前面的一系列文章的优化算法有一个共同的特点,就是对于每一个参数都用相同的学习率进行更新。但是在实际应用中各个参数的重要性肯定是不一样的,所以我们对于不同的参数要动态的采取不同的学习率,让目标函数更快的收敛。
adagrad方法是将每一个参数的每一次迭代的梯度取平方累加再开方,用基础学习率除以这个数,来做学习率的动态更新。这个比较简单,直接上公式。
公式推导
∇θiJ(θ) 表示第 i 个参数的梯度,对于经典的SGD优化函数我们可以这样表示
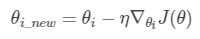
adagrad这样表示
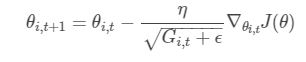
t 代表每一次迭代。ϵ 一般是一个极小值,作用是防止分母为0 。G i, t 表示了前 t 步参数 θi 梯度的累加
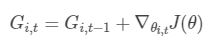
简化成向量形式
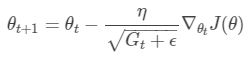
容易看出,随着算法不断的迭代,Gt 会越来越大,整体的学习率会越来越小。所以一般来说adagrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。
实验
实验取 η = 0.2, ϵ = 1e − 8
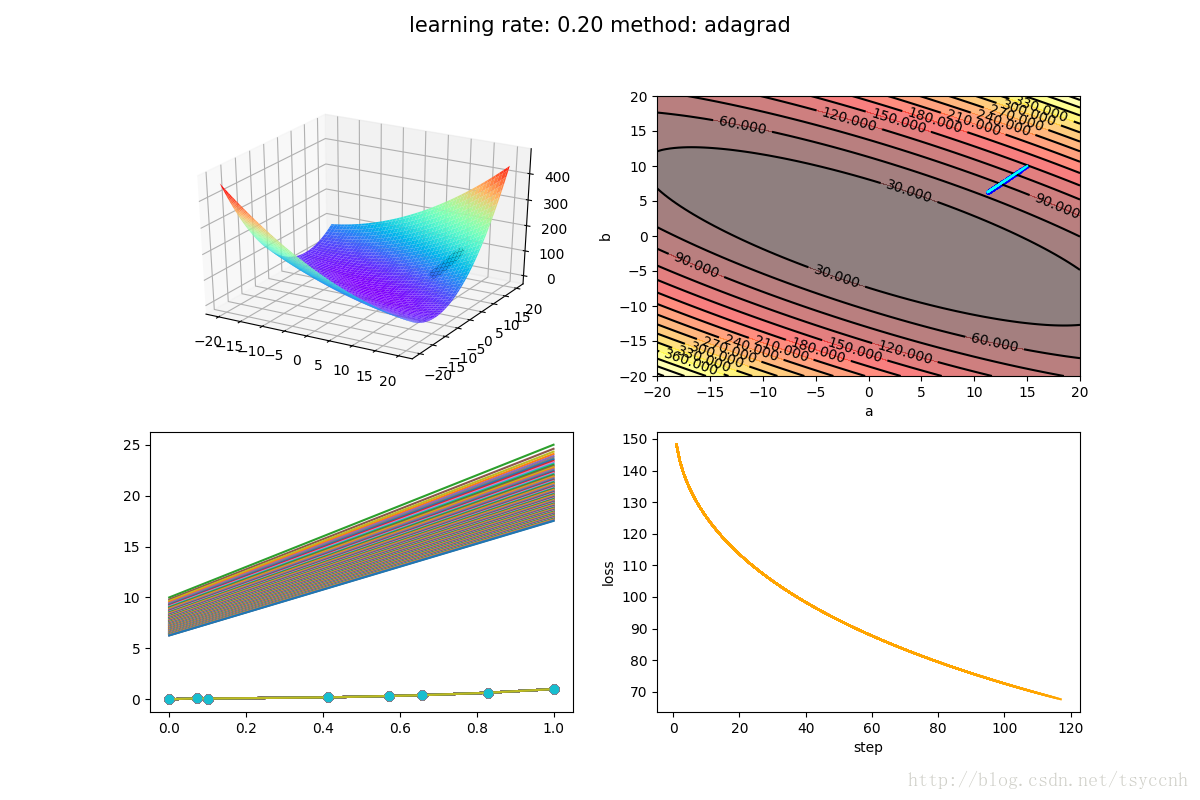
可以看出收敛速度的确是特别慢(在该数据集下),最重要的原因就是动态学习率处于一个单向的减小状态,最后减到近乎为0的状态。
实验源码:https://github.com/tsycnh/mlbasic/blob/master/p6%20adagrad.py
版权声明:本文为博主(史丹利复合田)原创文章,转载请注明出处。
原文链接:https://blog.csdn.net/tsyccnh/article/details/76769232