来源:bigdata-madesimple
编译:T.R
当我们在探究人工智能和机器学习背后的概念和算法时会接触到一系列与这一领域相关的专业术语和核心概念。理解这些术语和概念有助于我们更好的把握这里领域的发展,并理解数据科学家和AI研究人员们是如何引领时代发展的。
在这篇文章中,我们将帮助你更好的理解监督学习、非监督学习和强化学习的定义的内涵,并从更广阔的视角中阐述它们与机器学习之间的联系。深入理解它们的内涵不仅有助于你在这一领域的文献中尽情的徜徉,更能引导你敏锐地捕捉到AI领域的发展和技术进步的气息。
监督学习、非监督学习和强化学习描述了机器处理和利用数据学习的三种不同手段,根据不同的数据和任务人们采用不同的学习方式来从数据中凝练出知识,从而在生产生活中帮助人类。
监督学习
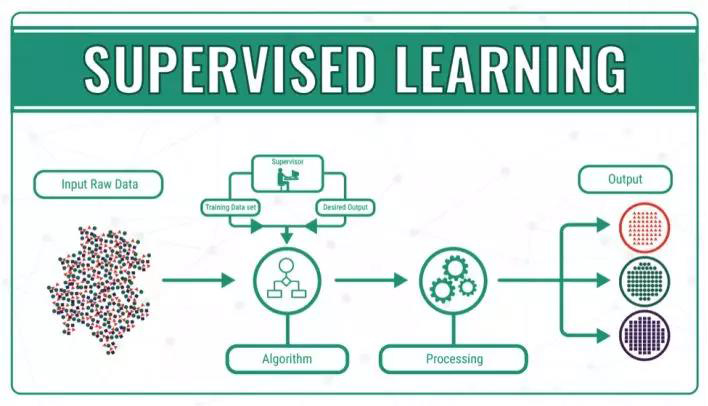
为了让更多的朋友理解机器学习的核心概念,我们首先给出简明监督学习简明扼要的定义:在知道输入和输出的情况下训练出一个模型,将输入映射到输出。我们在开始训练之前就已经知道了输入和输入,我们的任务时建立起一个将输入准确映射到输出的模型,当给模型输入新的值时就能预测出对应的输出了。
在这一过程中机器不断的通过训练输入来指导算法不断改进。如果输出的结果不正确,那么这个错误结果与期望正确结果之间的误差将作为纠正信号传回到模型,纠正模型的改进。在深度学习中著名的反向传播算法根本上也是将误差向后传播来指导模型改进的。
目前监督学习占据了机器学习算法的绝大部分,通过算法将输入变量x和输出变量y衔接起来创造了很多具有深远影响的应用。要理解监督学习我们需要把握住以下几点,在监督学习中所有的算法、输入、输出以及场景都是人类提供的。将监督学习问题分为两类将更好地帮助我们理解监督学习地含义。
分类:分类问题的目标是通过输入变量预测出这一样本所属的类别,例如对于植物品种、客户年龄和偏好的预测问题都可以被归结为分类问题。这一领域中使用最多的模型便是支持向量机,用于生成线性分类的决策边界。随着深度学习的发展,很多基于图像信号的分类问题越来越多的使用卷积神经网络来完成。
回归:主要用于预测某一变量的实数取值,其输出的不是分类结果而是一个实际的值。最常见的例子便是市场价格预测,降水量预测等问题。人们主要通过线性回归、多项式回归以及核方法等来构建回归模型。
非监督学习

在了解了监督学习后我们再来看看非监督学习法,这种方法的使用不如监督学习广泛,目前的实际应用也不如监督学习那般普遍。但这种独特的方法论为机器学习未来的发展方向给出了很多启发和可能性。也许非监督学习可以让我们从“教会机器去做什么”发展到让机器“自己学会去做什么”。
与监督学习不同,非监督学习并不需要完整的输入输出数据集,并且系统的输出经常是不确定的。它主要被用于探索数据中隐含的模式和分布。非监督学习具有解读数据并从中寻求解决方案的能力,通过将数据和算法输入到机器中将能发现一些用其他方法无法见到的模式和信息。
让我们用一个简单的例子来理解非监督学习。设想我们有一批照片其中包含着不同颜色的几何形状。在这里计算机面对的是没有任何标记的图片,它并不知道几何形状的颜色和外形,它看到的只是一张张照片而已。但通过将数据输入到非监督学习的模型中去,算法可以尝试着理解图中的内容,通过相关性和特征将图中的相似的物体聚为一类。在理想的情况下它可以将不同形状不同颜色的几何形状聚集到不同的类别中去,特征提取和标签都是机器自己完成的。
但就像人类学习一样,机器也会犯错。而机器的能力可以通过识别错误、并从错误中学习而不断提高改善。
强化学习

强化学习是机器学习的重要部分,在为机器学习开拓新方向上做出了巨大的贡献。强化学习突破了非监督学习,为机器和软件如何获取最优化的结果给出了一种全新的思路。它将如何最优化主体的表现和如何优化这一能力之间建立起了强有力的链接。通过奖励函数的反馈来帮助机器改进自身的行为和算法。
但强化学习在实践中并不简单,人们利用很多种算法来实现强化学习。简单来说,强化学习需要指导机器做出在当前状态下能获取最好结果的行为。
强化学习中主体通过行为与环境相互作用,而环境通过奖励函数来帮助算法调整做出行为决策的策略函数。从而在不断的循环中得到表现优异的行为策略。它十分适合用于训练控制算法和游戏AI等场景。
最后在了解和这三者的概念后让我们来讨论监督学习、非监督学习和强化学习的异同点:
1. 监督学习 v.s 强化学习
在监督学习中对应的输入输出数据扮演了监督的角色,将其中蕴含的知识通过训练赋予模型,模型通过数据的纠正信号不断学习最终形成能较好理解数据并准确预测的算法。而在强化学习中监督数据并不是必须的,主体可以通过与环境相互作用尝试很多方法和表现并调节。我们可以想象围棋的例子,在最终胜负揭晓之前我们需要执行很多次操作,每一次操作都有很多种可能,为这一任务建立监督学习的知识是十分复杂的工作。而电脑则可以根据与环境相互作用后收到的反馈建立起自己对于棋局的理解。
当机器开始学习后她便可以不断地充实自己的经验并改善表现。这也许是与监督学习最大的不同了。虽然两种模型都建立了某种输入到输出的映射关系,但强化学习却是通过奖励函数来帮助系统不断改进模型的。
2. 强化学习 v.s 非监督学习
强化学习根本上来说是通过映射结构来对输入和输入进行衔接,但非监督学习则在输入和输出之间没有任何的链接。在非监督学习中,机器的主要任务是对数据种的模式进行识别而不是建立映射关系。如果我们想要建立一个用户新闻推荐系统,强化学习可以通过用户的使用反馈不断改进,并建立起用户喜欢的新闻类型图谱实现更精准的推荐。而对于非监督学习来说,则能从用户读过的文章种总结出用户的喜好,并为用户推荐合适的主题。
本文转自: 将门创投 ,转载此文目的在于传递更多信息,版权归原作者所有。





