作者:Sergei Chirkunov
神经网络架构的研究通常认为准确性优先于效率。某些论文对效率进行了研究(Tan和Le 2020)(Sandler等,2018),但这往往是基于CPU或GPU而不是基于加速器的推理。
来自Imagination AI研究团队的原创工作成果中,对许多在ImageNet上训练的知名分类网络进行了评估。我们对准确性或成本本身并不感兴趣,而是对效率感兴趣,这是两者的结合。换句话说,我们希望神经网络能够以尽可能低的成本在我们的IMG Series4 NNAs上获得高准确率。
我们涵盖了:
- 识别ImageNet分类网络架构,在我们的Series4 NNAs 上提供最佳的准确性/性能平衡
- 在不影响准确性的前提下,使用量化感知训练(QAT)和低精度权重来大幅降低成本。
高效推理的网络架构
我们探索了不同的ImageNet分类网络的权衡空间,衡量了几种成本维度如下,即:
- 推理时间(每次推理的秒数)
- 推带宽(每次推理传输的数据)
- 推推理的功耗(每次推理的焦耳值)
在每种情况下,我们都对以最低成本获得最高精度的网络感兴趣。下面显示了这些网络的精度和成本,是我们的Series4 NNA的各种单核配置的平均值,这些单核配置具有不同的片上存储器(OCM)大小和外部带宽。这些网络在没有量化感知训练(QAT)的情况下被量化到8位。
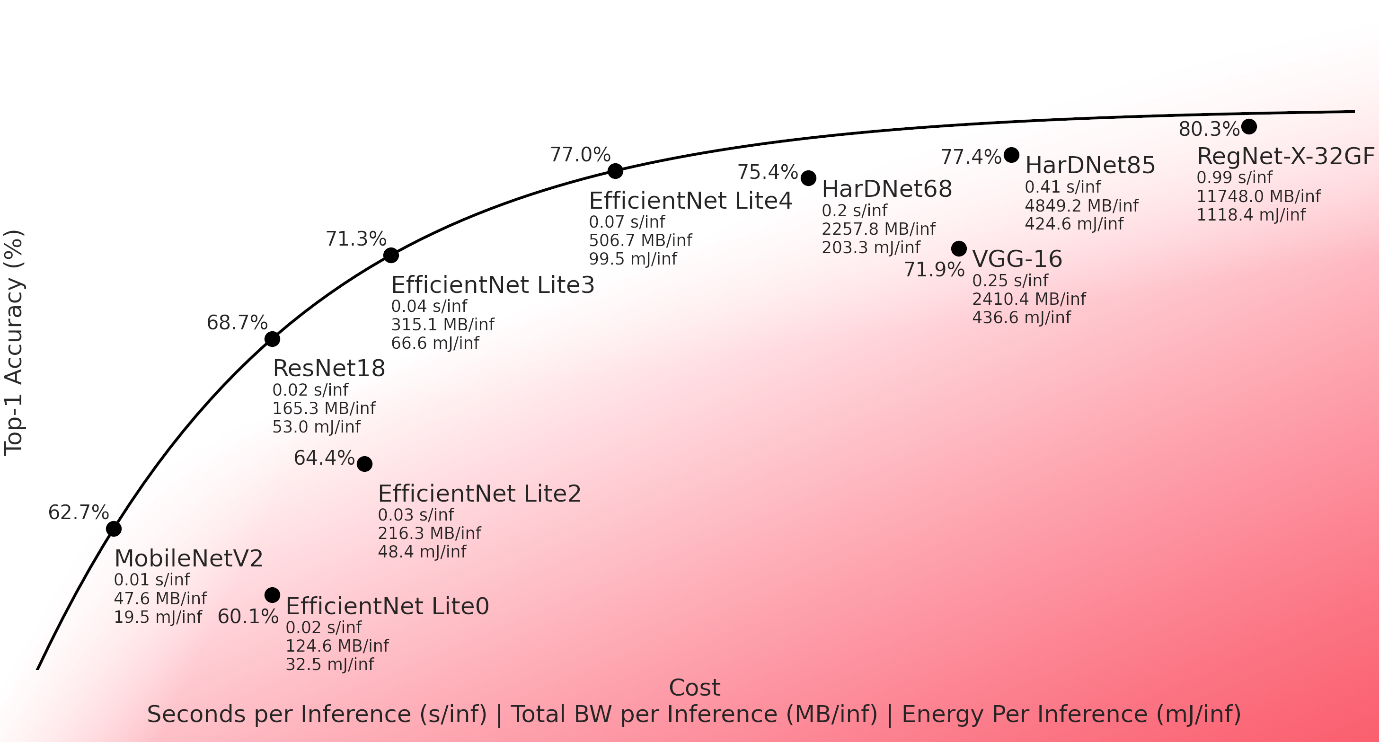
该图显示了top-1的准确性和推理时间、带宽和每秒推理功耗之间的权衡空间。位于图中左上方的网络比位于右下方的网络更有效率。那些最接近图中左上方的网络被认为是在Series4 NNA上执行效率最高的。我们在这些分布点位上拟合了一条 "权衡线",下面则是次优的网络。
权衡线上的网络性能优于在我们的硬件上测试的其他网络,并在效率权衡空间中给出了良好的性能范围,从快速/低精度(MobileNet v2)到慢速/高精度(EfficientNet Lite v4)。
在Series4上部署时,网络架构师可能会考虑是否可以将这些网络中的一个作为基础(比如,物体检测的骨干网络)。例如,VGG-16(Simonyan和Zisserman,2015)是一个流行的骨干网络,但它出现在图中的权衡线以下,表明对于达到的精度,它在推理时间、带宽和功耗方面要求都很高。我们可以选择用EfficientNet Lite v3来代替VGG-16,能够以更高的效率达到同样的精度。
我们还注意到,在试图最大限度地提高准确性时,回报率也在递减。例如,在我们分析的所有网络中,非常庞大的RegNet-X-32GF(Radosavovic等 .2020)在Series4上实现了最高的准确性,但代价则很高。
低位深度和高效的推理
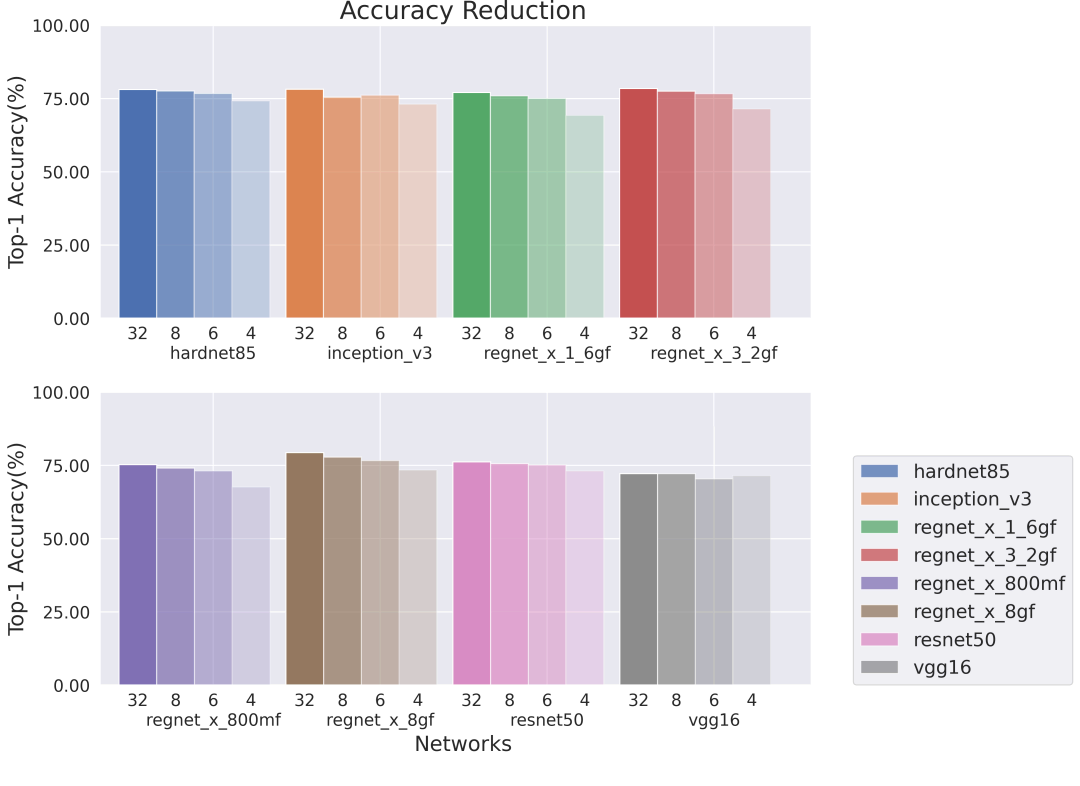
我们还研究了在我们的Series4 NNAs上提高网络效率的方法。实现这一目标的一个很好的方法是使用量化感知训练(QAT)来降低网络的位深度,从而实现更有效的推理。Imagination神经网络加速器硬件支持低精度格式的权重,我们在这项工作中利用了这一点。这有多种优势,包括更少的硬件通道、更密集的内存利用和更低的带宽消耗。我们用8位、6位和4位权重的量化感知训练(QAT)的神经网络映射到我们的Series4 NNA上,并测量其性能的变化,整个数据使用的是8位数据。
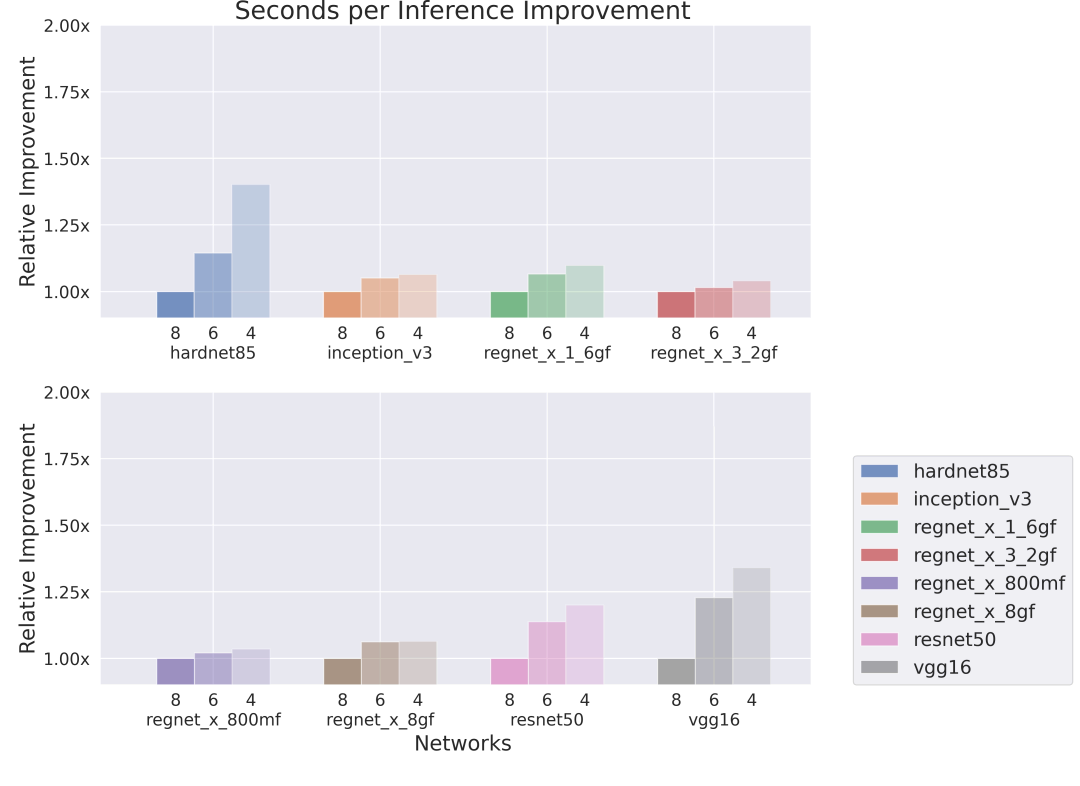
下面显示的结果分别是在单核和八核的Series4 NNA上运行的网络,其中单核的片上存储空间(OCM)为1MB,外部带宽为12GB/s,而8核Series4的片上存储空间(OCM)为88MB,外部带宽为115GB/s。较低权重的位深度明显提高了推理效率,特别是在带宽和内存被网络权重所支配的情况下(例如VGG-16)。一般来说,在带宽和内存比较有限的情况下,效率的提高是最明显的。
● 单核,低带宽,低内存
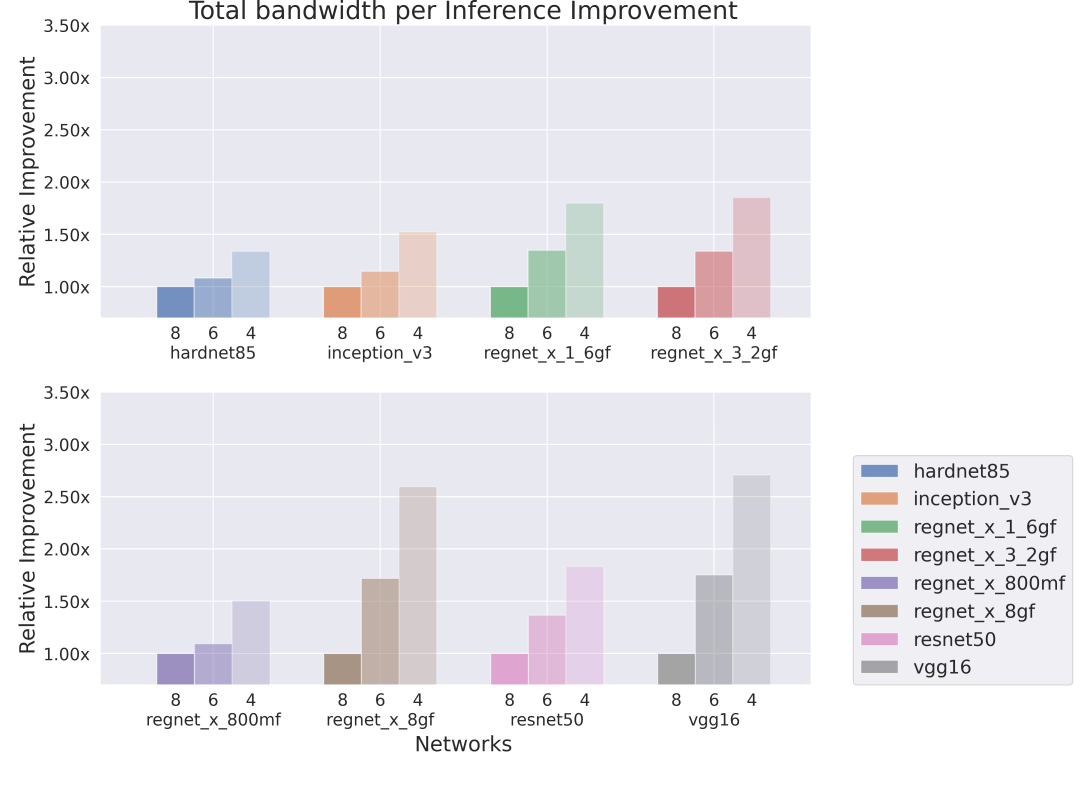
在权重占比高的架构中我们观察到了明显的改进,即VGG-16、HarDNet85(Chao等人,2019)和ResNet50(He等人,2015)。另一方面,当在高带宽硬件上运行时,具有更紧凑分组卷积的RegNets从量化感知训练(QAT)中获得的提升较小,但我们在低带宽硬件上仍然实现了每秒推理操作25-50%的提升。
● 八核,高带宽,大内存

在8核Series4上执行的网络带宽限制较少,而计算力限制的情况较多,这导致在我们将网络压缩到6位或4位时,每次推理的时间改善较小。
● 单核,低带宽,低内存

图4(上图)说明了RegNet X 8GF和VGG-16的总带宽减少到其原始带宽2.5倍以下的情况。
● 八核,高带宽,大内存
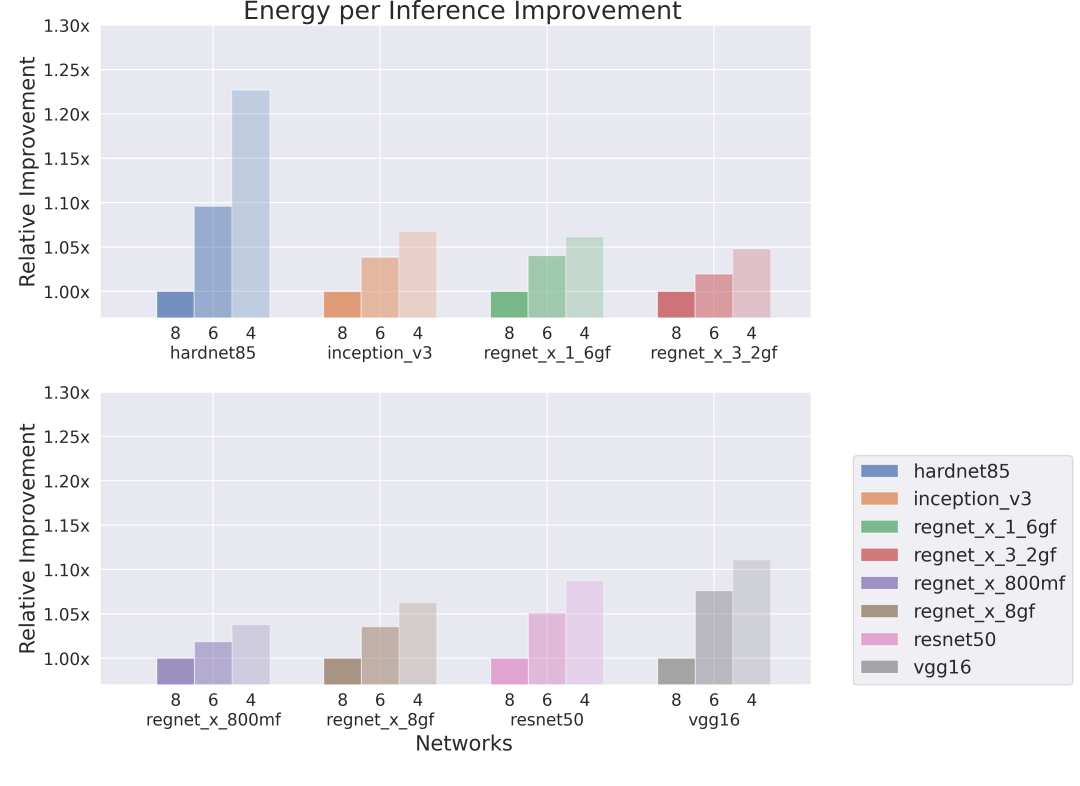
● 单核,低带宽,低内存

● 八核,高带宽,大内存
精确度
在大多数情况下,8位和6位权重的网络其精度与原来的32位浮点网络相似。那些采用4位权重的网络在精度上下降得更明显。在这些实验中,整个网络的位深度是固定的。Imagination公司最近的研究表明,允许网络学习权重的位深度可以在不影响质量的情况下降低整个网络的大小,我们希望这些对性能也能够有很大帮助。此外,我们观察到,具有大权重值和缺少分组卷积的网络对于压缩更加稳健,这会使准确率降低较小。请注意,网络中的所有层都使用了相同的权重位深度,我们希望自适应位深度能带来更高的精度(Csefalvay 2022)。
量化感知训练(QAT)工具
为了进行上述分析,我们开发了一个内部的量化感知训练(QAT)框架来量化PyTorch模型,并成功地将其映射到Imagination NNA上。通用性和简单性是该工具的显著优势。对于量化感知训练(QAT),我们在本篇博文中的所有网络中使用了非常相似的训练超参数(hyper-parameters)。通过仔细的微调,我们希望能够实现更好的性能和精度,尤其是在低位深度情况下,这将是我们未来的工作。
总结
在给定精度下选择使性能最大化的神经网络架构是非常重要的。此外,还可以采用低精度推理的量化感知训练(QAT)等技术,在不明显影响精度的情况下进一步降低成本。在目标硬件支持低位深度推理的情况下,这一点尤其重要,Imagination Series4 NNA就是如此。
在这篇博文中,我们已经确定了几个网络,它们在不同的性能点上对成本和精度做到了很好的权衡。进一步的优化,如利用支持整数权重的更低位深度硬件,可以在不影响准确度的情况下大幅提高性能。
Chao, Ping, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, and Youn-Long Lin. 2019. “HarDNet: A Low Memory Traffic Network.” Computer Vision and Pattern Recognition.
Csefalvay, Szabolcs. 2022. Self-Compressing Neural Networks. https://blog.imaginationtech.com/self-compressing-neural-networks.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Deep Residual Learning for Image Recognition.” Computer Vision and Pattern Recognition.
Ping Chao, Chao-Yang Kao, Yu-Shan Ruan, Chien-Hsiang Huang, Youn-Long Lin. 2019. “HarDNet: A Low Memory Traffic Network.” Computer Vision and Pattern Recognition.
Radosavovic, Ilija, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. 2020. “Designing Network Design Spaces.” Computer Vision and Pattern Recognition.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” The IEEE Conference on Computer Vision and Pattern Recognition.
Simonyan, Karen, and Andrew Zisserman. 2015. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” Computer Vision and Pattern Recognition.
Tan, Mingxing, and Quoc V. Le. 2020. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International Conference on Machine Learning.
原文链接:https://blog.imaginationtech.com/efficient-inference-on-img-series4-nnas
声明:本文为原创文章,转载需注明作者、出处及原文链接。





