机器学习是当下人工智能浪潮的核心技术,受到了工业界的广泛应用,为社会带来了巨大的产业价值。然而,如果机器学习系统受到攻击,将会带来怎样的严重后果?我们该如何分析、规避这种风险?下面,本文作者将基于 6 个月的研究心得,教给大家破解机器学习系统攻击的正确方式!
机器学习正在让科幻照进现实!但是,任何新的发明(包括机器学习在内)都存在一个很遗憾的事实,那就是新的能力同时也会带来新的安全漏洞,让攻击者有机可趁(相关阅读:https://medium.com/@iljamoisejevs/what-everyone-forgets-about-machine-le...)。
因此,如果你是首席信息安全官(CISO)或者负责安全的产品经理(PM),你应该如何应对这些新的漏洞呢?你的机器学习系统真的会被攻击吗?如果是这样的话,会在何时、以何种方式发生攻击事件呢?
「机器学习安全威胁模型」(ML security threat model )或许是上述问题的解决方案。它是一个结构化的框架,展示了机器学习系统中所有可能存在的威胁向量。
目前,机器学习仍然是一个非常新的技术,人们对其威胁向量仍然知之甚少。然而,在本文中,我们将近最大努力思考这些问题,看看我们是否能够提出一个形式化的框架来思考机器学习安全问题。
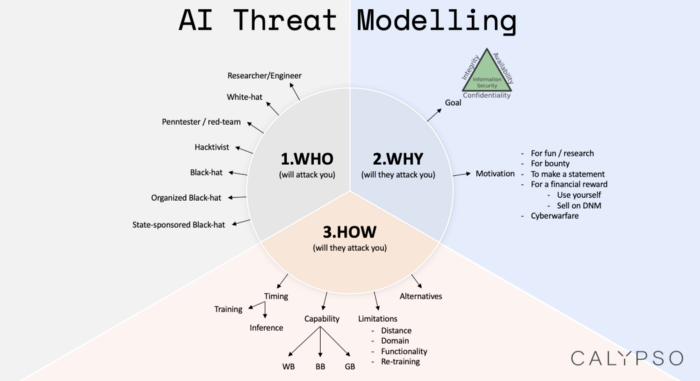
「机器学习安全威胁模型」的组成部分
对于本部位于美国加州洛杉矶的「Calypso」的研究人员来说,当他们考虑威胁模型时,往往会考虑三个组成部分:

1、谁会攻击你?(WHO)
站在我们对立面的攻击者是一切攻击行为的源头。你当然可以直接将他们称为「黑客」,但另一方面,你可以进一步细化一些他们的哪些特征信息从而定义他们呢?也许,将他们称为「深谙机器学习工作机理的黑客」更好,「深谙机器学习工作机理并且具备数学背景的黑客」则又要更为确切。实际上,在「谁会攻击你?」这个问题上,你能刻画出的细节越多越好!
2、他们为什么要攻击你?(WHY)
攻击的原因与攻击者的关系即为密切(这也是我在此一同讨论二者的原因)。「为什么」背后的想法很简单——他们可以「黑」掉你,但他们为什么要这么做呢?这里肯定有他们想要得到的东西,可能是赏金,也可能是其它形式的回报。在这里,我们也需要为攻击原因下个定义,你可以简单地说「他们为什么不攻击我呢?」(这里不推荐这种定义),也可以定义地更复杂些:「违反保密规则,然后将从我的机器学习系统中提取出的数据售卖给另一个实体 X」(这种定义就更好了!)
3、他们将如何攻击你?(HOW)
这部分将涉及到技术问题。既然你已经弄清楚了「谁会攻击你」以及「为什么攻击你」,那么接下来的问题就是「他们将如何攻击你」。当我们讨论机器学习安全时,不妨想想「他们会在训练或进行推断时攻击你的机器学习系统吗?」他们会拥有多少关于你的系统的信息?在思考「他们如何攻击你」这个问题的过程中,想想他们有哪些备选方案是一个十分有趣、但也极具挑战的问题。他们可能可以黑掉你的机器学习系统,但是如果黑掉你的数据管道更加容易,他们会这么做吗?
下面,让我们针对上述三个问题的细节进行展开。
谁会攻击你 + 他们为什么攻击你?
对于「谁会攻击你」的问题,一般来说,我喜欢把对手想象成「严肃认真」的人。在我的脑海中,他们可能是:
1. 聪明的研究人员/工程师在商业机器学习系统上捣乱(可能是为了某项实际研究工作,例如攻击「Clarifai.com」);
2. 参加了某种赏金计划的「白帽子」;
3. 「Penntester/红队人员」在进行网络安全测试;
4. 攻击某个商业机器学习系统来表达诉求的黑客主义者;
5. 攻击某个商业机器学习系统从而获得经济回报(无论是通过实际部署攻击的「战利品」,还是将其在暗网市场上出售)的「黑帽子」;
6. 攻击某个商业机器学习系统的有组织的「黑帽子」团体(例如「Anonymous」、「The Shadow Brokers」、以及「Legion of Doom」);
7. 国家资助的组织(这里主要指网络战);
思考你的对手有多厉害十分重要,因为这定义了他们可能掌握的知识和工具的种类,以及你的防御应该达到的水平。
现在,让我们看看「他们为什么攻击你」。在我看来,该问题可以被分解为下面两个子问题:
1. 他们的目的是什么?
2. 他们的动机是什么?
我想使用「CIA」(Confidentiality,Integrity,Availability)三角来回答「他们的目的是什么」:

保密性、完整性、可用性三大要素是信息安全的三大支柱。如果你能保护这三者,你就保证了信息系统的安全。
1、保密性(或称隐私性)攻击旨在从你的机器学习系统中提取出敏感信息。例如,攻击者可能想要推断某个特定的数据点(例如你)是否是某个特定的训练数据集(例如医院的出院数据);
2、完整性攻击会使你的机器学习模型犯错,而更重要的是,模型会悄悄地这么做。例如,攻击者可能希望你的分类器在整体性能不受影响的情况下将某个恶意文件当成安全文件,这样一来你就不会注意到。在完整性攻击的范畴内,攻击者可能有许多子目标,由难到易分别为:
源/目标误分类(source/target misclassification):攻击者希望特定类别的对象(「恶意的」)被分类为某个其它的特定的类(「安全的」)。
针对性误分类(targeted misclassification):攻击者希望某个特定的类别的对象(「停车」标志)被分类为任意其它的类别(例如,「限速 60 码」、「限速 45 码」、「狗」、「人」或者其它任意「停车」之外的类别)。
误分类(misclassification):把任意类别分类为错误的类别。这就涉及到下面将提到的「可用性攻击」的领域了。
置信度降低(Confidence reduction):攻击者希望你的模型置信度下降(在针对某种阈值(例如欺诈得分)进行攻击时非常有用)。
3、可用性攻击旨在彻底摧毁你的机器学习系统。例如,如果在训练数据池中插入了足够多的「坏」数据,那么你的模型学到的决策边界基本上就是「垃圾」,模型会毫无作用。这就是机器学习世界中的「DOS」(拒绝服务,Denial of Service)攻击。
在弄清攻击者的目的后,紧接着我们需要考虑攻击者的动机。这个问题更加主观,与「谁会攻击你」的关系也更为紧密。如果攻击者被定义为黑客主义团体,那么他们就是试图在发表某种声明;如果攻击者是一个「黑帽子」黑客,那么他可能想要获得经济利益。
他们将如何攻击你?
下面将进入技术部分。攻击者究竟如何才能真正破坏你的模型呢?(在这里,我将重点关注机器学习特有的漏洞,不包括机器学习服务器上的 DDOS 攻击等传统网络安全问题。)
我们可以从四个维度对机器学习系统受到攻击方式进行分类:
1. 时间(训练时/推断时)
2. 能力(白盒/黑盒/灰盒)
3. 局限性(扰动举例/功能/领域/再训练的频率)
4. 替代方案
时间(Timing)
这里指的是机器学习部署的工作流程中攻击发生的位置,大致有以下两种选择:训练时和推断时。

1. 在训练时进行攻击意味着攻击者能够影响训练数据集(威力非常强大,但很难做到,也有额外的限制)。
2. 在推断时进行攻击意味着攻击者只能扰乱即时输入(威力可能很强大,也可能较弱,这取决于具体模型。但更容易执行,因为只需要注入修改后的输入)。
能力(Capability)
这里指的是攻击者对机器学习系统内部架构的了解。具体而言可以分为以下几类:
白盒攻击假设攻击者知晓底层数据的分布(可能访问其中一部分)、模型的架构、使用的优化算法,以及权值和偏置。
黑盒攻击假设攻击者对机器学习系统一无所知(白盒攻击中的要素都不知道)。它们可以被分为两种类型:困难标签(当攻击者只接收来自分类器的预测标签时)和置信度(当攻击者接收来自分类器的预测标签的同时也接收置信度得分)。
灰盒攻击介于白盒攻击和黑盒攻击之间。例如,攻击者可能知道模型的构造如何,但是不清楚底层数据的作用,反之亦然。
你可能在科学文献中也会看到「NoBox」这样的术语。「NoBox」指的是对代理模型的攻击,攻击者基于他们对于目标机器学习系统的理解(尽管有限)重新构建该模型。我认为将其单独分为一类是没有意义的,因为一旦攻击者构建了代理模型,它实际上就变成了一个白盒攻击。
经验法则:攻击者拥有更多的知识对攻击者更有利,对我们更不利(想了解更多,请参阅下面这篇关于「逃逸攻击」(evasion attack)的文章:https://medium.com/@iljamoisejevs/evasion-attacks-on-machine-learning-or...)
局限性(limitation)
它指的是某些限制攻击者行为的规则。这些都是机器学习系统特有的,例如:
在图像中,通常将扰动空间限制在一个「距离」度量的范围内,该度量往往是「L_i,L_1,或 L_2 范数」(参考阅读:https://medium.com/@montjoile/l0-norm-l1-norm-l2-norm-l-infinity-norm-7a...)。顺便说一下,关于这么做是否真的有意义,曾经有过有趣的争论(详情请参阅下面论文「Motivating the Rules of the Game for Adversarial Example Research」:https://arxiv.org/pdf/1807.06732.pdf?source=post_page)。
在恶意软件中,攻击者只能在特定的地方以特定的方式扰乱文件,否则它将失去其恶意功能或破坏所有的文件。
在部署在物理设备(卫星、骑车、无人机、监控摄像头)上的系统中,攻击者可能只能修改物理方面的输入。
要在训练时进行攻击,攻击者需要两个条件得到满足:
(1)系统基于新的数据不断地重新训练(否则攻击者就不能注入「坏」数据)。
(2)系统从外部信息源接收数据,,最好没有人在循环中对其进行认证。
在隐私攻击中,攻击者通常需要一个没有查询限制的公共终端,并输出置信度得分。置信度得分的信息是有限的——例如,大多数杀毒软件智慧告诉你文件是「恶意的」还是「安全的」,并不提供进一步的细节。
备选方案(Alternative)
这是我想要简要介绍的最后一个方面。我曾经听一个在安全领域工作了 25 年的人用「电流」来形容攻击者,因为他们总是选择阻力最小的路径。
这是一个重要的标准(而我发现它经常被忽视),它可以轻易地建立或解除一个威胁模型。攻击机器学习组件实际上是攻击者获得他们想要的东西的最简单的方法吗?如果目标是侵犯隐私,他们会在分类器上构建阴影模型(Shadow model)来提取出数据,还是会有更容易利用的漏洞呢?
总结
至此,本文已经涵盖了大量的内容(实际上是我们过去 6 个月的研究心得),我们来把它们整合一下。
现在,让我们对相关概念进行命名。
在对抗性机器学习(机器学习安全的学术名称)中,通常根据「他们为什么要攻击你」来获取攻击者的目标,并根据「他们将如何攻击你」来命名攻击。最终的结果如下:
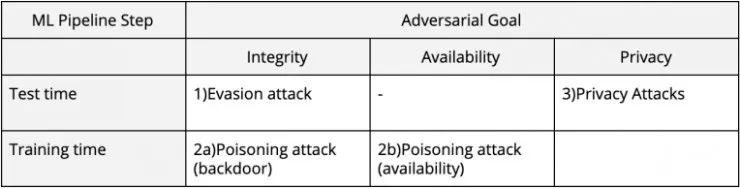
1. 逃逸攻击(也被称为「对抗性样本」)肯定是最流行的攻击类型。它们发生在进行推断时,并且会利用机器学习固有的漏洞(或称「特性」?详情请参阅关于「逃逸攻击」的博文:https://medium.com/@iljamoisejevs/evasion-attacks-on-machine-learning-or...)
2. 下毒攻击发生在训练时,可能针对于两个目标:
(1)完整性
(2)可用性。
攻击者可以在你的训练数据池中插入一些经过精心挑选的示例,然后在其中构建一个「后门」(针对完整性);或者他们可以插入大量「坏」数据,以致于模型的边界基本上失去作用(针对可用性)。
3. 隐私攻击也许是最少被研究的,但这是一类及其相关的威胁,尤其是在今天。在这里,攻击者并不想干扰你及其学习模型工作,而是想从中提取出隐私的、可能敏感的信息。有关隐私漏洞和相关的修复方法的更多内容,请参阅:https://medium.com/@iljamoisejevs/privacy-attacks-on-machine-learning-a1...。
Via https://towardsdatascience.com/will-my-machine-learning-be-attacked-6295...
本文转自:数学与人工智能,转载此文目的在于传递更多信息,版权归原作者所有。





