文章来源:TechSugar
随着汽车向智能化的发展不断深入,车载应用对算力的要求在不断提高。传统的数字驾舱和人机交互功能对算力要求较低,但在高级驾驶辅助系统(ADAS)中,对算力的需求明显增加,比如:车道偏离检测可能需要10 GFLOPS(每秒10亿次浮点运算)算力,行人预测可能需要500GFLOPS。
自动驾驶功能的实现,更离不开高算力,L2级别自动驾驶需要10 TOPS(每秒万亿次整数运算)算力,L3至L4级别自动驾驶则需要50至100 TOPS算力,实现L5级别全自动驾驶需要500 TOPS以上的算力。
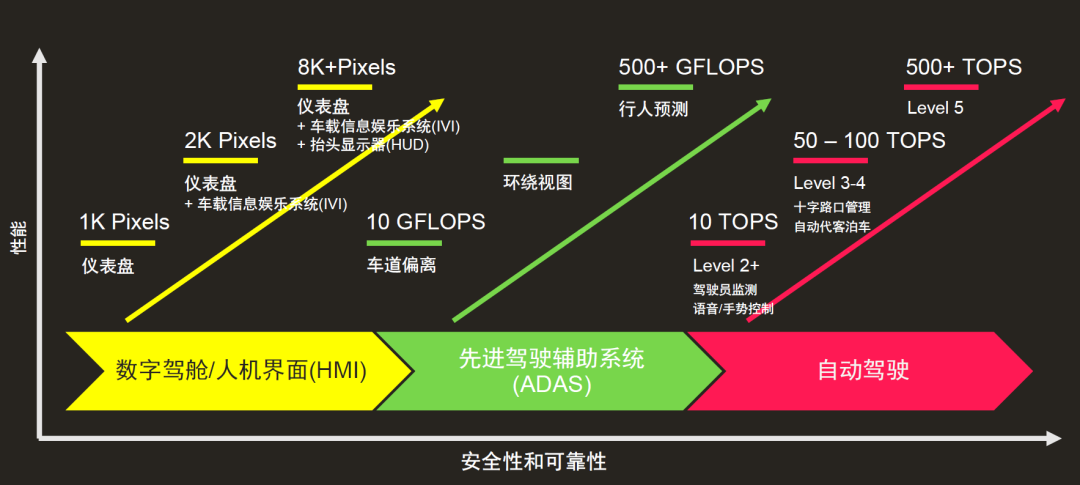
除了算力要求高,车载处理由于需要适应高速行驶场景,所以对任务处理实时性要求极高,这就需要处理数据的延迟很低,总而言之,车载智能应用随自主化程度提高,对性能的需求达到了极致。
为满足车载智能对算力的极致要求,全球著名IP厂商Imagination Technologies(以下简称Imagination)历时两年,多方收集车载用户需求,并针对车载需求全力优化,推出了新一代神经网络加速器(NNA)产品IMG Series4 NNA,4系列使用全新的多核架构,可提供600 TOPS甚至更高的算力,而且在处理大型神经网络时延迟极低,所需带宽极小,而且整个架构设计中贯穿功能安全(functional safety)理念,以帮助其车载芯片客户通过车规认证。
Imagination的神经网络加速器系列产品到现在已经是第三代,前两代2NX和3NX主要面向移动终端、物联网、安防监控等领域,以算力密度和能效比著称,采用2NX和3NX技术的芯片在AI benchmark等AI排名中名列前茅。
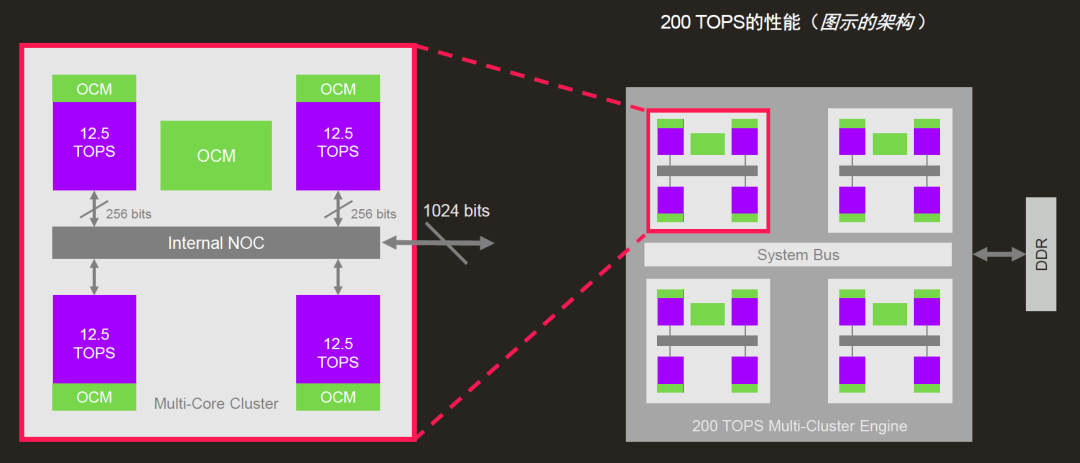
而4系列进一步提升了性能并推出了多核架构,在5纳米工艺节点,可以提供超过12 TOPS每平方毫米的性能密度,30 TOPS每瓦的性能功耗比,单核算力直达12.5 TOPS。

多核集群算力更是成倍增长,4系列支持集群内配置 2个、4个、6个或者8个单核,包含8个单核的集群算力即达到100 TOPS,6个集群算力达600 TOPS,可满足L5级别自动驾驶或数据中心等多种计算密集型应用场景。

除了算力爆炸性提升,Imagination在多核处理方面有多项创新性技术应用于4系列NNA。首先是正在申请专利的Tensor Tiling(试译为“张量切分”)技术,Imagination称之为ITT。

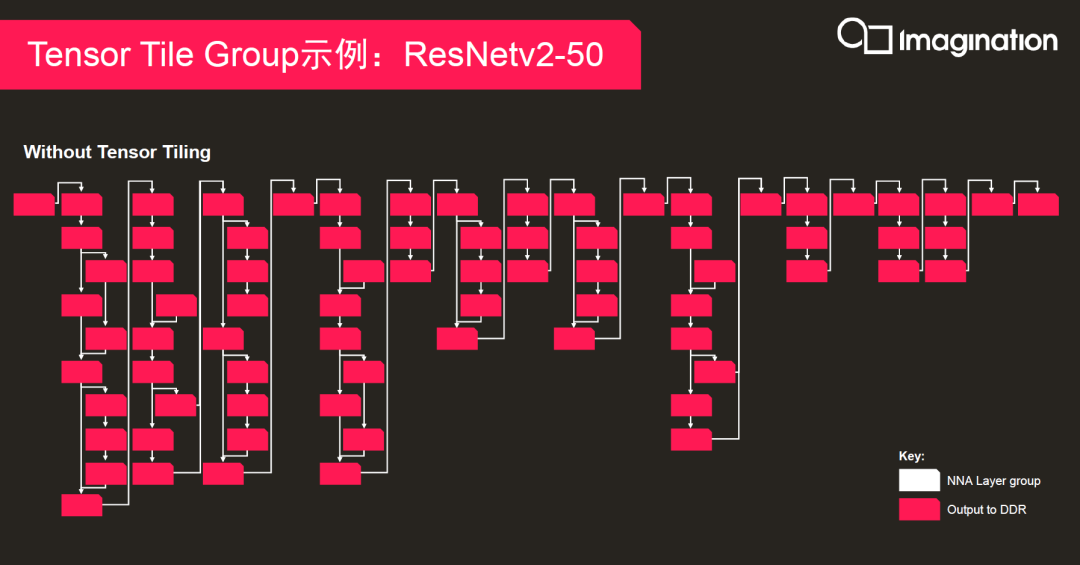

ITT的概念,是在空间维度上对每个张量进行拆分,利用片上存储加深算子融合,从而减少神经网络执行过程中通过外部存储交换的中间特征图,进而降低对内存带宽的需求。根据Imagination的统计,最大可减少内存带宽需求90%。这在计算大型网络时优势十分明显。
4系列NNA多核技术支持批处理,可以分配批处理任务的各组份到各个NNA单核,每个核独立工作,这种分配适合批处理小型网络。
4系列NNA还可以对任务在更多维度拆分和调度,所有单核可以相互协同,并行处理一个推理任务,这样减少了网络推理的延迟,理想情况下协同并行处理的吞吐量与独立并发处理相同,这种配置适合网络层很大的神经网络计算任务。对于一个8核集群,理想情况下任务并行执行的延迟会减少为单核独立执行时的1/8。
不同单核也可以运行不同的工作负载。这种情况程序可以根据需要进行不同的配置,例如总是用所有单核并行处理用户任务,或者为特定任务保留一个或一组单核,或者运行时动态分配。每个工作负载都可以被切分,开发者在平衡延迟和任务吞吐量之间有很大的灵活性。
在安全方面,4系列NNA包含IP级别的安全功能,且设计流程符合ISO 26262功能安全标准,可以帮助客户获得ISO 26262认证。Imagination Technologies人工智能业务高级总监Andrew Grant特别强调,与业界有些安全功能加入后会影响性能不同,4系列是在不影响性能的情况下,安全地进行神经网络推理。4系列的硬件安全机制可以保护编译后的网络、网络的执行和数据处理管道。
Andrew Grant表示,Imagination在汽车领域耕耘多年,现在汽车仪表盘市场有40%以上都采用了Imagination的技术,而Imagination今年先后推出的GPU BXS和4系列NNA都将汽车领域视为重要目标市场,这两者可以结合使用,4系列NNA负责人工智能推理任务,BXS GPU负责控制与其他图像相关处理工作,二者在应用时有非常强的互补协力作用。随着这两款强力产品的加入,相信Imagination在汽车市场的份额会进一步增加。