1. EM算法要解决的问题
我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。
但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。怎么办呢?这就是EM算法可以派上用场的地方了。
EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。不过没关系,我们基于当前得到的模型参数,继续猜测隐含数据(EM算法的E步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
从上面的描述可以看出,EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
一个最直观了解EM算法思路的是K-Means算法,见之前写的K-Means聚类算法原理。在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
当然,K-Means算法是比较简单的,实际中的问题往往没有这么简单。上面对EM算法的描述还很粗糙,我们需要用数学的语言精准描述。
2. EM算法的推导
对于 m 个样本观察数据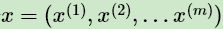 中,找出样本的模型参数θ, 极大化模型分布的对数似然函数如下:
中,找出样本的模型参数θ, 极大化模型分布的对数似然函数如下:
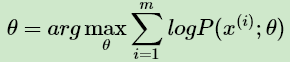
如果我们得到的观察数据有未观察到的隐含数据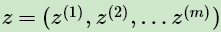 此时我们的极大化模型分布的对数似然函数如下:
此时我们的极大化模型分布的对数似然函数如下:
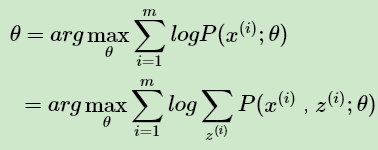
上面这个式子是没有 办法直接求出θ的。因此需要一些特殊的技巧,我们首先对这个式子进行缩放如下:
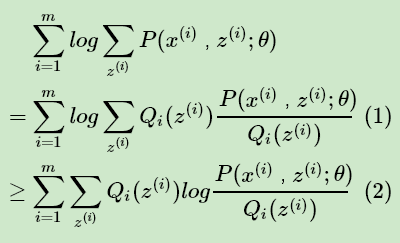
上面第(1)式引入了一个未知的新的分布 Qi(z(i)) ,第(2)式用到了Jensen不等式:
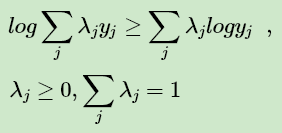
或者说由于对数函数是凹函数,所以有:

此时如果要满足Jensen不等式的等号,则有:
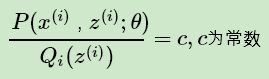
由于 Qi(z(i)) 是一个分布,所以满足:

从上面两式,我们可以得到:
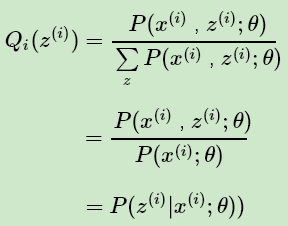
如果 则第(2)式是我们的包含隐藏数据的对数似然的一个下界。如果我们能极大化这个下界,则也在尝试极大化我们的对数似然。即我们需要最大化下式:
则第(2)式是我们的包含隐藏数据的对数似然的一个下界。如果我们能极大化这个下界,则也在尝试极大化我们的对数似然。即我们需要最大化下式:

去掉上式中为常数的部分,则我们需要极大化的对数似然下界为:
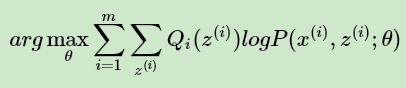
上式也就是我们的EM算法的M步,那E步呢?注意到上式中 Qi(z(i)) 是一个分布,因此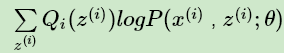 可以理解为logP( x(i),z(i) ; θ ) 基于条件概率分布 Qi(z(i)) 的期望。
可以理解为logP( x(i),z(i) ; θ ) 基于条件概率分布 Qi(z(i)) 的期望。
至此,我们理解了EM算法中E步和M步的具体数学含义。
3. EM算法流程
现在我们总结下EM算法的流程。
输入:观察数据 x = ( x(1) , x(2) , ... x(m) ),联合分布 p( x , z ; θ ), 条件分布 p( z | x ; θ ), 最大迭代次数 J。
1) 随机初始化模型参数θ的初值 θ0 。
2)for j from 1 to J开始EM算法迭代:
a) E步:计算联合分布的条件概率期望:

b) M步:极大化 L( θ , θj ),得到 θj+1:
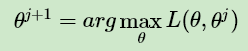
c) 如果 θj+1 已收敛,则算法结束。否则继续回到步骤a)进行E步迭代。
输出:模型参数θ。
4. EM算法的收敛性思考
EM算法的流程并不复杂,但是还有两个问题需要我们思考:
1) EM算法能保证收敛吗?
2) EM算法如果收敛,那么能保证收敛到全局最大值吗?
首先我们来看第一个问题, EM算法的收敛性。要证明EM算法收敛,则我们需要证明我们的对数似然函数的值在迭代的过程中一直在增大。即:
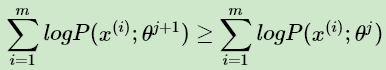
由于
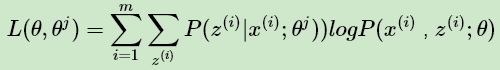
令:
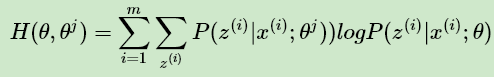
上两式相减得到:
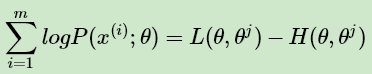
在上式中分别取 θ为 θj 和 θj+1,并相减得到:

要证明EM算法的收敛性,我们只需要证明上式的右边是非负的即可。
由于 θj+1使得 L( θ , θj ) 极大,因此有:

而对于第二部分,我们有:
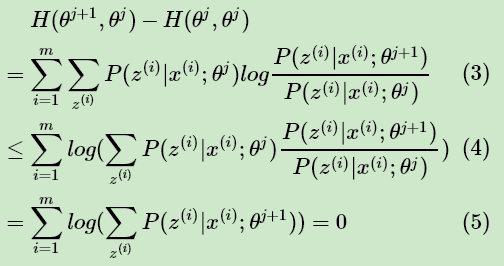
其中第(4)式用到了Jensen不等式,只不过和第二节的使用相反而已,第(5)式用到了概率分布累积为1的性质。
至此,我们得到了: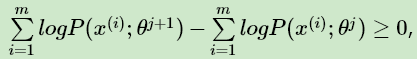 , 证明了EM算法的收敛性。
, 证明了EM算法的收敛性。
从上面的推导可以看出,EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值点,因此它是局部最优的算法,当然,如果我们的优化目标 L( θ , θj )是凸的,则EM算法可以保证收敛到全局最大值,这点和梯度下降法这样的迭代算法相同。至此我们也回答了上面提到的第二个问题。
5. EM算法的一些思考
如果我们从算法思想的角度来思考EM算法,我们可以发现我们的算法里已知的是观察数据,未知的是隐含数据和模型参数,在E步,我们所做的事情是固定模型参数的值,优化隐含数据的分布,而在M步,我们所做的事情是固定隐含数据分布,优化模型参数的值。比较下其他的机器学习算法,其实很多算法都有类似的思想。比如SMO算法(支持向量机原理(四)SMO算法原理),坐标轴下降法(Lasso回归算法: 坐标轴下降法与最小角回归法小结),都使用了类似的思想来求解问题。
大家也可以去比较下这些算法的优化方法,看思路上是不是有共同之处。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
本文转自:博客园 - 刘建平Pinard,转载此文目的在于传递更多信息,版权归原作者所有。





