前提
最近在阅读《Real-Time Rendering》Third Edition时,发现对于渲染管线中不同剔除部分的具体含义和生效阶段不甚明了,遂做了一点研究,在这里做一个记录。
涉及到的剔除方法包括:
• 视椎体剔除
• 遮挡剔除
• 视口剔除
• 背面剔除
• 深度剔除
以下对于这几种剔除方法分别进行分析:
视椎体剔除
发生在应用程序阶段(Application Stage),一般由游戏引擎内部实现或者自己编写对应的算法来实现,运行在CPU上。裁剪的依据主要是根据摄像机的视野(field of view)以及近裁减面和远裁剪面的距离,将可视范围外的物体排除出渲染,被剔除的物体将不会进入渲染的几何阶段(Geometry Stage)。视椎体剔除是减少渲染消耗的最有效手段之一,可以在不影响渲染效果的情况下大幅减少渲染涉及到的顶点数和面数。
根据不同引擎的的实现,实际时候时可能有一些需要注意的地方。经过测试,Unity中默认ShadowMap的生成会大幅影响视椎体剔除的范围,对于移动平台不使用实时阴影的情况下,可以尝试关闭灯的阴影投射或者去掉简单sheder中的FallBack(通常会含有ShadowCaster),就会使同屏渲染面数大幅减小。
遮挡剔除
发生在应用程序阶段(Application Stage),由游戏引擎实现,运行在CPU上。以Unity为例,需要根据场景中Static物体的位置预先生成场景OcclusionCulling数据,运行时就可以剔除对应静态物体之后的其他物体。遮挡剔除是减少渲染消耗的有效手段之一,可以和视椎体剔除同时生效,进一步减少渲染的消耗。
针对Unity中遮挡剔除中的使用和研究,https://blog.csdn.net/cartzhang/article/details/52684127 中总结的很好。
随着硬件技术的提升,目前GPU已经可以支持在没有应用程序阶段额外数据的支持下在硬件侧面实现遮挡剔除(在光栅化之后,像素着色器之前,优于渲染管线末尾才进行的深度剔除)
https://blog.csdn.net/cartzhang/article/details/72420731 一文中提到:
“现代GPU中运用了Early-Z的技术,在Vertex阶段和Fragment阶段之间(光栅化之后,fragment之前)进行一次深度测试,如果深度测试失败,就不必进行fragment阶段的计算了,因此在性能上会有很大的提升。但是最终的ZTest仍然需要进行,以保证最终的遮挡关系结果正确。”
视口剔除
发生在几何阶段(Geometry Stage)后期,投影变换之后屏幕映射之前,是渲染管线的必要一环。只有当图元完全或部分存在于规范立方体内部的时候,才将其返送到光栅化阶段。其中,对于完全位于规范立方体内部的图元,则直接进行下一阶段;完全处于规范立方外部的图元则完全被舍弃;部分处于规范立方体内部图元,则会根据视口进行对应的裁剪,在这一过程中可能会产生新的顶点。
通过视口剔除可以将视口外的图元舍弃掉,减小光栅化阶段的消耗。
背面剔除
背面剔除即是将背向视点的图元剔除,因为它们对最终渲染的图像没有贡献。这是一种简单直观的操作,一次对一个多边形进行操作。剔除的基本原理是先判定多边形的朝向,并和当前的观察方向进行比较
更为详细的说明可以在《Real-Time Rendering》第14章加速算法找到,也可参照浅墨大大的总结文章 https://blog.csdn.net/poem_qianmo/article/details/78884513
Unity中的背面剔除在光栅化阶段进行,执行在Vertex Shader 之后,在Fragment Shader片元着色器之前,通过Shader中的Cull指令来控制背面剔除的开启和关闭, Unity手册上的图示显示的比较清晰:
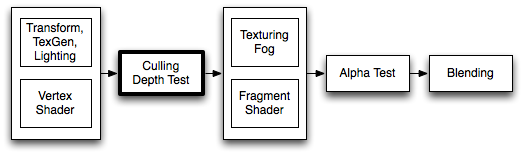
https://docs.unity3d.com/Manual/SL-CullAndDepth.html
深度剔除
在Fragment Shader之后,光栅化阶段末期的融合阶段执行,又叫深度检测(或Z缓存检测)。每次将一个图元回执为相应的像素时,都会计算像素位置处图元的深度值,和深度缓存中对应像素的值进行比较,如果新计算出的深度小于缓存中的深度,则更新深度缓存中的值;如果深度值大于深度缓冲中的值,则计算结果被舍弃,深度缓冲的值也无需更新。
在执行深度剔除时,已经位于渲染管线末尾,所有的颜色计算都已经完成,因此意义只在处理图元的可见性问题,对于渲染的消耗基本没有影响,不是优化时需要重点考察的问题。
总结
在考虑渲染优化的问题上,应当优先考察”视椎体剔除”和”遮挡剔除”是否在项目中正常运作,这两项会极大的影响到实际渲染时的消耗。
其次需要考虑背面剔除的开启,在没有大量使用单面的模型情况下,背面剔除可以在不影响显示的前提下少处理一半的像素着色运算。
视口剔除和深度剔除是渲染管线的固有部分,不在优化的主要考察范围内。
一些有趣的问题
Unity在shader中如果要进行深度相关的计算(景深,软粒子等相关效果时),需要取到当前像素的深度值,因而需要使用ShadowCaster通道来保证对应物体出现在读取的深度图上(Camera额外生成),为什么不直接使用当前绘制过程中深度缓存中的值?
因为深度缓存中的值在光栅化的融合阶段才开始写入,Fragment Shader中自然无法读取到。这边Unity的实现是在正式渲染之前由Camera预先渲染一张深度图,并设置到ShaderLab全局变量中,这里只有拥有ShaderCaster Pass的物体才会被绘制在这张深度图中(这里比较迷,将阴影投射和深度图生成绑定)。在正式渲染时就可以通过图元在视口中的位置从全局变量中获取对应的深度值。
视椎体裁剪和遮挡剔除是否会同时生效,有必要一起使用吗?
视椎体裁剪是将视椎体外的物件排除在渲染之外,由引擎默认处理(关联到一些特殊情况可能会效果不理想,如上面提到的ShadowMap生成),而遮挡剔除是将摄像机看不到的物体剔除,这包括视椎体范围内的一些物体,因此这两项可以同时生效,在大部分情况下也应当一起使用。
RTR3中的一张图描述的很清晰:
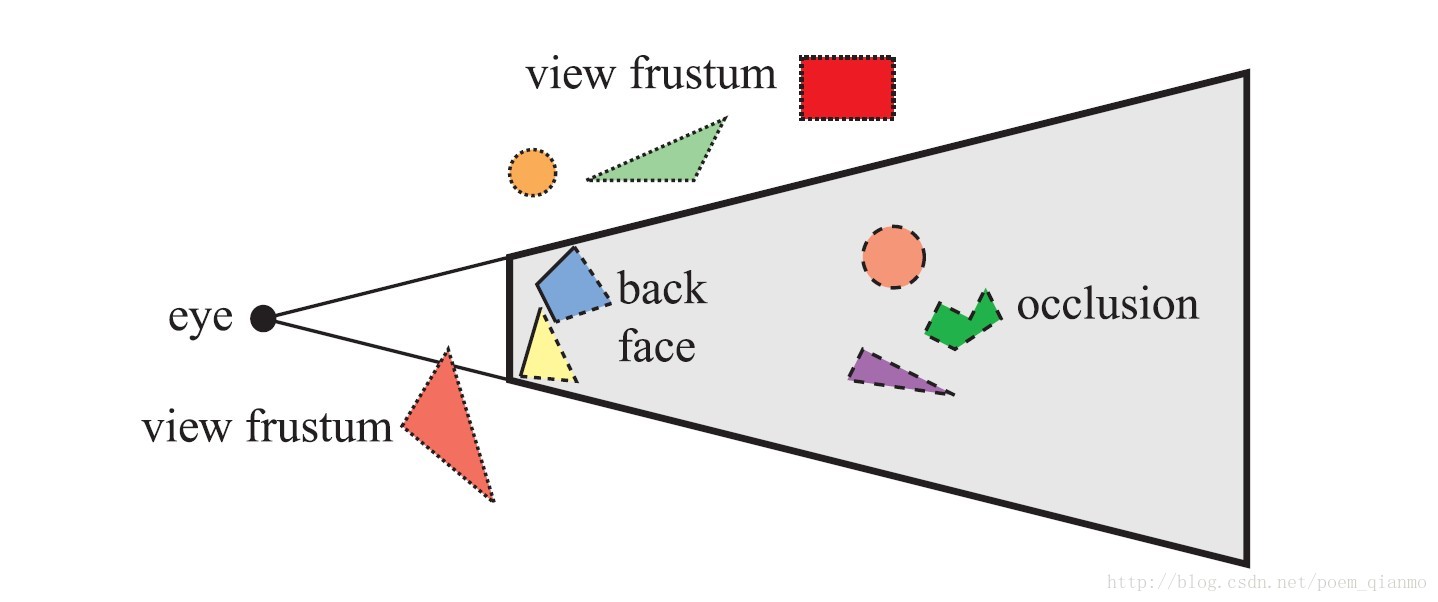
另外推荐一下《Real-Time Rendering》Third Edition这本书,对于渲染流程的总结非常到位,是渲染入门的必备书目,我读后感觉受益匪浅,推荐有兴趣的同学都能找对应的资源来读一读,另外推荐一下浅墨大大的RTR3读书总结 https://blog.csdn.net/poem_qianmo?viewmode=contents。
版权声明:本文为CSDN博主「风小锐」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/game_fengxiaorui/article/details/79958722