之前接触并了解过神经网络的相关概念,但是并没有做过任何系统的总结,这一段时间借此总结一下相关的概念;对于神经网络的入门概念来说最重要的是一些相关的理解性概念:反向传播、激活函数、正则化以及BatchNomalizim等。
一、反向传播:
其实反向传播归根结底就是一个每一次训练的动态更新的的过程,其遵循的原理是数学中的求导以及链式法则;理解了反向传播,也就能够理解梯度消失等相关的情况以及概念;
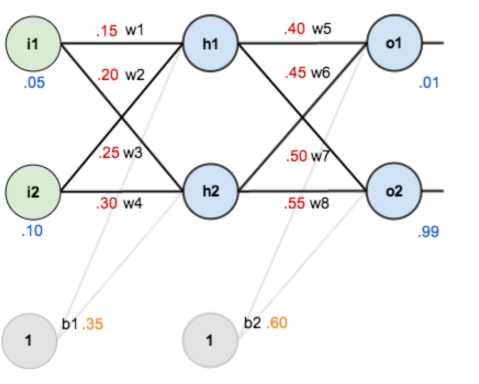
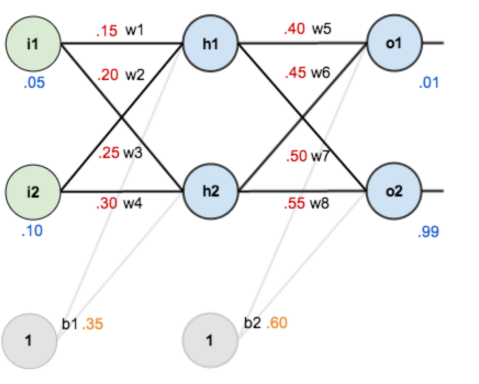
如下,我们给出一个简单的神经网络:

对于这个网络,输出层为o1和o2,反向传播的目的也就是根据求导来更新每一个w值,从而使得新的输出结果o1和o2能够更加接近我们所给定的值,这也就是训练过程。
这里也牵扯到一个损失的概念,也就是loss。我们所给出的loss就是生成的结果和所想要得到的结果的误差值,通常来说是差的平方;而所谓的梯度下降法等相关的优化函数,目的也就是通过反向传播,使得w值进行更新,使得新的输出更接近期望值,从而使得loss下降;
因此,对于一个网络,最核心的步骤就是如何通过数学推导,构造一个loss函数,在通过使得loss函数最小的步骤中,对网络中的参数进行调整,使得网络能够在测试阶段达到我们预期的分类或者是预测,甚至生成结果。这一点在后续的GAN网络总结中会进行系统的阐述;
由此可见,理解反向传播,对于后续的各个环节的理解很有好处;
对于上述的网络示例,我们可以通过对其的各个w更新推导,来进行反向传播的理解;
如果对网络参数w和b进行赋初值:
当我们进行首次前向传播时:
各个层的输出值如下所示:
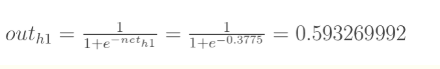



至此,我们就得到了相应的o1 o2初始值,从而可以根据和期望值进行loss计算。此时loss值就是我们期望通过反向传播(也可以理解成梯度下降里的一步操作)来进行减小处理的值。
对于反向传播来说,最主要的就是链式推导和求导过程构成的反向传播:
如果我们对w5感兴趣,希望知道他对于整体的误差产生了多大的影响,就对他进行求偏导,根据链式法则,则有:
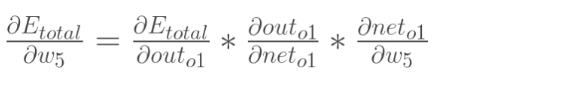
所以,对于w5的更新就有如下的式子,其中,η为学习速率;
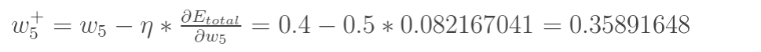
对于其他参数,也有相同的计算流程;
当全部计算完成后,就可以进行loss计算,在正常状态下,loss会越来越小,相应的,每一步都会进行反向传播计算来更新相应的参数值;
所以从上述推到可以基本得知,本质上反向传播就是一个逐个参数求偏导,继而更新使得loss下降的循环过程;
详细的数学推导后续在加强数学基础之后会给出;
二、激活函数:
之前一直对激活函数模棱两可,但是后续经过相关的检索才详细的知道激活函数的详细意义是什么;
激活函数的用处,主要和线性非线性分类有关;
例如我们常说的一个二分类问题,在二维平面上给出一些点,然后利用机器学习找出一条直线,将两种的点完全分开,如果线性可分,就可以称其为二分类问题。
但是对于某些情况下,并不是线性可分的,例如下图所示:
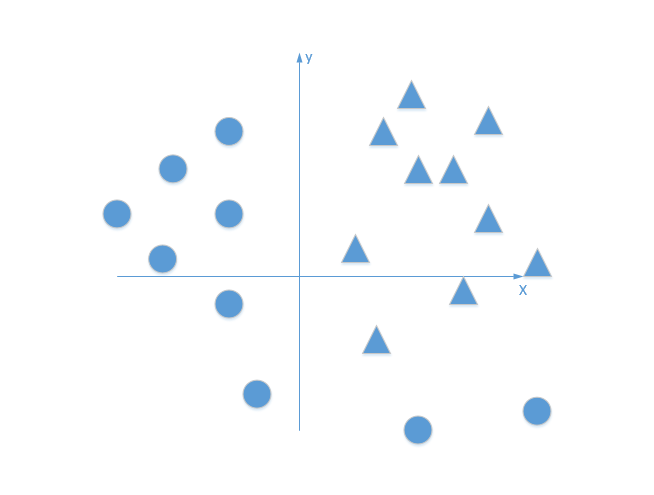
其实这里也牵扯到神经网络中节点输入输出的一些相关的线性方程理解;
对于如下神经元:
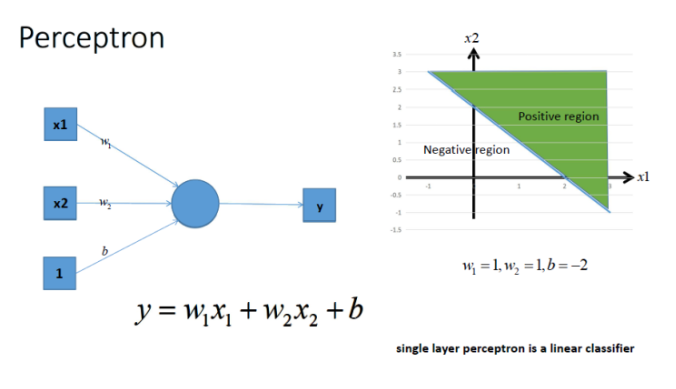
我们可以基本上观察出来,本质上神经元的输出就是线性方程,对应到图片上就是一条直线,y就是其预测值;
对于多神经元来说:
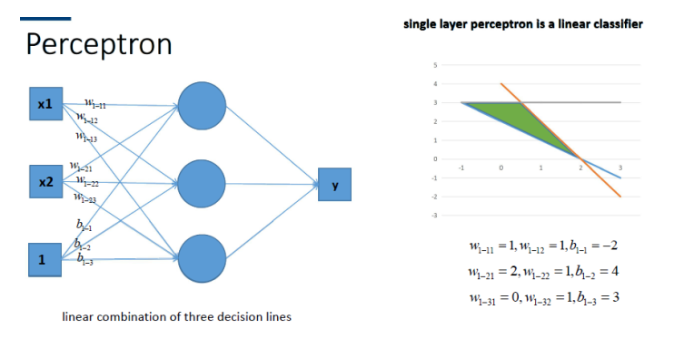
可以认为是多个线性方程组,所以最终我们得到的还是线性方程,而不是非线性方程;
对于非线性分类,我们也可以采用多个线性方程进行拟合,但是终究会存在很大的误差;
因此,激活函数的目的就是为了将线性方程变为非线性的;
如下图所示:

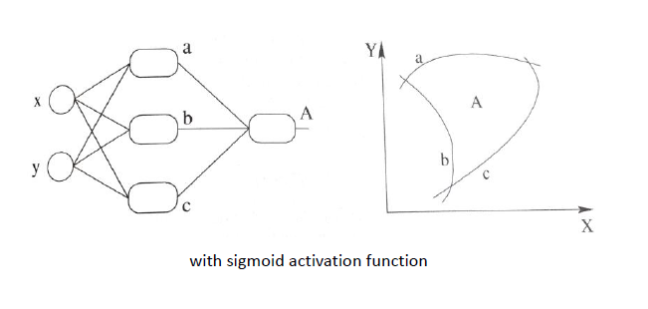
此时,线性分类通过引入非线性因素就变成了非线性分类,解决了线性分类所不能够解决的问题;
三、BatchNormalize
个人感觉BatchNormalize的根本操作就是归一化,区别不同的就是BatchNormalize操作可以加持在隐藏层;
之所以进行BatchNormalize操作的目的可以很好理解。
对于一个输入,如果经过神经元计算得到的结果需要经过sigmod激活函数,可能出现如下情况:
如果一个x1=90 x2=60,且之间还用数据分布;
由于sigmod的性质,可以知道,x1,x2都无限趋紧于1。此时,就可以发现该激励函数并不能很好的表达出数据分布的性质;
如果采用BatchNormalize操作,将所有数据重新分布在0-1区间,就可以将每个数据经过sigmod之后的值完美的映射在0-1区间内,从而保存了数据分布的特点;
当然BatchNormalize还加了两个参数,如下所示:

推导也会在后续的借鉴中给出;
本文转自:SegmentFault 思否 - 宋霖轩,转载此文目的在于传递更多信息,版权归原作者所有。





