在强化学习(三)用动态规划(DP)求解中,我们讨论了用动态规划来求解强化学习预测问题和控制问题的方法。但是由于动态规划法需要在每一次回溯更新某一个状态的价值时,回溯到该状态的所有可能的后续状态。导致对于复杂问题计算量很大。同时很多时候,我们连环境的状态转化模型P都无法知道,这时动态规划法根本没法使用。这时候我们如何求解强化学习问题呢?本文要讨论的蒙特卡罗(Monte-Calo, MC)就是一种可行的方法。
蒙特卡罗法这一篇对应Sutton书的第五章和UCL强化学习课程的第四讲部分,第五讲部分。
1. 不基于模型的强化学习问题定义
在动态规划法中,强化学习的两个问题是这样定义的:
预测问题,即给定强化学习的6个要素:状态集S, 动作集A, 模型状态转化概率矩阵P, 即时奖励R,衰减因子γ, 给定策略π, 求解该策略的状态价值函数v(π)
控制问题,也就是求解最优的价值函数和策略。给定强化学习的5个要素:状态集S, 动作集A, 模型状态转化概率矩阵P, 即时奖励R,衰减因子γ, 求解最优的状态价值函数v∗和最优策略π∗
可见, 模型状态转化概率矩阵P始终是已知的,即MDP已知,对于这样的强化学习问题,我们一般称为基于模型的强化学习问题。
不过有很多强化学习问题,我们没有办法事先得到模型状态转化概率矩阵P,这时如果仍然需要我们求解强化学习问题,那么这就是不基于模型的强化学习问题了。它的两个问题一般的定义是:
预测问题,即给定强化学习的5个要素:状态集S, 动作集A, 即时奖励R,衰减因子γ, 给定策略π, 求解该策略的状态价值函数v(π)
控制问题,也就是求解最优的价值函数和策略。给定强化学习的5个要素:状态集S, 动作集A, 即时奖励R,衰减因子γ, 探索率ϵ, 求解最优的动作价值函数q∗和最优策略π∗
本文要讨论的蒙特卡罗法就是上述不基于模型的强化学习问题。
2. 蒙特卡罗法求解特点
蒙特卡罗是一种通过采样近似求解问题的方法。这里的蒙特卡罗法虽然和MCMC不同,但是采样的思路还是一致的。那么如何采样呢?
蒙特卡罗法通过采样若干经历完整的状态序列(episode)来估计状态的真实价值。所谓的经历完整,就是这个序列必须是达到终点的。比如下棋问题分出输赢,驾车问题成功到达终点或者失败。有了很多组这样经历完整的状态序列,我们就可以来近似的估计状态价值,进而求解预测和控制问题了。
从特卡罗法法的特点来说,一是和动态规划比,它不需要依赖于模型状态转化概率。二是它从经历过的完整序列学习,完整的经历越多,学习效果越好。
3. 蒙特卡罗法求解强化学习预测问题
这里我们先来讨论蒙特卡罗法求解强化学习预测问题的方法,即策略评估。一个给定策略 π 的完整有T个状态的状态序列如下:
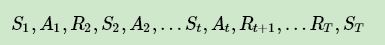
回忆下强化学习(二)马尔科夫决策过程(MDP)中对于价值函数 vπ ( s ) 的定义:
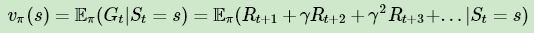
可以看出每个状态的价值函数等于所有该状态收获的期望,同时这个收获是通过后续的奖励与对应的衰减乘积求和得到。那么对于蒙特卡罗法来说,如果要求某一个状态的状态价值,只需要求出所有的完整序列中该状态出现时候的收获再取平均值即可近似求解,也就是:
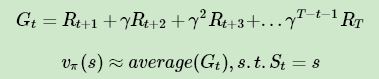
可以看出,预测问题的求解思路还是很简单的。不过有几个点可以优化考虑。
第一个点是同样一个状态可能在一个完整的状态序列中重复出现,那么该状态的收获该如何计算?有两种解决方法。第一种是仅把状态序列中第一次出现该状态时的收获值纳入到收获平均值的计算中;另一种是针对一个状态序列中每次出现的该状态,都计算对应的收获值并纳入到收获平均值的计算中。两种方法对应的蒙特卡罗法分别称为:首次访问(first visit) 和每次访问(every visit) 蒙特卡罗法。第二种方法比第一种的计算量要大一些,但是在完整的经历样本序列少的场景下会比第一种方法适用。
第二个点是累进更新平均值(incremental mean)。在上面预测问题的求解公式里,我们有一个average的公式,意味着要保存所有该状态的收获值之和最后取平均。这样浪费了太多的存储空间。一个较好的方法是在迭代计算收获均值,即每次保存上一轮迭代得到的收获均值与次数,当计算得到当前轮的收获时,即可计算当前轮收获均值和次数。通过下面的公式就很容易理解这个过程:
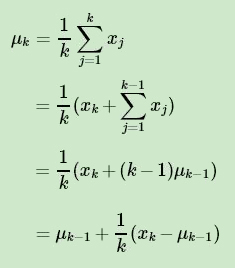
这样上面的状态价值公式就可以改写成:
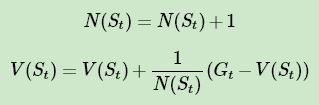
这样我们无论数据量是多还是少,算法需要的内存基本是固定的 。
有时候,尤其是海量数据做分布式迭代的时候,我们可能无法准确计算当前的次数 N( St ) , 这时我们可以用一个系数 α 来代替,即:
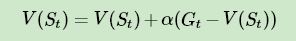
对于动作价值函数 Q ( St , At ) , 也是类似的,比如对上面最后一个式子,动作价值函数版本为:
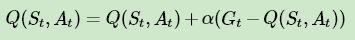
以上就是蒙特卡罗法求解预测问题的整个过程,下面我们来看控制问题求解。
4. 蒙特卡罗法求解强化学习控制问题
蒙特卡罗法求解控制问题的思路和动态规划价值迭代的的思路类似。回忆下动态规划价值迭代的的思路, 每轮迭代先做策略评估,计算出价值 vk( s ) ,然后基于据一定的方法(比如贪婪法)更新当前策略π。最后得到最优价值函数 v∗ 和最优策略 π∗ 。
和动态规划比,蒙特卡罗法不同之处体现在三点:一是预测问题策略评估的方法不同,这个第三节已经讲了。第二是蒙特卡罗法一般是优化最优动作价值函数 q∗ ,而不是状态价值函数 v∗。三是动态规划一般基于贪婪法更新策略。而蒙特卡罗法一般采用 ϵ−贪婪法更新。这个 ϵ 就是我们在 强化学习(一)模型基础 中讲到的第8个模型要素 ϵ。ϵ−贪婪法通过设置一个较小的 ϵ 值,使用 1− ϵ 的概率贪婪地选择目前认为是最大行为价值的行为,而用ϵ 的概率随机的从所有 m 个可选行为中选择行为。用公式可以表示为:
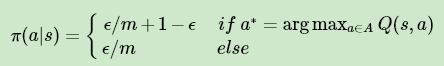
在实际求解控制问题时,为了使算法可以收敛,一般ϵ会随着算法的迭代过程逐渐减小,并趋于0。这样在迭代前期,我们鼓励探索,而在后期,由于我们有了足够的探索量,开始趋于保守,以贪婪为主,使算法可以稳定收敛。这样我们可以得到一张和动态规划类似的图:
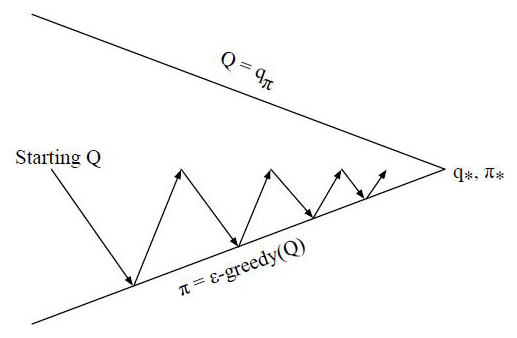
5. 蒙特卡罗法控制问题算法流程
在这里总结下蒙特卡罗法求解强化学习控制问题的算法流程,这里的算法是在线(on-policy)版本的,相对的算法还有离线(off-policy)版本的。在线和离线的区别我们在后续的文章里面会讲。同时这里我们用的是every-visit,即个状态序列中每次出现的相同状态,都会计算对应的收获值。
在线蒙特卡罗法求解强化学习控制问题的算法流程如下:
输入:状态集 S , 动作集 A , 即时奖励 R ,衰减因子 γ , 探索率 ϵ
输出:最优的动作价值函数 q∗和最优策略 π∗
1. 初始化所有的动作价值 Q( s , a ) = 0, 状态次数 N ( s , a ) = 0,采样次数 k = 0,随机初始化一个策略 π
2. k = k + 1 , 基于策略 π 进行第 k 次蒙特卡罗采样,得到一个完整的状态序列:
3. 对于该状态序列里出现的每一状态行为对 ( St , At ) ,计算其收获 Gt , 更新其计数 N ( s , a ) 和行为价值函数 Q ( s , a ):
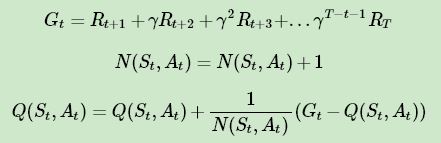
4. 基于新计算出的动作价值,更新当前的ϵ−贪婪策略:
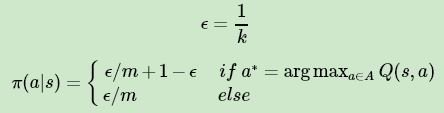
5. 如果所有的Q(s,a)收敛,则对应的所有Q(s,a)即为最优的动作价值函数q∗。对应的策略π(a|s)即为最优策略π∗。否则转到第二步。
6. 蒙特卡罗法求解强化学习问题小结
蒙特卡罗法是我们第二个讲到的求解强化问题的方法,也是第一个不基于模型的强化问题求解方法。它可以避免动态规划求解过于复杂,同时还可以不事先知道环境转化模型,因此可以用于海量数据和复杂模型。但是它也有自己的缺点,这就是它每次采样都需要一个完整的状态序列。如果我们没有完整的状态序列,或者很难拿到较多的完整的状态序列,这时候蒙特卡罗法就不太好用了, 也就是说,我们还需要寻找其他的更灵活的不基于模型的强化问题求解方法。
下一篇我们讨论用时序差分方法来求解强化学习预测和控制问题的方法。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
本文转自:博客园 - 刘建平Pinard(https://www.cnblogs.com/pinard/),转载此文目的在于传递更多信息,版权归原作者所有。





