Imagination 公司技术产品管理高级总监 Kristof Beets 分享了对光线追踪技术的观点以及 Imagination 的光线追踪 IP。

我是Kristof Beets,担任Imagination公司的技术产品管理高级总监。我在IP开发领域工作了20多年,致力于GPU技术,其中涉及从通用游戏到高端游戏的所有GPU技术。在这段时间里我负责过开发者技术支持、Demo开发以及业务拓展。
我一直致力于移动端GPU领域,并在Imagination公司从事相关技术工作,可追溯到2014年我们Plato Boards成立开始光线追踪技术的开发。我现在负责高能效IP的开发,将光线追踪技术推广到各种市场和平台。
Imagination作为一家IP开发公司已经超过35年了,在此期间我们一直处于图形技术的前沿。我们目前专注于移动、嵌入式和云计算领域,研究如何通过智能硬件设计为新平台带来最佳游戏体验。
光线追踪是什么?
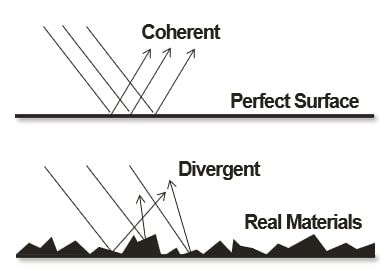
我们有很多博客和白皮书讨论了光线追踪技术,但从根本上讲光线追踪是建立在现实的基础上的:光线来自于光源,这些光线在物体表面反射并且相互作用(吸收、改变颜色、改变方向),最终这些光线会以某种特定颜色被眼睛所看到。整个过程产生了我们可以看到的视觉效果。你可以想象成从光源到我们希望的成像,正常情况下这个过程是颠倒过来的:我们的眼睛先看到光线,产生反射。目前较有效的方法是混合渲染,我们渲染大部分的传统场景,同时使用光线追踪技术查询要在处理的3D场景像素。

基本上对于反射曲面,你运行着色器,着色器是根据视角方向发射光线的,并在3D场景中查找对象发射到该像素中的内容。从根本上讲光线追踪将空间查询(spatial query)作为一种新功能添加到GPU中,这非常适合现实场景中的很多效果。光线是检查你能否看到(直接或反射)一束光,从而确定该像素是亮的或阴影以及前面提到的反射。
如今GPU的关键在于对于着色器要非常的灵活,如果与通用处理器单元(GPU)形式的计算结合使用则更加的灵活。GPU一直都是这样的特点,将半固定功能的硬件与完全可编程的着色器混合使用从而获得最佳的灵活性和效率。
在图形中光线、阴影和反射一直很流行。从无阴影到斑驳阴影,再到体积模块以及更复杂的过滤器和多分辨率查找,我们经历了很长一段时间。现在,我们使用了如此强大的计算性能和带宽,以至于成本非常高。而使用真正的光线追踪以达到好的光线效果会更快,成本更低,且质量一定比着色器更好。
在我们的光线追踪等级白皮书中对光线追踪的使用有详细介绍。Imagination从一开始就考虑电池供电设备的效率,所以我们的重点一直是光线追踪L4和L5高效解决方案。基本来说,我们完全从着色器(L2和L3的解决方案仅能够实现部分功能)上卸载了光线追踪,并且在照射物体时使用相干性排序来提高内存访问和执行效率。我们追踪和处理成束的光线而不是分散的光线,如果所有光线都朝着不同的方向发射是非常低效的。

伪造的光线追踪效果
我们讨论了一些关于阴影的技巧示例(例如无阴影、一些简单的斑点、模块、更复杂的阴影贴图),虽然这些技术变得更复杂,但随着你需要更高的画面质量,它们的缺点也越来越明显。
对于反射也可以这样做:无发射,伪造的模糊纹理查找,预烘焙立方体贴图,动态立方体贴图,甚至是部分软件光线追踪,比如屏幕空间反射。使用这种方法,你可以在屏幕空间内执行最少数量的光线追踪,使用方向向量和深度信息来反射附近的对象物体(但并不适用屏幕上的所有对象)。
Imagination推出的硬件级光线追踪IP
我们在2015年就已经将光线追踪单元集成到GPU中,比如我们的Plato硬件平台。这意味着着色器发出光线,专用的单元会采集许多光线并查找相干性。我们将沿相似方向的光线绑定在一起,然后对这些光纤束进行统一处理。我们访问一个BVH(边界卷层次结构)单元模块,首先检查光纤束是否与3D场景相交(基本上是一个非常大的边界框)。如果光线与3D场景相交,我们就沿着盒体的层次结构向下处理;整个场景就会分割成更小的盒体单元,然后我们再检查这个盒体的层次结构。
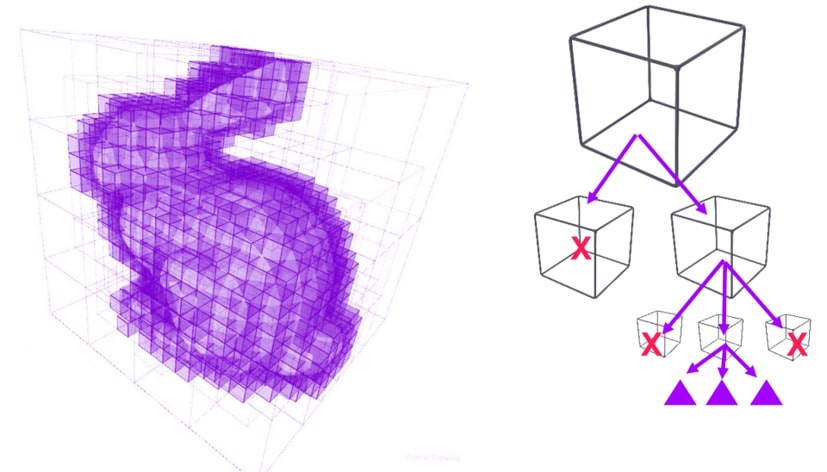
如果我们的光线束与盒体相交,我们将深入到盒体的层次结构中,直到最终该光束没有任何阻碍。如果直到光束不会击中盒体内的任何地方,我们可以通过快速排除场景内的大部分空间来节省时间和精力。当我们在某个点上看到越来越小的盒体时,我们会切换到实际的三角形几何体,然后我们从盒体光线测试转换到三角形光线测试。当然这是我们要找的光线实际交点,然后我们将其返回着色器码进行处理。
集成到游戏引擎中是很简单的,因为基本上发出光线是标准着色器代码的一部分,比如UE4引擎已经支持这一特性。我们还需要捕获场景信息并创建BVH,这同样是API的一部分,有点像几何处理。游戏引擎通过API将几何图形提交给GPU和驱动程序进行处理。
我们提供的独特性功能是相干性,例如光束处理与我们分块渲染(Tile Based Rendering)类似,后者我们也将像素分组在一起然后在芯片上处理。所以,从概念上看,分块渲染和具有相干性排序的BVH处理L4光线追踪解决方案非常相似,但是在带宽和处理效率上有很大的不同,游戏引擎的性能会更高,效果更好。



为移动平台打造
当然,光线追踪也总是有区别的,但问题是光线仿造的效果成本更高以至于使用专用的硬件功率更大、带宽更高,处理效率也降低。这点对于移动设备和PC端没有什么不同。使用纯粹的着色器图形技术已经不再是正确的选择,而我们的L4方案其效率已超过了PC端,就像我们20多年前创建的分块延迟渲染技术(TBDR)所带来的效果一样,如今它已经成为渲染的行业标准(IMR也不再适用)。
通过增加相干性聚集处理的效率,我们可以减少计算反射和光线相互作用的时间。这也减少了接口调用的次数,这意味着我们可以在低功耗的硬件上运行。
对于移动平台,我们总是希望用更少成本做更多的事,因为移动设备的功耗和带宽都是有限的。我们很高兴使用人工智能和神经网络来帮助处理图形技术。很幸运,我们为此开发了专用的加速器,并且能够与开发者合作利用这些单元实现最佳的效果,针对他们所用的硬件平台改进图形和光线追踪效果。
当然,我们还会不断创新。
与硬件的兼容性
我们始终专注于行业标准,因此我们的硬件会将DirectX和Vulkan所需和期望的标准考虑在内,硬件开发者不需要为使用我们做什么,当然他们也没有为其他厂商做什么。而与其他厂商不同的是,我们以更低的功耗和带宽成本来实现,为开发者其他任务留下更多的着色器时间。
提升的空间
工艺技术的演化遇到了瓶颈,例如我们实现了更高密度以及3nm和5nm的晶体管,但是带宽和功率的增长速率并不相同,我们必须拿出解决方案在最有效的处理逻辑上执行工作负载,比如哪些放在CPU和GPU来处理,哪些交给AI引擎来处理。我们也会看到更多的加速器诞生,比如我们的光线追踪引擎,可以提供更高的处理效率,管理更多异构的处理资源。带宽和数据流是很宝贵的,与相干性和分块渲染一样,我们一直在寻找将关键数据保留在芯片上避免使用外部功耗较高的DDR内存或HBM内存(功耗更高)。
我们一直希望用更低的功耗来实现更高的FPS,用更低的处理带宽和更低的功率实现更高的质量,这意味着我们所做的每个部分都要效率最大化。
* 本次采访由Arti Sergeev主持
原文链接:https://80.lv/articles/ray-tracing-explained-interview-with-imagination-technologies/
声明:本文为原创文章,转载需注明作者、出处及原文链接





