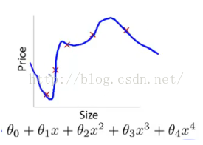
我们以图像形式说明下欠拟合、正常拟合、过拟合的场景,左图为欠拟合,此时算法学习到的数据规律较弱,有较差的预测效果,中图为正常拟合的形态,模型能够兼顾预测效果和泛化能力,右图是过拟合的情形,此时模型对训练集有较好的预测效果,但是因为其过度拟合于训练数据,所以对未见过的数据集有较差的预测效果,也就是我们通常说的低泛化能力。

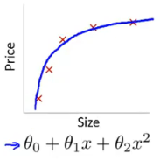
欠拟合问题
欠拟合问题易于解决,其基本方式有:
[1]增加迭代次数,使用更多的数据喂养模型,使得模型有更强的拟合能力。
[2]增加网络的深度和广度,增大神经网络的'容量',使得模型有更好的空间表示能力。
过拟合问题
在DNN中常用的解决过拟合方法有:
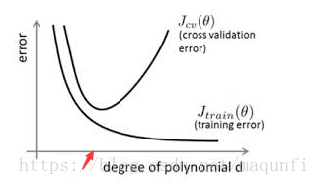
[1]早停策略。早停是指在使用交叉检验策略,每隔一定的训练次数观察训练集和验证集上数据的准确率,从而可以比较观察找到合适的训练次数,及时在下图红点出停止,防止网络过度拟合训练集。
[2]集成学习策略。用bagging的思路进行正则化,对原始的m个训练样本进行又放回的随机采样,从而可以可以使用有放回的方式构建N组m个样本(里面可以重复)数据集,然后让这N组数据去训练DNN,这样可以DNN往一个样本模式过度拟合,而能学习综合的样本特征,但是这样的方式会导致数据量增加,训练更耗时。
[3]Dropout策略。方法是在前后向传播算法每次迭代时随机隐藏一部分神经元不参与计算,并使用这些隐藏一部分数据后的网络去拟合一批数据,通过这种随机隐藏,来提升拟合限度,防止生成太拟合数据的函数式,但是这样方式需要有大量数据集来喂养,否则会导致欠拟合。
[4]正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项(代表模型复杂度,又可称为惩罚项),这样我们令损失函数尽量小时,也会同时会让后面正则项代表的模型复杂度尽量小,通过这样的限制来防止模型结果过于复杂,从而有更好的普适效果。
如下式说明目标变为要找到使损失函数和正则项都小的参数。
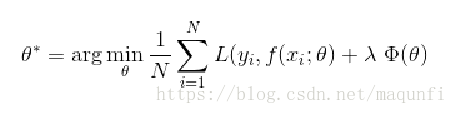
版权声明:本文为CSDN博主「马飞飞」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/maqunfi/article/details/82634450





