这种技术和法线贴图结合使用,可以给物体表面增加惊人的细节,这边只谈实现上的注意点。
首先是最简单的一种,一般不会采用的那种,但用来理解最核心的思想是极好的。
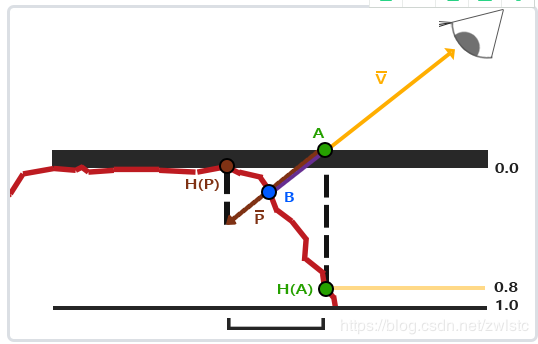
(视差映射在实现时,通常采用的是深度图而非高度图,储存的信息是当前像素凹下去的程度)
如图所示,A点即是当前片元着色器正在处理的片元位置。如果不应用任何视差映射技术,则此时应该用A的uv值去相关贴图里采样。但,现在为了体现这个点的位置凹下去了,则我们实际应该用B点的uv去采样。
这就是视差映射要做的全部,根据A点的深度和相关已知的信息,求出B点的uv。
最简单的方式,就是最直观的方式,直接在v的方向上以A为起点,用A点的深度值长度去偏移(采样到的深度值可以再除以z来根据视线和法线的夹角拉长这个值,这样可以避免一些奇怪的问题,但这不是重点),然后用p`的xy值当作uv的偏移值就能求出一个近似的结果,图中深红色的点。这个实现方式,很明显有很大的漏洞,只能在起伏比较平缓的表面才有好的效果。
在讲下一种实现方式前,还有一个问题要说明。为什么p`的xy值能当作uv偏移直接使用? 在世界坐标系下,这只在平面是平的时候有效,一但平面有所旋转,明显就是不对的。所以这些计算都需要在切线空间下进行,这样p`的xy永远和uv坐标轴对齐。(所以在顶点着色器中,你需要提前准备好所有在切线空间下的数据)
第二种方式被称为 陡峭视差映射 Steep Parallax Mapping
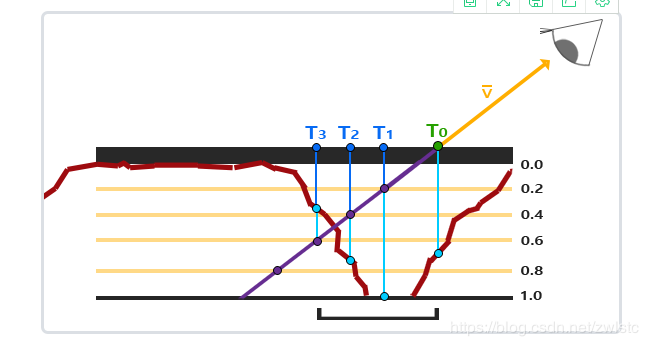
首先提前定义好将要分的层数,层数越高,精度越高。
他采用的方法是,从T0点开始 一次只移动一层深度对应的偏移值,直到某一次采样到的深度值比当前层数的深度值低(一个在紫点上的蓝点),此时,这个点就被当作迭代最终的结果。
精度完全取决于你分了多少层,但还是有一个方法可以优化,通常只有在视线和平面角度很小的时候才需要很高的层数精度。
所以可以用视线和T0法线(0,0,1)的夹角cos值来调整层数的多少。
第三种方法,叫视差遮蔽映射 Parallax Occlusion mapping
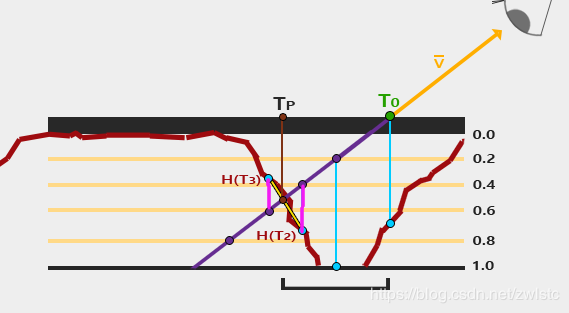
和第二种方法类似,区别在于,这种方法在得到最后的迭代结果时,会和上一步的结果做差值。
差值的权重通过图中两段粉色的线段的比值就可以计算出来。
很明显,这个方法得到的结果是最精确的
来源:CSDN,作者:zwlstc,转载此文目的在于传递更多信息,版权归原作者所有。
原文:https://blog.csdn.net/zwlstc/article/details/86600762





