我们发展人工智能,核心目的是为了用人工智能来解决我们日常工作生活中的各种问题,机器学习当然也不例外。那机器学习适合解决哪些问题呢?
首先,我们一定要知道,机器学习不是万能的。你要问机器学习能不能解决光速星际旅行,能不能造出飞碟、宇宙飞船、火箭,我肯定的说不能。你要问机器学习能不能预测房价、股市的涨跌,我只能说可能行,但非常难实现。因为涉及因素太多,训练出来的模型不可能精确。
其次,我们要认识到日常工作生活中的最大任务是“决策”。不管是商业上的决策,上不上这个产品,投不投这个项目,要不要加大营销力度。还是工作生活中的决策,上哪个大学,学什么专业,买不买房,上哪吃饭,看不看电影等等。我们无时无刻不在做着“决策”。
最后,“决策”背后的本质是“分类”。这些房子好,那些房子差,这个电影好看,那个不好看,这个餐馆好吃,那个餐馆不好吃。有了“分类”,是不是决策起来就容易的多,而我们“决策”的过程本质上就是一个“分类”的过程。
所以,机器学习的主要任务就是分类。
我们以前介绍过,机器学习就是让计算机学会利用过往的经验完成指定任务。我们的目的是完成指定任务。但当时我们对指定任务是什么并没有说明。
这个指定任务一般分为3类:分类,聚类,回归。也就是说机器学习的任务就是完成这3类指定任务,其中分类是核心。
我们知道,开展机器学习有个前提:必须有过往的经验,或者说有过往的数据。这个数据的集合叫数据集。数据集的一般形式是:
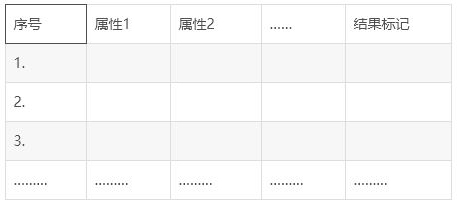
注意这个结果标记。如果结果标记是类别数据,那么机器学习的主要任务就是分类。如果是结果标记是数值数据,那么机器学习的主要任务就是回归。如果没有结果标记,而是需要将数据集分成不同的类别,那么机器学习的主要任务就是聚类。
举个鸟物种例子:
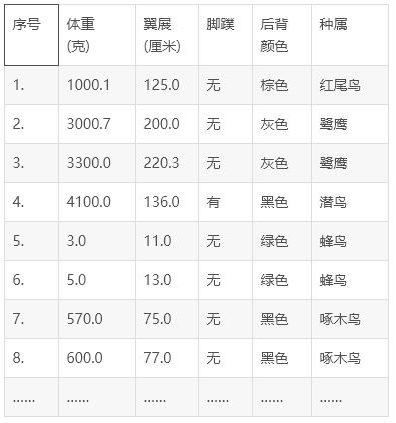
这个数据集的结果标记是红尾鸟、蜂鸟、啄木鸟等,属于类别数据。如果我们找到一种鸟,测量其体重、翼展、脚蹼、后背颜色4个属性数据,例如是550克,74cm,无,黑色,通过机器学习就可以判定这种鸟属于啄木鸟。
像这样的机器学习任务就是“分类”。
我们再看个一个北京二手房的例子:

这个数据集的结果标记690万元、440万元等属于数值数据。如果我们要买一套二手房,希望了解其大致价格,通过面积、区域、学区、装修4个属性数据,通过机器学习就可以预测这个二手房的价格是多少,这个任务就是“回归”。
至于为什么叫“回归”,这个是舶来词,是英文“regression”翻译过来的。翻译词的特点是带有原词的主要含义,但与原词表达的意思又不完全一样,甚至从中文字面上难以理解,例如大家最熟悉的函数,就是function的翻译词,在我们中学刚学“函数”这个词时,其含义并不是那么显而易见的。回归(regression)也一样,不好直白理解。简单化理解就像“地理上的回归线”一样,“回去归来,回归于事物的本来面目”。
也不用太纠结,在机器学习中,你记住以后看到需要预测出来的结果标记为数值型的,例如房价,体重,股票价格等,也就是与“实数”相关的,就叫做“回归”。
对于“聚类”,用个比较形象的词语就是“人以类聚,物以群分”。聚类不是用来做预测的,而是对事物进行“分门别类”的。例如前面那个鸟物种的例子,你现在是鸟类专家,抓住了1000只鸟,你根据这些鸟的特征,对这些鸟分别进行观察,长的很像的就聚为一类,例如有长嘴巴的就聚为啄木鸟类,有红尾巴的就聚为红尾鸟类。你办公室里有30名同事,你爱好抽烟,你根据观察和测试,逐渐把这30人聚成了抽烟和不抽烟的2类,于是工间休息期间你就知道找抽烟的那一类人。当然,你还可以把这30人聚成抽烟的、偶尔抽一下的、完全不抽的3类人。你还可以根据打羽毛球把30名同事分成会打的、不会打的2类,或者很会打的,一般的,完全不会的3类。也就是说聚类的个数和每个类别的内容是不定的,根据你的实际需要确定。
来源:CSDN,作者:saltriver,转载此文目的在于传递更多信息,版权归原作者所有。
原文链接:https://blog.csdn.net/saltriver/article/details/70187876





