聚类属于无监督学习,事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类是不需要对数据进行训练和学习的。主要的聚类算法有K-Means和DBSCAN。
K-Means算法的基本原理比较简单:
1.指定K值(数据要分成的簇的数目),并指定初始的k个质心;
2.遍历每个数据点,计算其到各个质心的距离,将其归类到距离最近的质心点;
3分类完毕后,求各个簇的质心,得到新的质心点;
4.重复2和3中的操作,计算新的质心与旧的质心之间距离,如果小于设定的误差值,则停止计算,否则继续进行迭代。
K-Means算法的效果由SSE(sum of square error误差平方和)来衡量,聚类的效果受K值和初始质心影响很大,有可能会在局部形成聚类点。有一种改进方法是二分K-Means算法,每次选择SSE值最大的簇进行二分类,直到分成K个聚类。
K-Means算法还有一个很明显的缺点是对于某些分布的点是不能进行分类的,比如如图中的点:
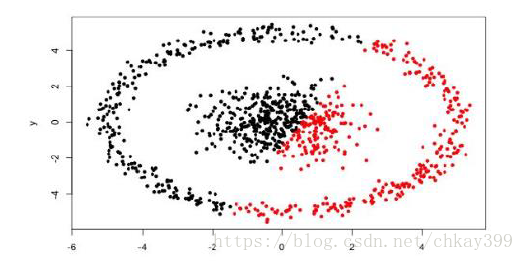
应该分为外环一个簇,内部一个簇的,K-Means的分类明显是不合理的。针对它的这些缺点提出了DBSCAN算法。
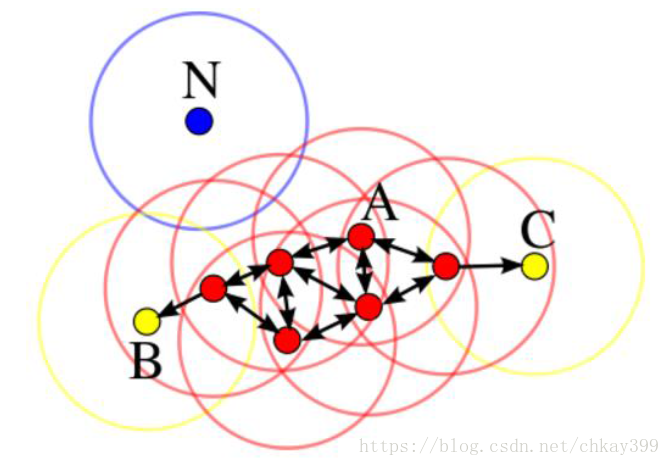
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法的原理指定一个半径r和阈值MinPts,将点归为三类:
1)核心点,如下图点A,在它的r半径内,点密度大于等于阈值MinPts;
2)边界点,如下图B和C点,在很核心点的r范围内,但是其自身r范围内点密度小于阈值MinPts;
3)离群点,如下图N点,其r范围内没有其他的点。
具体的聚类方法是:1.先将所有点标记为unvisited,并随机选择一个unvisited的点p,改变其状态为visited,从它开始遍历;2.点p若为核心点,且不属于任何的簇,则新建簇C,并对其r范围内的点进行遍历,直到遇到边界点位置;3.在剩下的unvisted点中随机找一个点开始2操作,直至所有的点都变为visited。
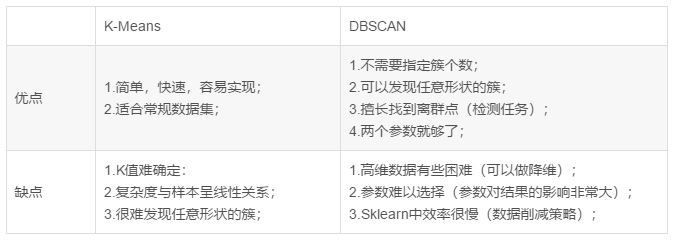
对两种聚类方法的优缺点总结如下:
本文转自:CSDN - chkay399,转载此文目的在于传递更多信息,版权归原作者所有。