本文翻译自李航老师发表在 National Science Review 上关于自然语言处理中的深度学习文章,该文讨论了目前存在的优势与挑战。
1. 引言
深度学习指学习和使用 “深度” 人工神经网络的机器学习技术,比如深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)。近来,深度学习成功地应用在 NLP 中并取得了很多重要的进展。这篇文章总结了深度学习在 NLP 中取得的进展,最后讨论它的优势和面临的挑战。

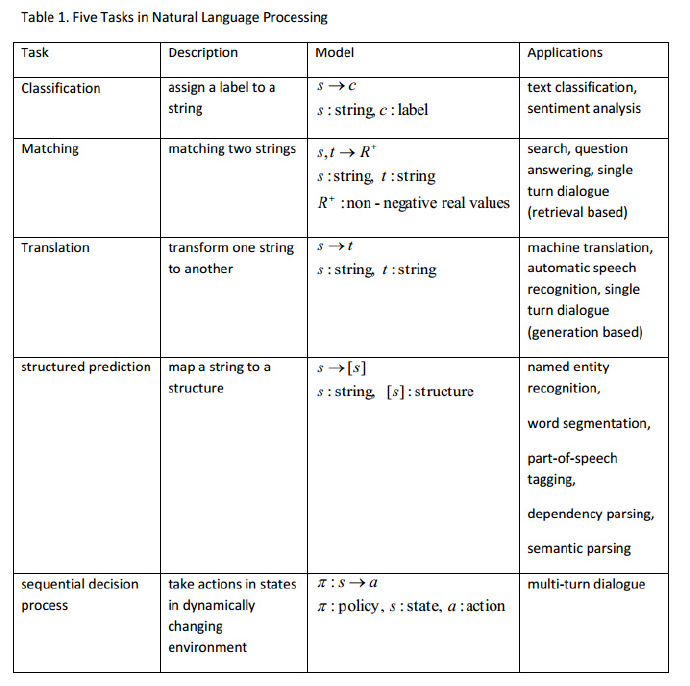
我们认为在 NLP 中主要有五个任务,包括分类、匹配(matching)、翻译、结构化预测(Structured prediction)和序列决策过程(sequential decision process)。对于前四个任务,研究发现深度学习方法的表现已经超过或者可以说远远超过传统的手段。
端到端训练(end-to-end training)和表示学习两者都是使得深度学习在 NLP 中成为强大的工具的关键特征。然而,深度学习并不是万能的。在多轮对话(multi-turn dialogue)中推理和决策的能力十分关键,但是深度学习并不擅长。另外,如何结合符号处理(symbolic processing )和神经处理(neural processing),如何处理长尾现象等等问题也都是深度学习在 NLP 中的挑战。
2. NLP 流程
我们认为, NLP 中有五大任务,即分类、匹配、翻译、结构化预测和序列决策处理过程。NLP 中的大多数问题都可以归结为以上五类任务,如表 1。在这些任务中,尽管有着不同的复杂度,单词、短语、句子甚至文档通常被当做 标记序列(sequence of tokens,即字符串 strings)来同等对待。事实上,句子是最常使用的处理单元。
据观察,深度学习能够帮助提升前四个任务的效果,并成为了这些任务中的前沿技术。
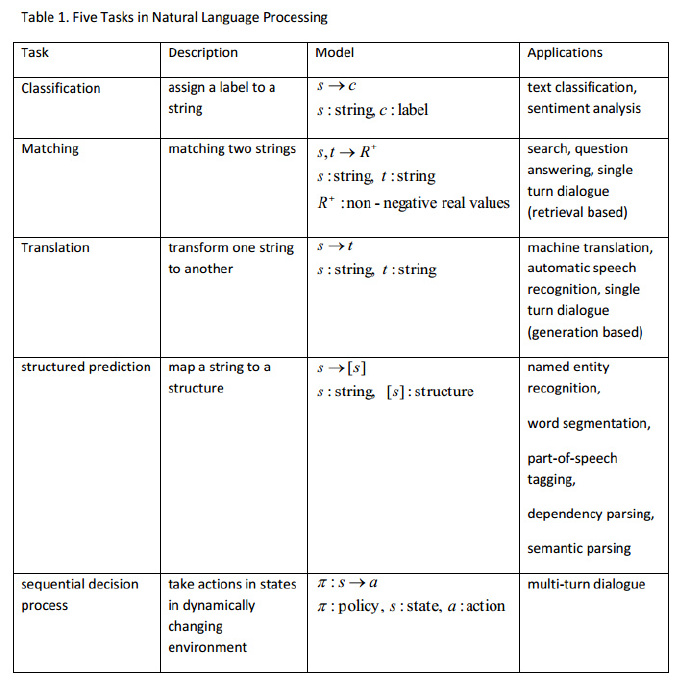
表 2 中展示的例子深度学习已经超过了传统方法。在所有的 NLP 任务中,机器翻译取得进展是最显著的。比如神经机器翻译,使用了深度学习后的机器翻译显著超过了传统的统计机器学习方法。前沿的神经翻译系统应用了包含 RNNs 的 sequence-to-sequence 学习模型。
深度学习也首次使得某些应用成为了可能。比如,深度学习在图像检索(image retrieval)就得到了成功的应用,在图像检索中,请求和图像都被 CNN 转化成为了向量表示的形式。另外,深度学习也在 generationbased 自然语言对话中得到了应用,
在多轮对话中的关键议题,即第五个任务,比如序列决策处理,比如马尔科夫决策过程。深度学习在这个任务中到底能够发挥多大的作用,目前还没有得到广泛的验证。
3. 优势与挑战
的确,在 NLP 中应用深度学习,优势与挑战并存,总结如表 3

3.1 优势
我们认为,在所有的优势中,端到端训练和表示学习是深度学习区别于传统机器学习方法关键,并且这两者让深度学习成为了 NLP 中一个强大的机器。
通常,在深度学习的应用中施展端到端训练,这是因为 DNN 模型在数据中提供了丰富的表示性(representability)和信息,它们能够在模型中高效编码(encoded)。比如,在神经机器翻译中,模型完全是由并行语料库中自动建立起来的,并且通常不需要人为的干预。对比需要特征工程的传统的统计机器翻译方法,深度学习优势明显。
在深度学习中,数据的表示有多种不同的形式,比如,文本和图像,都能够以实数值向量的形式学习。数据表示的形式使得信息处理能够在多个模式(multiple modality)中实现称为可能。比如,在 图像检索中,可以通过请求(文本)匹配最相关的图像,因为它们本质上都是向量(注:正因为都是数值型向量,那么它们便具备了统计意义)。
3.2 挑战
深度学习遭遇的挑战很常见,比如,缺乏理论基础、解释性模型、需要大规模数据和强大的计算资源。在 NLP 中遭遇的挑战不太一样,比如,处理长尾现象困难、无法直接处理符号、推理决策方面效率低下。
由于自然语言的数据通常服从幂率分布(power law distribution),词汇量会一般会随着数据量的增大而增大。这意味着无论训练数据有多么大,永远存在训练数据无法覆盖到的词汇。如何处理长尾问题成为了摆在深度学习面前的重大挑战。仅仅依靠深度学习,这个问题可能很难解决。
与深度学习使用到的向量数据(real-valued vectors)有所不同,语言数据本质上是符号数据。目前,语言中的符号数据转化为向量数据然后输入到神经网络中,神经网络的输出再转化为符号数据。事实上,NLP 中大量的知识是以符号的形式存在,包括语义知识(如语法),词汇知识(lexical knowledge,如 WordNet)和世界知识(如维基百科)。目前,深度学习还没有好好利用起来这些知识。符号表示易于解释和操作,而另一方面,向量表示在模糊(ambiguity)和噪音条件下表现稳健。如何组合符号数据和向量数据,如何充分利用两种数据类型的优势在 NLP 中仍然是一个开放性问题。
NLP 中有复杂的任务,仅仅依靠深度学习使不够的。比如,多轮对话就是一个非常复杂的处理过程。它涉及到语言理解、语言生成、对话管理、知识库访问(knowledge base access)和推理。对话管理可以形式化为序列决策过程,增强学习还可以起到关键作用。显然,深度学习和增强学习的组合对处理这些任务有相当大的潜力,远远超出了深度学习本身。
总的来说,在 NLP 中,深度学习仍然面临着许多挑战。当结合了其他技术(增强学习、推理、知识)之后,深度学习才有可能进一步推动这个领域(NLP)的发展。
原文:Deep-Learning-for-Natural-Language-Processing
原文链接:https://academic.oup.com/nsr/article/doi/10.1093/nsr/nwx110/4107792/
转自:Thinking Realm
译文链接:https://www.libinx.com/2017/Deep-Learning-for-Natural-Language-Processing/





