在图像识别中,卷积神经网络(CNN)无疑是现在最先进的方法。CNN的基础操作是对图像中的局部区域做卷积提取特征,在每一层的卷积中使用相同的卷积核(共享参数)以减少参数数量,再结合池化(pooling)操作可以实现位移不变性的识别。
然而传统的卷积操作有两个缺点:一是使用局部操作,不能直接得到比较大的范围甚至图像全局的特征,且卷积核是固定的形状如3x3大小,对物体的形状、姿态变化缺少适应性。二是当特征的通道数量大了以后,卷积核的参数也变得庞大,会增加许多运算开销。针对这些问题,目前出现了许多新的思路来设计卷积操作,例如空洞卷积、可形变卷积、非局部卷积、可分离卷积、组卷积等。本文对这些新的卷积方式及相关论文做一个介绍。
一、空洞卷积
空洞卷积即Atrous convolution或者dilated convolution[1], 它将卷积核中相邻元素应用于图像中相隔一定距离的像素以增加感受野,如下图所示。
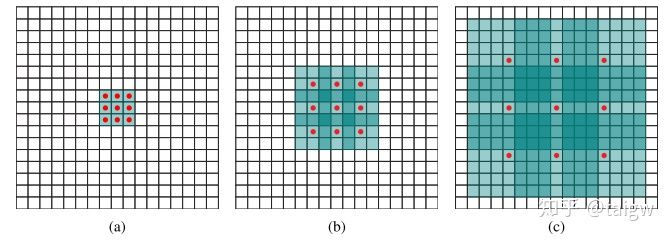
其中(a)是常规的大小为3x3的卷积。(b)是跨度为2、大小为3x3的空洞卷积,即卷积运算对应的输入图像中的像素间隔为2。(c)是相同卷积核大小下跨度为4的空洞卷积。可见常规的卷积是空洞卷积的一种特殊情况(跨度为1)。使用空洞卷积相当于从一幅降低了分辨率的输入图像中提取特征,在保持参数不变的情况下增加了感受野的范围。
二、可形变卷积
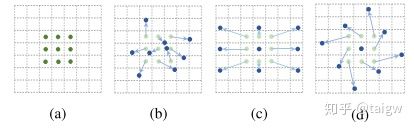
可形变卷积[2,3]针对常规卷积不能有效处理物体的几何变化的问题,提出对卷积的每个元素提供一个在图像中的偏移量,根据偏移量来决定卷积运算的输入像素。下图中比较了几种不同的卷积方式:(a)是常规的卷积,(c)相当于空洞卷积,(b)和是具有不规则的位移的可形变卷积,(c)和(d)可看做(b)的特殊情况。
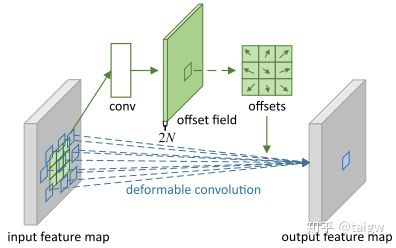
可形变卷积最初由Dai Jifeng 在[2]中提出,为了得到各个卷积元素所对应的位移向量,作者提出在输入特征图上通过额外的卷积层来预测卷积核中各个元素的空间位移,下图所示。
这个通过预测位移来实现可形变卷积的想法也可以用来实现可形变的池化(deformable pooling), 如下图所示。

三、非局部卷积
非局部卷积(non-local convolution)由CMU和Facebook提出[4]。最初是用来处理视频图像分类任务中捕捉远距离像素之间的依赖关系的。传统的网络一般通过多次重复卷积操作来增加感受野,以捕捉远距离像素之间的依赖关系,但具有计算效率低、优化困难等问题。非局部卷积将一个位置处的响应表示为输入特征图中各个位置的特征的加权平均。如下图所示,其中 Xi 处的响应是该帧图像及相邻几帧图像所有像素处特征的加权平均。

非局部卷积的数学表达式为:

其中 x 是一个输入特征图, y 是输出特征图,与 x 具有相同的大小。 f 是计算任意两个位置 i 和 j 处特征的相似度的函数。可以定义为高斯函数

也可定义为嵌入式 高斯函数(Embedded Gaussian)、点积等其他形式。[4]中提出了一个基于非局部卷积的模块,称为non-local block,将其与Resnet50、Resnet101等结合,在视频图像的分类任务中比原网络取得了更好的结果。
四、可分离卷积
可分离卷积将一个卷积操作分成几个更小的卷积操作,以提高运输速度。例如可将3x3的卷积分解成依次进行3x1的卷积和1x3的卷积。另一个较实用的卷积分离方法是将卷积核在空间上和通道上进行分离,又称为depthwise separable convolution[5]。即先在各个通道上分别进行空间卷积,然后沿着通道方向进行1x1的卷积,产生新的通道数量。Tensorflow中可通过tf.nn.separable_conv2d 实现,Pytorch中可通过将torch.nn.Conv2d的 groups设为与in_channels相同的值来实现。
五、组卷积
组卷积是把输入特征图在通道方向分成若干组,对每一组的特征分别做卷积后再拼接起来,以减少参数数量,提高运算速度。该方法在AlexNet中就被用来将特征图分解成两部分以分别部署到两个GPU上来处理内存消耗的问题。depthwise separable convolution可视作一种特殊的组卷积,使每一个分组只包含一个通道。
组卷积可视作一种稀疏卷积连接的方式,即每一个输出通道只与输入通道中的某一个组相连,可能会丢失全局通道的信息。为了克服这个问题,微软推出了一种交错式组卷积(interleaved group convolutions)[6],使输出通道能与所有输入通道相连。
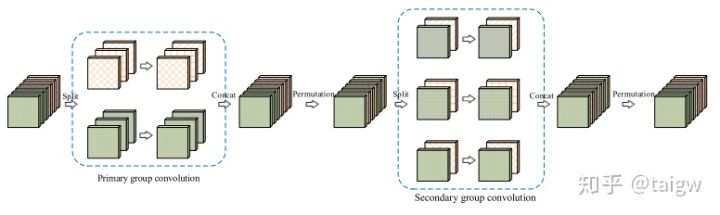
交错式组卷积如上图所示。假设输入由LM个通道,这里L = 2, M = 3。先将输入通道分成L个组,每个组包含M个通道,使用组卷积后将通道重新排序,分成M个组,每个组包含L个通道,再次进行组卷积。得到的输出即可捕捉到每个输入通道中的信息。
参考文献
[1] Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions." arXiv preprint arXiv:1511.07122 (2015).
[2] Dai, Jifeng, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. "Deformable Convolutional Networks." In Proceedings of the IEEE International Conference on Computer Vision, pp. 764-773. 2017.
[3] Zhu, Xizhou, Han Hu, Stephen Lin, and Jifeng Dai. "Deformable ConvNets v2: More Deformable, Better Results." arXiv preprint arXiv:1811.11168 (2018).
[4] Wang, Xiaolong, Ross Girshick, Abhinav Gupta, and Kaiming He. "Non-local neural networks." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794-7803. 2018.
[5] Chollet, François. "Xception: Deep learning with depthwise separable convolutions." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1251-1258. 2017.
[6] Zhang, Ting, Guo-Jun Qi, Bin Xiao, and Jingdong Wang. "Interleaved group convolutions." In Proceedings of the IEEE International Conference on Computer Vision, pp. 4373-4382. 2017.
本文转自:知乎 - 医学图像处理PhD机器学习/taigw,转载此文目的在于传递更多信息,版权归原作者所有。





