作者:Utkarsh Desai
编译:AI公园 - ronghuaiyang
导读:生成对抗网络是个好东西,不过训练比较麻烦,这里有一些技巧和陷阱,分享给大家。
生成对抗网络(GANs)是当前深度学习研究的热点之一。过去一段时间,GANs上发表的论文数量有了巨大的增长。GANs已经应用于各种各样的问题。
我读了很多关于GANs的书,但是我自己从来没有玩过。因此,在阅读了一些论文和github repos之后,我决定亲自动手训练一个简单的GAN,但很快就遇到了问题。
本文的目标读者是刚开始学习GANs的深度学习爱好者。除非你非常幸运,否则第一次独自训练GAN可能是一个令人沮丧的过程,可能需要花费数小时才能正确。当然,随着时间的推移,随着经验的积累,你会很好地训练GANs,但是对于初学者来说,可能会出现一些错误,你甚至不知道从哪里开始调试。我想分享我的观察和经验教训,从零开始训练GANs,希望它可能会节省一些人开始调试几个小时的时间。
生成对抗网络
除非你已经断网一年左右了,否则所有参与深度学习的人——甚至一些没有参与深度学习的人——都听说过并谈论过GANs。GANs是一种深度神经网络,是数据的生成模型。这意味着,给定一组训练数据,GANs可以学会估计数据的潜在概率分布。这是非常有用的,因为除了其他事情,我们现在可以从学习到的概率分布中生成样本,这些样本可能不会出现在原始训练集中。
该领域的专家已经提供了一些很棒的资源来解释GANs及其工作原理,所以我不会试图复制他们的工作。但是为了完整起见,这里有一个快速的概述。
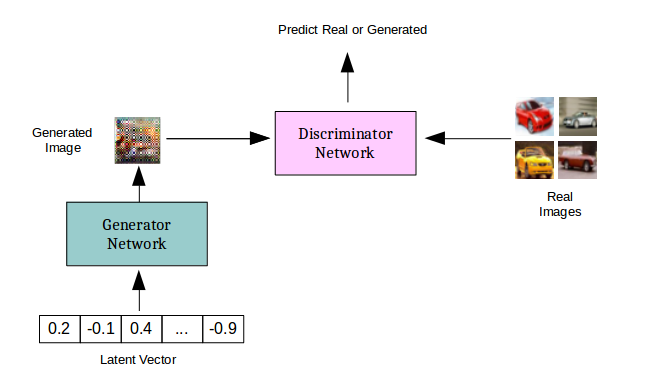
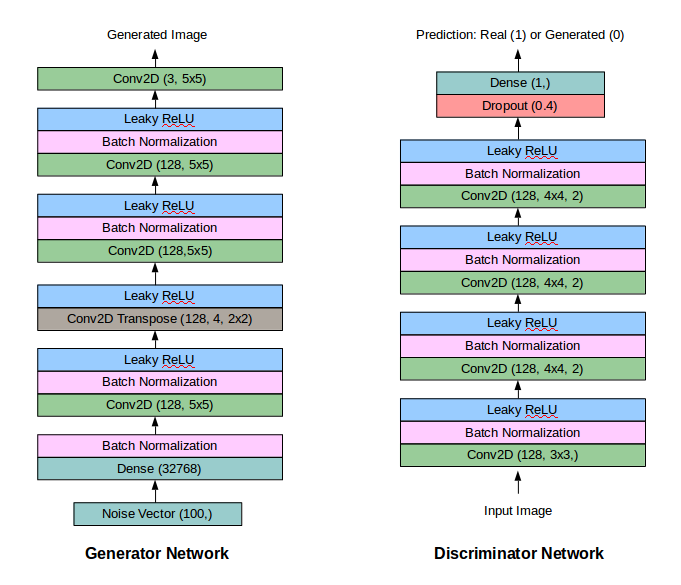
生成对抗网络实际上是两个相互竞争的深层网络。给定一个训练集X(比如说几千张猫的图片),生成网络G(X),使用一个随机向量作为输入,并试图产生与训练集类似的图像。鉴别器网络,D(X),是一个二元分类器,试图区分真正的训练集X中的猫图片和生成器生成的假猫图片。因此,生成器网络的工作就是学习数据在X中的分布情况,从而生成真实的猫图像,并确保识别器不能区分训练集中的猫图像和生成器生成的猫图像。鉴别器需要学习跟上生成器的步伐,因为生成器一直尝试新的技巧来生成假的猫的图像并欺骗鉴别器。
最终,如果一切顺利,生成器(或多或少)就会学习训练数据的真实分布,并变得非常擅长生成真实的猫图像。识别器不再能够区分训练集的猫图像和生成的猫图像。
从这个意义上说,这两个网络不断地试图确保另一个不能很好地完成他们的任务。那么,这到底是怎么回事呢?
另一种观察GAN设置的方法是,鉴别器试图通过告诉生成程序真实的猫图像是什么样子来引导生成器。最终,这台机器发现了这一点,并开始生成真实的猫的图像。GANs的训练方法类似于博弈论中的极大极小算法,这两个网络试图达到所谓的纳什均衡。
GAN训练中的挑战
回到GANs的训练。首先,我使用Keras和Tensorflow后端,在MNIST数据集上训练了一个GAN(准确地说,是DC-GAN)。这并不难,经过对生成器和鉴别器网络的一些小的调整,GAN能够生成MNIST数字的清晰图像。

黑色和白色的数字没那么有趣。物体和人的彩色图像是所有酷家伙玩的东西。这就是事情开始变得棘手的地方。MNIST之后,显然下一步是生成CIFAR-10图像。在日复一日地调整超参数、更改网络架构、添加和删除层之后,我终于能够生成类似CIFAR-10的外观不错的图像。


我从一个相当深的网络开始,最终得到了一个实际有效的、简单得多的网络。当我开始调整网络和训练过程时,15个epochs后生成的图像从现在的样子:

到这样:

最后是这样:

下面是我认识到自己犯过的一些错误,以及我从中学到的一些东西。所以,如果你是GANs的新手,并没有看到在训练方面取得很大的成功,也许看看以下几个方面会有所帮助:
1. 大卷积核和更多的滤波器
更大的卷积核覆盖了前一层图像中的更多像素,因此可以查看更多信息。5x5的核与CIFAR-10配合良好,在鉴别器中使用3x3核使鉴别器损耗迅速趋近于0。对于生成器,你希望在顶层的卷积层有更大的核,以保持某种平滑。在较低的层,我没有看到改变内核大小的任何主要影响。
滤波器的数量可以大量增加参数的数量,但通常需要更多的滤波器。我在几乎所有的卷积层中都使用了128个滤波器。使用较少的滤波器,特别是在生成器中,使得最终生成的图像过于模糊。因此,看起来更多的滤波器可以帮助捕获额外的信息,最终为生成的图像增加清晰度。
2. 标签翻转(Generated=True, Real=False)
虽然一开始看起来很傻,但对我有用的一个主要技巧是更改标签分配。
如果你使用的是Real Images = 1,而生成的图像= 0,则使用另一种方法会有所帮助。正如我们将在后面看到的,这有助于在早期迭代中使用梯度流,并帮助使梯度流动。
3. 使用有噪声的标签和软标签
这在训练鉴别器时是非常重要的。硬标签(1或0)几乎扼杀了早期的所有学习,导致识别器非常快地接近0损失。最后,我使用0到0.1之间的随机数表示0标签(真实图像),使用0.9到1.0之间的随机数表示1标签(生成的图像)。在训练生成器时不需要这样做。
此外,增加一些噪音的训练标签也是有帮助的。对于输入识别器的5%的图像,标签被随机翻转。比如真实的被标记为生成的,生成的被标记为真实的。
4. 使用批归一化是有用的,但是需要有其他的东西也是合适的
批归一化无疑有助于最终的结果。添加批归一化后,生成的图像明显更清晰。但是,如果你错误地设置了卷积核或滤波器,或者识别器的损失很快达到0,添加批归一化可能并不能真正帮助恢复。

5. 每次一个类别
为了更容易地训练GANs,确保输入数据具有相似的特征是很有用的。例如,与其在CIFAR-10的所有10个类中都训练GAN,不如选择一个类(例如,汽车或青蛙)并训练GANs从该类生成图像。DC-GAN的其他变体在学习生成多个类的图像方面做得更好。例如,以类标签为输入,生成基于类标签的图像。但是,如果你从一个普通的DC-GAN开始,最好保持事情简单。
6. 查看梯度
如果可能的话,试着监控梯度以及网络中的损失。这些可以帮助你更好地了解训练的进展,甚至可以帮助你在工作不顺利的情况下进行调试。
理想情况下,生成器应该在训练的早期获得较大的梯度,因为它需要学习如何生成真实的数据。另一方面,鉴别器并不总是在早期获得较大的梯度,因为它可以很容易地区分真假图像。一旦生成器得到足够的训练,鉴别器就很难分辨真假图像。它会不断出错,并得到大的梯度。
我在CIFAR-10汽车上的最初几个GAN版本,有许多卷积和批量规范层,没有标签翻转。除了这个趋势之外,监测梯度的规模也很重要。如果生成器层上的梯度太小,学习可能会很慢,或者根本不会发生。这在GAN的这个版本中是可见的。
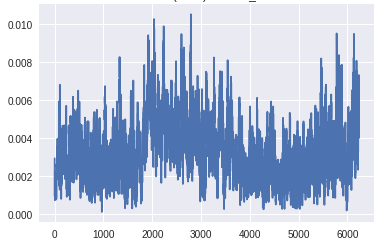

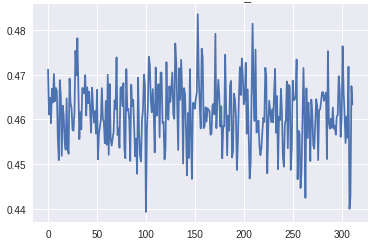
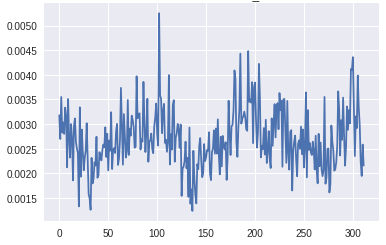
在生成器的最下层梯度的规模太小,任何学习都无法进行。鉴别器的梯度始终是一致的,这表明鉴别器并没有真正学到任何东西。现在,让我们将其与GAN的梯度进行比较,GAN具有上面描述的所有变化,并生成良好的真实图像:
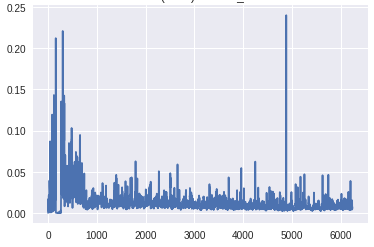
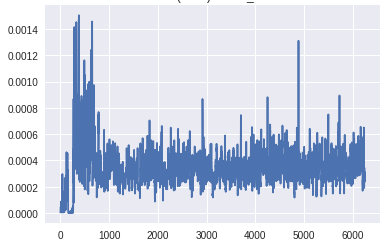
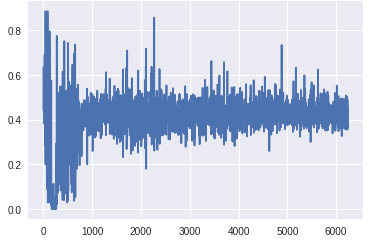
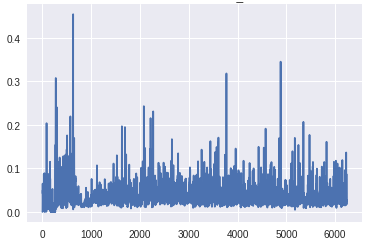
梯度到达生成器底层的比例明显高于前一个版本。此外,随着训练的进展,梯度流与预期一样,随着发生器在早期获得较大的梯度,一旦训练足够,鉴别器在顶层获得一致的高梯度。
7. 不要提前停止
我犯了一个愚蠢的错误——可能是由于我的不耐烦——当我看到损失没有任何明显的进展,或者生成的样本仍然有噪声时,在进行了几百次小批量训练之后,我就终止了训练。比起等到训练结束后才意识到网络什么都没学到,重启工作并节省时间是很诱人的。GANs的训练时间较长,初始损失和生成的样本值很少,几乎从未显示出任何趋势或进展的迹象。在结束训练过程并调整设置之前,等待一段时间是很重要的。
这个规则的一个例外是,如果你看到鉴别器损失迅速接近0。如果发生这种情况,几乎没有恢复的机会,最好重新开始训练,最好对网络或训练过程做一些修改。
最后的GAN是这样工作的:
英文原文:https://medium.com/@utk.is.here/keep-calm-and-train-a-gan-pitfalls-and-t...
本文转自:AI公园(微信号:AI_Paradise),作者:Utkarsh Desai,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。

