0、引言
作为一个机器学习方面的小白,在闵老师课上学的两个聚类算法,即经典的K-means聚类和基于随机游走的聚类算法,是我学习到的头两个与机器学习相关的算法。算法课上,闵老师先讲了简单但是经典的K-means聚类算法,让我们对聚类算法有了一个初步的理解,紧接着又花了大量的时间剖析了基于随机游走的聚类算法。五周十二次的课程,我学到的不只是算法本身,下面将从几个方面来总结我对本课程的收获。
1、两个算法
(1)K-means聚类算法
K-means是一种基于距离的迭代式算法。它将n个点分类到k个聚类中,以使得每个点距离它所在的聚类的中心点比其他的聚类中心点的距离更小。算法的过程如下:
1)所有的点中随机抽取出k个观测点,作为聚类中心点,然后遍历其余的点找到距离各自最近的聚类中心点,将其加入到该聚类中。这样,我们就有了一个初始的聚类结果,这是一次迭代的过程。
2)我们每个聚类中心都至少有一个观测实例,这样,我们可以求出每个聚类的中心点(means),作为新的聚类中心,然后再遍历所有的点,找到距离其最近的中心点,加入到该聚类中。然后继续运行2)。
3)如此往复2),直到前后两次迭代得到的聚类中心点一模一样。
这样,算法就稳定了,这样得到的k个聚类中心,和距离它们最近的观测点构成k个聚类,就是我们要的结果。实验证明,算法是可以收敛的。
(2)基于随机游走的聚类算法
这种聚类算法是一种将加权图进行聚类分析的聚类算法,用一个压缩矩阵表示数据与数据之间的关系,该矩阵表示每个节点随机游走到其他节点的概率。最后根据转移概率实现聚类分析。算法过程如下:
①求出K步以内每个节点游走到其他节点的概率矩阵之和;
②用该矩阵每一行代表该节点的特征向量即朋友圈;
③用该特征向量计算每个节点的特征向量的曼哈顿距离;
④用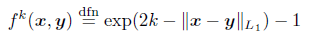 公式计算相邻节点的相似度;
公式计算相邻节点的相似度;
⑤遍历真个图,求出每一个类簇。
这里的k要根据图的大小确定,数据量大的图K值可以相对取大一点,数据量小的图则可以取一个较小的值。当K太大时,会使得最后的转移矩阵趋于稳定,并且会使得算法的时间复杂度变的很大。
2、编程技巧
(1)从简单入手,步步为营
作为我个人而言,虽然有一定的编程经验,但是有时候遇到一个问题可能会分析很久都找不到问题所在。因为我自己老是太过相信自己,想当然的认为自己的代码没有问题,可以达到自己想要的效果,然而有的时候恰恰是为这样的自以为是付出很大的时间代价来查找问题和解决问题。当老师提到“步步为营”这样的思想的时候,我自己下来把我们课上学的K-means算法按照自己的理解,边写边调试写了一遍没有出错的时候,我真的有一种想见很晚的感觉。
(2)注重代码通用性
注重代码的通用性应该是每个学编程的人的基本素质,以前编程的时候我也会时不时的考虑到这一点,但是这样的意识还不够强烈,因为每次都是把解决问题作为第一要务,通不通并没有那么重要。但是当我们实验室的学石工院的小伙伴让我帮他做一个计算矩阵的计算器的时候,我直接把老师上课写的代码复制过来就可以用的时候,除了开心之外就是真的意识到了一段通用的代码对于程序员来说意味着什么。
(3)考虑时间,空间复杂度
曾记得时间,空间复杂度的问题,还是一个在本科学习《数据结构》这门课的考试的时候才会考虑的问题,之后的编程中就很少考虑它了。但是现在学习算法了,而时间,空间复杂度又是衡量一个算法优劣的重要标准,而且在计算大数据的量的时候,又是一个不得不考虑的问题。所以,这个课也让我认识到了时空复杂度的重要性。
3、学习论文的方法
(1)抓主要矛盾
在学习《On clustering using random walks》这篇论文之前,我的导师也让我看过一篇论文,由于没有学习论文的经验,我就从头到尾,囫囵吞枣的看了一遍,然而看完就很懵逼,这篇文章都说了些啥??但是,跟着闵老师从头学习了这篇论文之后,我知道了一篇论文其实要学会抓住主要矛盾,掌握它的中心思想。
(2)学习论文不在多而在精
五周的时间就学习了这一篇论文,可能看起来内容很少,其实并不。我们从中学习到的很多学习的方法和技巧,将会运用到我们的其他学习过程中。认认真真的把一篇经典的东西学透,比把大量的知识学个大概应该要值得一些吧。
(3)要用代码实现
检验有没有看懂一篇文章的标准就是能够亲自动手写一遍。
4、准备使用的地方
(1)用K-means改进人群计数算法
最近在学习一篇论文,关于人群计数的,文章中用了三个卷积神经网络和一个开关网络(SCNN)实现人群计数,我在想我应该可以把K-means用到算法里面,来实现那个开关。在训练每个网络的时候我们可以计算出每个网络的质心,然后在计数的时候用每一个图片对应的向量计算到每一个网络的距离,然后确定该图片使用哪一个网络。
(2)用随机游走改进人群计数算法
也是改进这个算法,我准备用随机游走算法把这个算法改进成一个网络个数自适应的计数算法,网络的个数根据当前图片的疏密度确定。就是利用随机游走算法的不用指定聚类个数,可以保留聚类的自然属性的特性。其中每一个图片对应一个向量,也就是一个数据点。最后聚类的个数即为需要的网络的个数。
5、感谢
感谢闵老师这几周来的耐心指导,过程虽然很轻松,但是受益匪浅,谢谢老师。
来源:CSDN ,作者:Bob_lb
原文链接:https://blog.csdn.net/u013419318/article/details/86499654
版权声明:本文为博主原创文章,转载请附上博文链接!





