一. 深度学习
大数据造就了深度学习,通过大量的数据训练,我们能够轻易的发现数据的规律,从而实现基于监督学习的数据预测。

这里要强调的是基于监督学习的,也是迄今为止我在讲完深度学习基础所给出的知识范围。
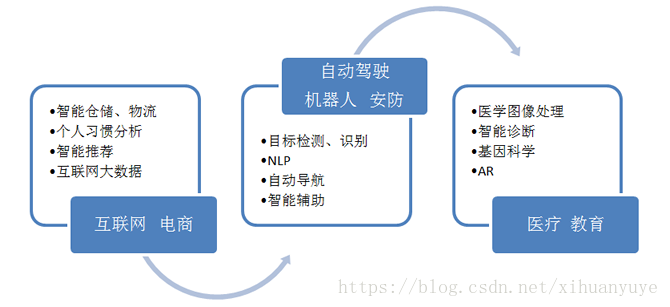
基于卷积神经网络的深度学习(包括CNN、RNN),主要解决的领域是 图像、文本、语音,问题聚焦在 分类、回归。然而这里并没有提到推理,显然我们用之前的这些知识无法造一个 AlphaGo 出来,通过一张图来了解深度学习的问题域:
2016年的 NIPS 会议上,吴恩达 给出了一个未来 AI方向的技术发展图,还是很客观的:

毋庸置疑,监督学习是目前成熟度最高的,可以说已经成功商用,而下一个商用的技术 将会是 迁移学习(Transfer Learning),这也是 Andrew 预测未来五年最有可能走向商用的 AI技术。
二. 迁移学习(举一反三)
迁移学习解决的问题是 如何将学习到知识 从一个场景迁移到另一个场景?
拿图像识别来说,从白天到晚上,从 Bottom View 到 Top View,从冬天到夏天,从识别中国人到 识别外国人……
这是一个普遍存在的问题,问题源自于你所关注的场景缺少足够的数据来完成训练,在这种情况下你需要 通过迁移学习来实现 模型本身的泛化能力。
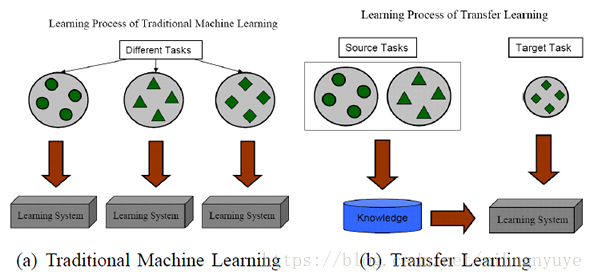
借用一张示意图(From:A Survey on Transfer Learning)来进行说明:
实际上,你可能在不知不觉中使用到了 迁移学习,比如所用到的预训练模型,在此基础所做的 Fine-Turning,再比如你做 Tracking 所用的 online learning。
迁移学习的必要性和价值体现在:
1、复用现有知识域数据,已有的大量工作不至于完全丢弃;
2、不需要再去花费巨大代价去重新采集和标定庞大的新数据集,也有可能数据根本无法获取;
3、对于快速出现的新领域,能够快速迁移和应用,体现时效性优势;
关于迁移学习算法 有许多不同的思路,我们总结为:
1、通过 原有数据 和 少量新领域数据混淆训练;
2、 将原训练模型进行分割,保留基础模型(数据)部分作为新领域的迁移基础;
3、通过三维仿真来得到新的场景图像(OpenAI的Universe平台借助赛车游戏来训练);
4、借助对抗网络 GAN 进行迁移学习 的方法;
三. 强化学习(反馈与修正)
强化学习全称是 Deep Reinforcement Learning(DRL),其所带来的推理能力 是智能的一个关键特征衡量,真正的让机器有了自我学习、自我思考的能力,毫无疑问Google DeepMind 是该领域的执牛耳者,其发表的 DQN 堪称是该领域的破冰之作。

目前强化学习主要用在游戏 AI 领域(有我们老生常谈的 AlphaGo)和 机器人领域,除此之外,Google宣称通过 强化学习 将数据中心的冷却费用降低了 40%,虽无法考证真伪,但我愿意相信他的价值。
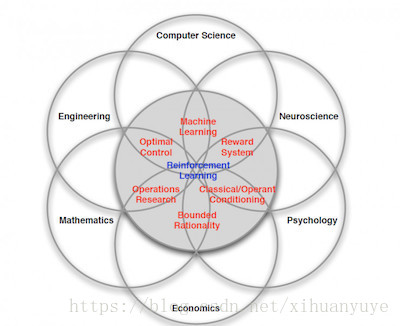
强化学习 是个复杂的命题,Deepmind 大神 David Silver 将其理解为这样一种交叉学科:
实际上,强化学习是一种探索式的学习方法,通过不断 “试错” 来得到改进,不同于监督学习的地方是 强化学习本身没有 Label,每一步的 Action 之后它无法得到明确的反馈(在这一点上,监督学习每一步都能进行 Label 比对,得到 True or False)。
强化学习是通过以下几个元素来进行组合描述的:
对象(Agent)
也就是我们的智能主题,比如 AlphaGo。
环境(Environment)
Agent 所处的场景-比如下围棋的棋盘,以及其所对应的状态(State)-比如当前所对应的棋局。
Agent 需要从 Environment 感知来获取反馈(当前局势对我是否更有利)。
动作 (Actions)
在每个State下,可以采取什么行动,针对每一个 Action 分析其影响。
奖励 (Rewards)
执行 Action 之后,得到的奖励或惩罚,Reward 是通过对 环境的观察得到。
通过强化学习,我们得到的输出就是:Next Action?下一步该怎么走,这就是 AlphaGo 的棋局,你能够想到,对应围棋的 Action 数量吗?
关于强化学习的具体算法,大多从 马尔可夫链 讲起。
---------------------
作者:xihuanyuye,来源:CSDN
原文:https://blog.csdn.net/xihuanyuye/article/details/81174557
版权声明:本文为博主原创文章,转载请附上博文链接!





