我们生存的这个星球上,居住着70多亿人。每个人的面孔组成部分相同,它们之间的大体位置关系也是固定的,并且每张脸的大小差异也不大。然而,它们居然就形成了那么复杂的模式——即使是面容极其相似的双胞胎,也能由微妙的差别区分出来。人脸特征如同指纹一样,无法找到完全相同的存在。那么,区分如此众多的不同人脸的“特征”到底是什么?是否可以设计出与人类一样能够自动识别人脸的机器?这是近几十年来被广泛研究着的热门问题。随着AI技术的发展,也取得了显著的突破。
人脸识别到底是什么?
人脸识别,是视觉模式识别的一个细分问题,也大概是最难解决的一个问题。我们无时无刻不在进行人脸识别,我们每天生活中遇到无数的人,我们能辨别他们的长相,把不同的人区分开来。
然而这项看似简单的任务,对机器来说却并不那么容易实现。对计算机来讲,一幅图像信息表示为一个由众多像素点组成的矩阵。机器需要在这些数据中,找出某一部分数据代表了何种概念:哪一部分数据是人脸,哪一部分是非人脸,并且在人脸的那部分数据中,区分这个人脸属于谁。如果想要机器认出每个他看到的人,则这世界上有多少人,人脸就可以分为多少类,而这些类别之间的区别是非常细微的。由此可见人脸识别问题的难度。
人脸识别技术如何实现?
该技术主要包括人脸检测、人脸对齐、人脸验证/识别三个方面。
具体细分则包含以下步骤:

接下来详细介绍其主要步骤的内容和方法。
一、人脸检测
所谓人脸检测,就是给定任意一张图片,找到其中是否存在一个或多个人脸,并返回图片中每个人脸的位置和范围。自动人脸检测技术是所有人脸影像分析衍生应用的基础。

传统实现方法:Haar-like + adaboost算法
Haar-like特征有多种表示方法(图示),应用时将任意一个矩形放到人脸区域上,然后将白色区域的像素和减去黑色区域的像素和,得到的值可认为是人脸特征值;把这个矩形放到一个非人脸区域计算出的特征值则与人脸特征值不同。所以这些方块的目的就是把人脸特征量化,以区分人脸和非人脸。
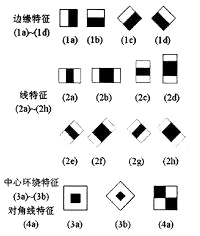
Adaboost(Adaptive Boosting)是一种学习模型,它的核心思想是将弱学习方法通过学习反馈提升成强学习算法,也就是“三个臭皮匠顶一个诸葛亮”。
两者相结合,利用 Adaboost优秀的数据挖掘能力从海量的Haar-like特征中训练得出强分类器,大大提高了检测的速度和检测的精确率。
深度学习:目标检测算法 + 人脸多任务级联算法
基于深度学习的多类目标检测算法发展迅速,将其应用到人脸检测中,具有通用性。具体包括以Faster-RCNN为代表的基于Region Proposal的目标检测算法,以及以YOLO,SSD为代表的基于回归的深度学习目标检测算法。
与此同时,深度学习对人脸对齐、多姿态人脸检测、人脸表情特征提取与降维、表情分类与表情识别应用等问题有创造性贡献,人脸检测与人脸对齐等多任务相结合的方法,后面章节会有详细介绍。
二、人脸对齐
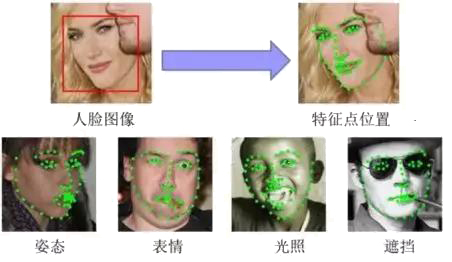
人脸对齐任务即根据输入的人脸图像,自动定位出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点等,如下图所示。
传统实现方法:局部二进制特征(LBF)回归
该方法主要有两个步骤:
1. LBF特征提取
通过在特征点附近随机选择点做残差来学习LBF特征,每一个特征点都会学到由好多随机树组成的随机森林,因此,一个特征点就得用一个随机森林生成的0,1特征向量来表示,将所有的特征点的随机森林都连接到一起,生成一个全局特征。
2. 全局线性回归
用训练好的模型对提取的LBF特征做回归,它是一个不断迭代的过程,越往下,所选择的随机点的范围就越小,特征点定位精度就越好。

深度学习:多任务级联卷积网络(MTCNN)
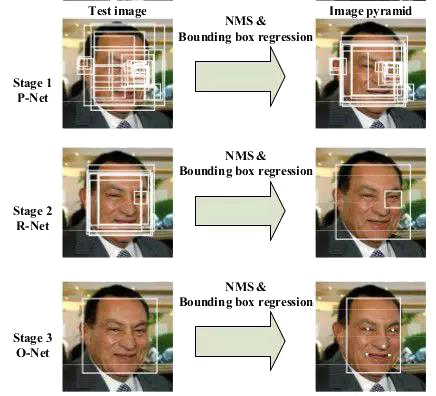
MTCNN(Multi-task Cascaded Convolutional Networks)算法是用来同时实现人脸检测和对齐的。该框架采用级联结构,包含三个阶段精心设计的深度卷积网络,以实现由粗到精的面部预测与部位标记。三个子网络分别为:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),如图所示,这3个阶段对人脸的处理遵循一种由粗到细的方式。一开始选取了不同尺寸的图像范围,构成了图像金字塔,然后分别输入这些规模不同的图像进行3个阶段的训练,以检测人脸的各个特征。由于姿势、光照或遮挡等原因,在非强迫环境下的人脸识别和对齐是一项具有挑战性的问题。这种算法可以很好的解决上述的两个问题。能利用检测和校准之间固有的相关性在深度级联的多任务框架下来提升它们的性能。
三、人脸验证/识别
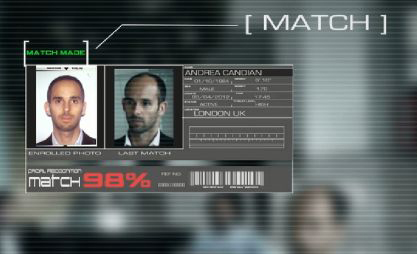
人脸验证做的是1比1的比对,即判断两张图片里的人是否为同一人。最常见的应用场景便是人脸解锁,终端设备(如手机)只需将用户事先注册的照片与临场采集的照片做对比,判断是否为同一人,即可完成身份验证。
与之相对地,人脸识别做的是1比N的比对,即判断系统当前见到的人,为事先见过的众多人中的哪一个。要回答的是“我是谁?”,相比于人脸校验采用的一一匹配,它在识别阶段更多的是采用分类的手段。应用场景包括疑犯追踪、小区门禁、会场签到,以及新零售概念里的客户识别。这些应用场景的共同特点是:人脸识别系统都事先存储了大量的不同人脸和身份信息,系统运行时需要将见到的人脸与之前存储的大量人脸做比对,找出匹配的人脸。

主要方法:
Deepface:
Deepface在实现时需要使用3D对齐技术将人脸图像校准到典型姿态下,然后将对齐的结果送入一个深层CNN网络进行处理。该模型训练所使用的数据集数目为四百万,共包含4000个人的人脸。DeepFace在LFW (Labelled Faces in the Wild)和在YFW (Youtube Faces in the Wild)人脸数据库上都取得了最好的结果。经过拓展后,其训练图库比原来的图库大了两个量级,包括100万个人的脸(identities),每个identity有50张图像,提高了识别的效率和精确度。

DeepId
DeepFace的工作后来被进一步拓展成了DeepId系列,主要改进的方面有:
- 通过联合识别与验证进行人脸表征深度学习,在分类和验证中使用多任务处理。
- 从一万个分类预测中进行人脸表征深度学习将多个CNNs结构联合起来。
- 深度习得的人脸表征具有稀疏性、选择性和鲁棒性,在全连接层前面使用不同的CNN结构。
- 使用更深的网络结构进行人脸识别,大约用到了200个CNN结构,模型非常的复杂。
相比于DeepFace,DeepID没有使用3D的校准,而是使用了一种更简单的2D仿射校准,所用的训练图库是由CelebFaces和WDRef两个人脸图像库混合而成的。

Facenet
FaceNet是谷歌研发的人脸识别系统,是一个基于百万级人脸数据训练的深度卷积神经网络的通用系统,可以用于人脸验证(是否是同一人)、识别(这个人是谁)和聚类(寻找类似的人)。FaceNet采用的方法是通过卷积神经网络学习将图像映射到欧几里得空间。空间距离直接和图片相似度相关:同一个人的不同图像在空间距离很小,不同人的图像在空间中有较大的距离。只要该映射确定下来,相关的人脸识别任务就变得很简单。

人脸识别是一项既有科学研究价值,又有广泛应用前景的研究课题。该领域研究成果丰硕,理论和研发日新月异,并在某些限定条件下得到了成功应用。这些成果更加深了我们对于自动人脸识别这个问题的理解,尤其是对其挑战性和可能性的认识。尽管在海量人脸数据比对速度甚至精度方面,现有的自动人脸识别系统可能已经超过了人类,但对于复杂变化条件下的一般人脸识别问题,自动人脸识别系统的鲁棒性和准确度还远不及人类。这种差距产生的本质原因现在还不得而知,毕竟我们对于人类自身的视觉系统的认识还十分肤浅。但从模式识别和计算机视觉等学科的角度判断,这既可能意味着我们尚未找到对面部信息进行合理采样的有效传感器(考虑单目摄像机与人类双眼系统的差别),更可能意味着我们采用了不合适的人脸建模方法(人脸的内部表示问题),还有可能意味着我们并没有认识到自动人脸识别技术所能够达到的极限精度。但无论如何,赋予计算设备与人类似的人脸识别能力是众多该领域研究人员的梦想。相信随着研究的继续深入,我们的认识应该能够更加准确地逼近这些问题的正确答案。
本文转自:微信号 - 智子AI,转载此文目的在于传递更多信息,版权归原作者所有。





