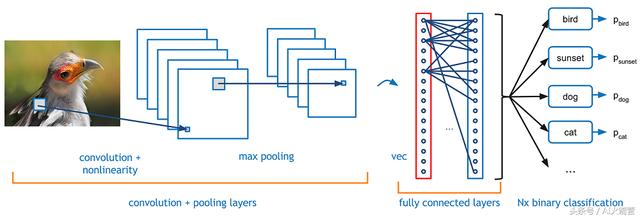
本文探讨卷积神经网络(CNN)的内部工作原理。你可能想知道这些网络中发生了什么?他们是如何学习的?
我们在猫狗图像数据集上训练Vgg16模型。首先解释为什么使用预训练模型是一种好方法。为了做到这一点,重要的是要考虑这些模型正在学习什么。本质上,CNN正在学习过滤器并将它们应用于图像。这些与你应用于Instagram自拍的滤镜不同,但概念并没有那么不同。CNN采用一个小方块并开始在图像上应用它,这个方块通常被称为"窗口"。
各层可视化
在第一层,网络可能会学习像对角线这样的简单事物。在每一层中,网络都能够将这些发现结合起来,并不断学习更复杂的概念。这一切听起来都很模糊,Zeiler和Fergus(2013)在可视化CNN学习的方面做得非常出色。这是他们在论文中使用的CNN。赢得Imagenet竞赛的Vgg16型号基于此。
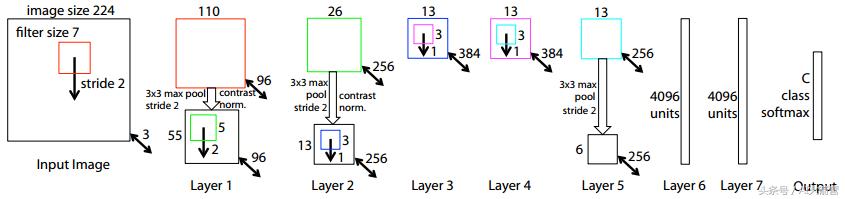
这张图片现在看起来很混乱,不要惊慌!让我们从一些我们都可以从这张照片中看到的东西开始。首先,输入图像是正方形和224x224像素。我之前谈到的过滤器是7x7像素。该模型具有输入层,7个隐藏层和输出层。输出层中的C指的是模型预测的类的数量。现在让我们来看看最有趣的东西:模型在不同的层次中学到什么!

左图像表示CNN已学习的内容,右图像表示实际图像的一部分。
在CNN的第2层,模型已经获得了比对角线更有趣的形状。
- 在第六个方块(水平计数)中,你可以看到模型正在拾取圆形形状
- 此外,最后一个正方形正在拾取角落。
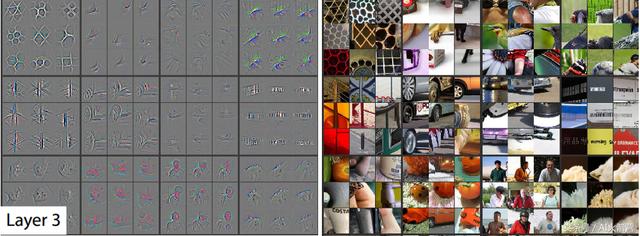
在第3层,我们可以看到模型开始学习更具体的东西。
- 第一个方块显示该模型现在能够识别地理模式
- 第六个方块正在识别汽车轮胎
- 第十一个方块正在识别人。

最后,第4层和第5层延续了这一趋势。第5层正在拾取对我们的狗和猫问题非常有用的铃声。它也拾取单轮脚踏车和鸟/爬行动物的眼睛。请注意,这些图像仅显示每层学习的一小部分内容。
希望这能说明为什么使用预训练模型很有用。Vgg16模型已经知道很多关于识别狗和猫的知识。我们的猫狗问题训练集只有25.000张图像。新模型可能无法从这些图像中学习所有这些功能。通过一个名为finetuning的过程,我们可以改变Vgg16模型的最后一层,这样它就不会输出1000个类的概率,只能输出2个猫和狗。
Finetuning和线性图层
用来对猫和狗进行分类的预训练Vgg16模型并不能自然地输出这两个类别。它实际上分了1000个类。此外,该模型甚至不输出类别的"猫和狗",但它输出特定品种的猫和狗。那么我们怎样才能有效地改变这个模型,只将图像分类为猫或狗?
一种选择是手动将这些品种映射到猫和狗并总结概率。但是,此方法忽略了一些关键信息。例如,如果图片中有骨头,那么图像可能是狗。但是,如果我们只看每个品种的概率,这些信息就会丢失。在那里,我们替换模型末尾的线性(密集)层,并将其替换为仅输出2个类的层。Vgg16模型实际上最后有3个线性层。我们可以微调所有这些层并通过反向传播训练它们。反向传播通常被视为某种抽象魔术,但它只是使用链规则计算渐变。你永远不必担心数学的细节。TensorFlow,Theano和其他深度学习库将为您做到这一点。
激活功能
我们刚刚讨论了网络末端的线性层。但是,神经网络中的所有层都不是线性的。在计算神经网络中每个神经元的值之后,我们将这些值通过激活函数。人工神经网络基本上由矩阵乘法组成。如果我们只使用线性计算,我们可以将它们叠加在一起。这不是一个非常深的网络......因此,我们经常在网络的每一层使用非线性激活函数。通过将线性和非线性函数层叠在一起,我们理论上可以建模任何东西。这些是三种最流行的非线性激活函数:
- Sigmoid (解析值介于0和1之间)
- TanH (将值解析为介于-1和1之间)
- ReLu (如果值为负,则变为0,否则保持不变)
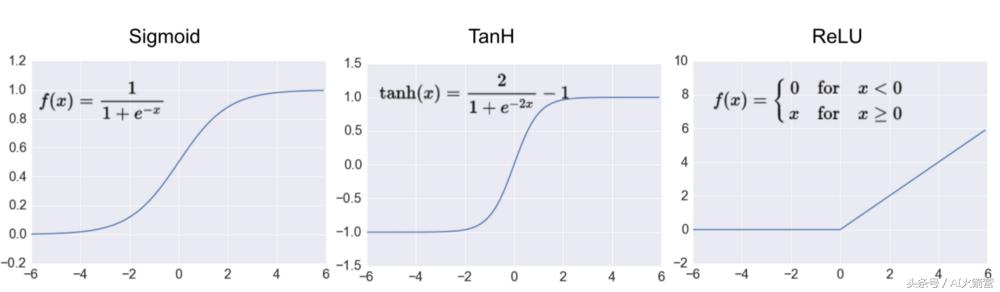
三种最常用的激活功能:Sigmoid,Tanh和整流线性单元(ReLu)
目前,ReLu是迄今为止最常用的非线性激活功能。其主要原因是它降低了梯度消失和稀疏性的可能性。我们稍后会更详细地讨论这些原因。模型的最后一层通常使用不同的激活函数,因为我们希望此图层具有特定的输出。softmax功能在进行分类时非常流行。
在微调Vgg16模型中的最后一层之后,该模型具有138.357.544个参数。值得庆幸的是,我们没有手工计算所有渐变。
本文转自:今日头条 - AI火箭营,转载此文目的在于传递更多信息,版权归原作者所有。





