保证百分位,在255.xxx能保持十分位,32bit的浮点数在2^21左右保证十分位,在2^17左右还能保证百分位。
由此可以看出类似10bit 11bit 这种所谓的小浮点数其实高精度区间非常有限,他们只适合表示差不多10一下的一些小数。
4. 实际应用中的选择
在图形编程中,使用小数的地方很多,位置,uv,颜色,法线,pbr的参数等等,使用的bit数越高,精度效果越好,但是性能会越差。
对于位置来说,由于场景的范围可能很大,且仍然需要精确到mm左右,所以一般都要用32bit的float,但有时对于超级大的场景来说即使用float32仍然不够,当坐标刻度大于2^21次即2097152左右就不能保证十分位了,比如说你场景单位是cm,这个值就大约是21km,超过21km的大场景地图也并不是没有的,这里就捉襟见肘了。在UE4中,它为了保证这个毫米精度,当当前的摄像机视角超过这个2097152的坐标位置,就会把场景的中心整体平移到摄像机这里,这样可以保证摄像机周围的物体在渲染的时候,精度一定可以保证在mm的精度内。
对于uv来说,通常16bit的half已经足够了,它在大约15以内具有百分位精度。
对于颜色,如果是LDR的值,大多数情况8bit的定点数是足够的,如果是HDR,就又要取决于HDR的高值可能出现在多高,如果在8以内,RGB10A2是能够保证十分位的,如果在16以内,可能需要升级到R11G11B10,如果有更高的值域范围,那就需要升级到RGBA16F了。
对于法线,金属度,光滑度等,通常因为可以归一化01区间,所以8bit的顶点数就够了。
总之我们的原则一定是在保证所需的效果的同时使用最低bit的浮点数格式,因为这意味着带宽的节省,意味着alu的效率提升,最终就是帧率的提升和发热量的减少。
版权声明:本文为CSDN博主「leonwei」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/leonwei/article/details/82805103