在这篇文章中,你将了解在机器学习模型开发生命周期(MDLC)中应用的一些缓解偏差的策略,以实现偏差感知机器学习模型,我们主要目标是实现更高精度的模型,同时确保模型与敏感/受保护属性相比具有较小的判别性。简单来说,分类器的输出不应与受保护或敏感属性相关联。构建这样的ML模型成为多目标优化问题。分类器的质量是通过其准确性和基于敏感属性的偏差来衡量的; 更准确,更好,更少判别(基于敏感属性)越好。
以下是一些偏差缓解方法:
- 预处理算法
- 处理(中)算法
- 后处理算法
以下是表示机器学习模型的偏差缓解策略的图表:
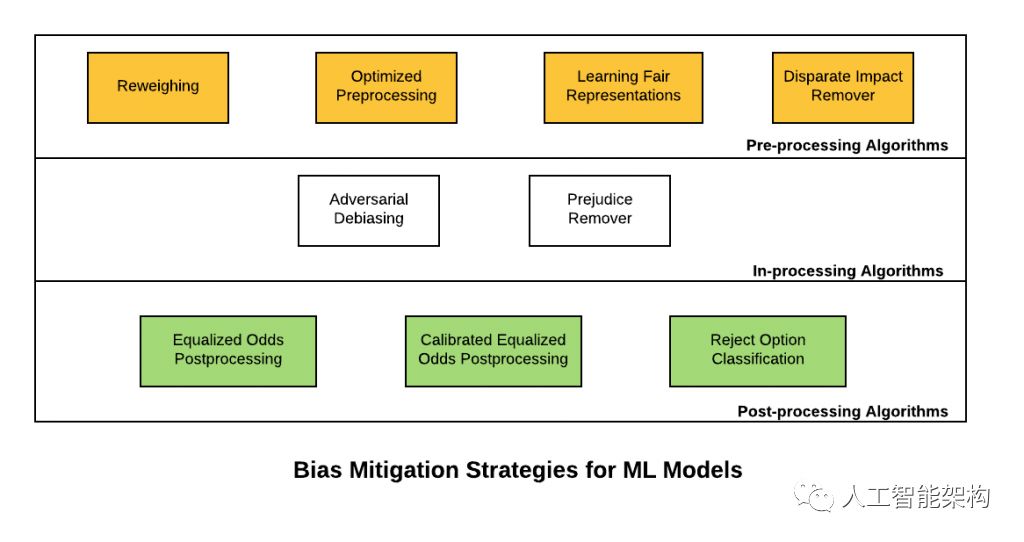
1、预处理算法
预处理算法用于减轻训练数据中普遍存在的偏差。该想法是应用以下技术之一来预处理训练数据集,然后应用分类算法来学习适当的分类器。
Reweighing: 重新加权是一种数据预处理技术,建议为每个(组,标签)组合中的训练样例生成权重,以确保分类前的公平性。我们的想法是将适当的权重应用于训练数据集中的不同元组,以使训练数据集在敏感属性方面免于区分。除了重新称重之外,还可以应用技术(非偏差约束),例如抑制(移除敏感属性)或按数据集 - 修改标签(适当地更改标签以消除对训练数据的偏差)。
Optimized preprocessing: 我们的想法是学习概率转换,利用组公平性,个体失真和数据保真度约束和目标来编辑数据中的特征和标签。
Learning fair representations:我们的想法是找到一个潜在的表示,它可以很好地编码数据,同时模糊有关受保护属性的信息。
Disparate impact remover:对特征值进行适当编辑,以提高组的公平性,同时保持组内的排序。
2、处理(中)算法
Adversarial Debiasing:学习分类器模型以最大化预测准确性,同时降低对手从预测中确定受保护属性的能力。这种方法导致公平的分类器,因为预测不能携带对象可以利用偏差信息。
Prejudice remover: 这个想法是为学习目标增加一个偏差意识的正规化术语。
3、后处理算法
Equalized odds postprocessing: 该算法解决线性程序以找到改变输出标签以优化均衡概率。
Calibrated equalized odds postprocessing:算法优化校准的分类器得分输出,以找到用均衡的目标改变输出标签的概率。
Reject option classification:这个想法是给予无特权群体有利的结果,并对具有最高不确定性的决策边界周围的置信区内的特权群体产生不利结果。
结语
在这篇文章中,使你了解了偏差缓解策略,以构建性能更高的模型,同时确保模型具有较小的判别性。
本文转自:人工智能架构,转载此文目的在于传递更多信息,版权归原作者所有。





