正确率(Accuracy)
我们知道,机器学习的一大任务是”分类”。我们构建了一个分类模型,通过训练集训练好后,那么这个分类模型到底预测效果怎么样呢?那就需要进行评估验证。
评估验证当然是在测试集上。问题是,我通过什么评估这个分类模型呢?也就是说我们怎么给这个模型打分呢?
想想我们上学时的考试,总分100分,总共100道题,作对1题给1分,最后会有一个得分,例如80分,90分,换算成百分比就是80%,90%,这是我们自然而然能想到的评估方法。在测试集上,假定有10000个样本数据,这个模型进行正确分类的样本数据是9000个,其它1000个都分错了,那么得分就是9000/10000=90%。
这种很简单很直观的评估方法就是正确率(Accuracy)。在一般情况下,这种方式就很好了,注意:正确率(Accuracy)也经常翻译成准确率。
但是在很多情况下,这种方式就不那么好了。例如考试中的100道题,不是每道题都是1分,而是前90道题是选择题,每题1分,后10道题是应用题,每题20分。A同学答对了前80道题,B同学答对了后80道题,按照答对题的数量,都是80道题,正确率都是80%。但是,后面的题更重要,B同学理应比A同学得分更高。
要知道我们的试卷就是这么设计的,也就是说有些题比其它题更重要,比如应用题就比选择题重要。同样,在数据样本中,有些数据样本就是比其它数据样本更重要。
例如:地震局的地壳活动数据,100万个测试数据样本中,只有10个是有地震的,另外的999990个数据是没有地震的.如果我们的分类模型预测对了这999990个没有地震的数据,另外10个有地震的都预测错了,那么按照正确率(Accuracy)的计算,得分仍然高达99.999%,这显然是离谱的评估。
再例如:医院的肺癌检查数据,10万个测试数据样本中,只有100个是有癌症的;信用卡交易数据中,1亿个测试数据样本,只有1万个是欺诈交易;像预测地震、癌症、欺诈交易写等等这些例子可是我们机器学习领域经常遇到的状况。
因此,正确率(Accuracy)虽然简单直观,但在很多时候并不是一个真正正确的评估指标。
精确率
除了正确率(Accuracy),还有什么评估方法呢?我们还是举地震、癌症、信用卡交易欺诈的例子,在这些情况下,我们显然关心的是有没有地震,有没有癌症,有没有欺诈交易。如果有地震、有癌症、有欺诈,竟然预测错了,这显然是非常严重的后果。
那么,要怎样评估计算呢?这里就要引出”阴阳“的概念,我们做体检时,经常会出现有阳性、阴性的检查结果。什么意思呢?检查出“阳性”一般代表就有异常结果,例如可能得了某病,或者怀孕等。“阴性”就代表正常结果,我们当然关心异常结果,也就是”阳性”的结果。
当然,检查出“阳性”,并不代表真有某种疾病,这称为“假阳”;同理,检查出“阴性”,也并不代表没有某种疾病,这称为”假阴“。
这里把”阳性/阴性“从疾病检查中引申出来,把我们关心的异常结果,例如地震、欺诈交易等都称为”阳性“,同理,正常的结果没有地震、没有欺诈交易都称为”阴性”。
那么,对于分类模型对测试集中每条数据样本的预测,排列组合下,就只有4种可能性:
1. 原本是阳性,预测成阳性:真阳 2. 原本是阳性,预测成阴性:假阴 3. 原本是阴性,预测成阳性:假阳 4. 原本是阴性,预测成阴性:真阴
怎么样,是不是感觉都有点像武功秘籍《九阳真经》、《九阴真经》了。
前面说过,我们关注的是异常结果,即”阳性“,如果检查出的”阳性”都是真阳,没有”假阳”当然是好的。所以,我们用下式来评估模型的好坏:

这就是精确率(Precision)评估方法。
举个例子,地震局的地壳活动数据,100万个测试数据样本中,只有10个是有地震的,另外的999990个数据是没有地震的,如果我们的分类模型预测对了这999990个没有地震的数据中的999900个;另外10个有地震的预测对了6个。
那么真阳=6,真阴=999900,假阳=90.假阴=4。

这个得分就很低了。如果按照”正确率/准确率(Accuracy)“来计算,就是(999900+6)/1000000=99.9906%。
因为我们更关心有地震的情况,所以,采用精确率(precision)的计算方法显然更合适。
精确率(Precision)还有一个名称,叫查准率。但是注意,查准率这个名称主要用在信息检索领域。例如一个论文数据库,搜索”机器学习”相关论文,搜出来的文档数量为10000条,其中真正与”机器学习“相关的文档数量为9000条,那么查准率就是90%。
实际应用中,大家经常把正确率、准确率、精确率、查准率等混在一起,不同人说的都不是同一个东西。因此,建议使用英文原文来表达更清晰,即Accuracy和Precision。
召回率
上面介绍了正确率(Accuracy)和精确率(Precision)的评估方法。其中指出了正确率(Accuracy)虽然简单直观,但在很多时候并不是一个真正正确的评估指标。
那么精确率(Precision)可能会有什么问题呢?我们还是看看它的计算公式:
如果“假阳=0”,那么精确率就是100%,这很好,但有什么问题呢?
举个例子:癌症检查数据样本有10000个,其中10个数据样本是有癌症,其它是无癌症。分类模型在无癌症数据中全都预测正确,在10个癌症数据中预测正确了1个,此时真阳=1,真阴=9990,假阳=0,假阴=9。根据精确率的计算公式:

显然,这是不合理的。
因为”精确率“并没有考虑到”假阴“的问题,即它只关心查出来的”癌症”有多少是”真癌症”,至于是癌症但没査出来的,认为不是“癌症的”即”假阴“它管不着。但是,我们癌症检查的时候,有癌症却查出来”不是癌症“,这是非常要命的。
所以考虑这种情况,那么就需要用到召回率(Recall),其计算公式为:

上面癌症例子中,召回率的值为:

即从召回率数值看,这个分类模型是不好的。
还是上面的例子:假设分类模型在无癌症数据9990中预测正确了9980个,在10个癌症数据中预测正确了10个。此时真阳=10,真阴=9980,假阳=10,假阴=0。则其精确度为10/(10+10)=50%,而召回率为10/(10+0)=100%。即精确度虽然不高,谎报了几个癌症,但是所有的真癌症都没有错过,这是非常重要的。
所以,各种分类评估指标各有优缺点,我们具体采用什么指标来评估分类模型,关键还是看我们的具体应用。如果是地震、癌症、欺诈交易等,我们宁愿有误报,但不能错过一个,这时就主要看召回率。如果是文档搜索,我们并不关心搜的全不全,搜出来的都是我们想要的信息就够了,那么就主要看精确率。
召回率(Recall)还有一个名称,叫查全率。但是注意,查全率这个名称主要用在信息检索领域.例如一个论文数据库,搜索”加器学习”相关论文,总共有100万篇论文,其中与机器学习相关的论文有2万篇,搜出来的文档数量为1万篇,其中真正与”机器学习”相关的文档数量为9000篇,那么查全率就是9000/(9000+(20000-9000))=45%
F分数(F-Score)
前面介绍了机器学习中分类模型的精确率(Precision)和召回率(Recall)评估指标。对于Precision和Recall,虽然从计算公式来看,并没有什么必然的相关性关系,但是,在大规模数据集合中,这2个指标往往是相互制约的。理想情况下做到两个指标都高当然最好,但一般情况下,Precision高,Recall就低,Recall高,Precision就低。所以在实际中常常需要根据具体情况做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。而像癌症检测、地震检测、金融欺诈等,则在保证精确率的条件下,尽量提升召回率。
所以,很多时候我们需要综合权衡这2个指标,这就引出了一个新的指标F-score。这是综合考虑Precision和Recall的调和值。
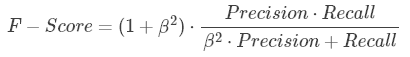
当β=1β=1时,称为F1-score,这时,精确率和召回率都很重要,权重相同。当有些情况下,我们认为精确率更重要些,那就调整ββ的值小于1,如果我们认为召回率更重要些,那就调整ββ的值大于1。
举个例子:癌症检查数据样本有10000个,其中10个数据祥本是有癌症,其它是无癌症。假设分类模型在无癌症数据9990中预测正确了9980个,在10个癌症数据中预测正确了9个,此时真阳=9,真阴=9980,假阳=10,假阴=1。
那么:
Accuracy = (9+9980) /10000=99.89%
Precision=9/19+10)= 47.36%
F1-score=2×(47.36% × 90%)/(1×47.36%+90%)=62.07%
F2-score=5× (47.36% × 90%)/(4×47.36%+90%)=76. 27%
来源:CSDN,作者:saltriver,转载此文目的在于传递更多信息,版权归原作者所有。
原文:
https://blog.csdn.net/saltriver/article/details/73928282
https://blog.csdn.net/saltriver/article/details/73928452
https://blog.csdn.net/saltriver/article/details/74012075
https://blog.csdn.net/saltriver/article/details/74012163
版权声明:本文为博主原创文章,转载请附上博文链接!





