作者: Mathieu Einig
“只是简单的刻度盘!他们怎么能够设计的这么糟糕?”信不信由你,这个问题我已经提到过很多次了。
如果你想知道我们究竟在说什么,请看下文。
我们所谈论的是数字仪表盘上的刻度盘,我们可以在越来越多的现代汽车上找到它。自上世纪80年代首次设计出现,这种数字式仪表盘现在又重新流行起来,这是未来发展的趋势。数字仪表盘比传统的刻度盘能够提供更精确、更丰富而且更加清晰的信息。它可以是自适应的、动态的,准确的显示驾驶员在任何时刻需要看到的信息。如果得到制造商的许可,仪表盘还可以根据驾驶员的个人喜好进行定制。它们也可以看起来非常的酷炫,这在当今时代是非常重要的。
与其他数字显示器一样,这些数字仪表盘需要GPU来驱动,作为汽车领域的主要参与者,Imagination提供的解决方案已经在行业得到了广泛的应用。
当组装一台新的汽车时,OEM厂商就会使用最新的GPU来测试他们的数字仪表盘设计——这就回到了我们的问题——刻度盘。事实是这些仪表盘在几何形状方面往往设计得很糟糕,刻度盘是最糟糕的设计之一。
让我解释一下,正如你所期望的那样,这些刻度盘需要完全是圆形的。事实上在一些社区中任何不是圆形的设计都被认为是不太好的品味,而且在汽车行业肯定是不被接受的。
而这种圆形的设计是存在问题的,因为创建这种圆形的方法通常会使用非常密集的网格,这将导致在汽车中使用的嵌入式GPU的性能非常差。
这是一个问题,为了解决这个问题,GPU往往会被过度的设计,相比最开始简单的刻度盘设计需要更强大的性能。
怎么会变成这样呢?我的理解是这样的:
从本质上讲简单的在设计中添加更多的三角形是解决圆度问题最简单的方法,因为这种方式不仅可以创建资源,还可以集成到现有的渲染程序中去。因此我们看到很多厂商这样做,但是正如上文所述,一旦采用了这种方式就不可避免的出现性能低下的问题,而硬件是首当其冲。

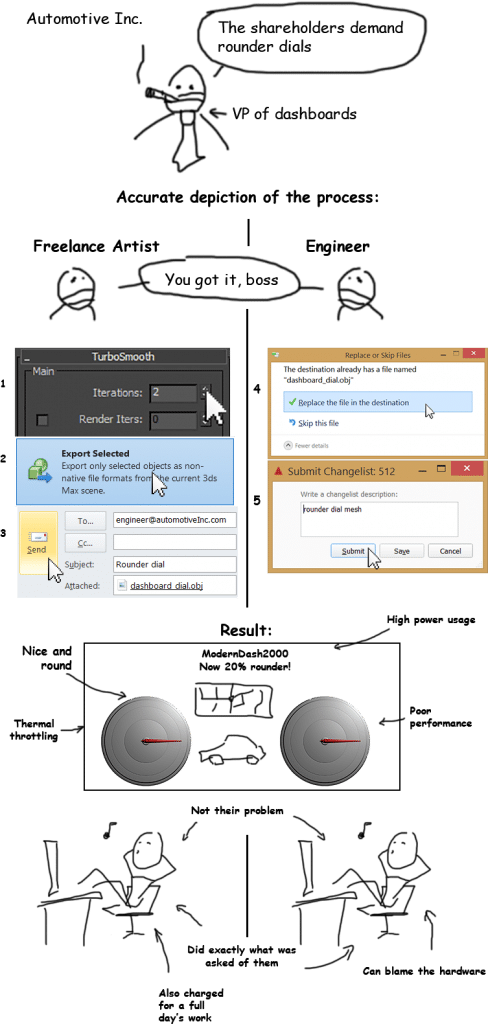
如下图所示:左边的刻度盘是圆形的,但是不够完美,我们要想将其设计的更圆(见上图),太棒了完成了,那么就让我们看看新设计的刻度盘:

仔细观察下右图中的线框,我们可以看到它采用了更多的三角形(总共超过了一万个三角形),但问题不在于三角形数量,而是低端的GPU也要能够以相当快的速度来处理一定数量级的数据。
真正的问题是密度:在只有几个像素大小的区域内聚集了大量的三角形,GPU的设计是为了加速三角形的渲染速度,而且这些三角形会跨越不同的像素区域——但我们这里的问题正好相反,这就导致了严重的性能损失。
不仅刻度盘渲染的很慢,而且会产生严重的重叠效果,每条边和每个斜面都会呈现比较粗糙甚至重叠的效果,这种问题唯一合理的解决方案是使用多样本抗混叠技术Multi-Sample Anti-Aliasing (MSAA)来处理,这就使得渲染过程的处理速度变得更慢。
超越几何模式
一个好消息是刻度盘实际上是一个非常简单的几何图形,从一个角度来看通常是非常平整的。因此它可以很容易的近似看作是一个简单的透明纹理的四边形,本质上预先计算所有几何图形和光照资源GPU可以非常容易的处理这些任务,额外的好处是纹理部分可以很容易的进行调整,使边缘变得非常平滑,从而不需要依赖MSAA技术。

这种在透明四边形上的纹理处理方式如上图所示,虽然这种渲染在成本上很低,但是有几个潜在的问题可能需要处理,当然这取决于设计师希望达到的质量:
- 整个对象必须使用透明度(通常不推荐),即使实际上只需要使用一小部分
- 刻度盘周围的整个区域是完全透明的,透明部分的像素可以进行栅格化处理并通过着色器处理,这难免会有些浪费。
- 当放大时我们可以看到线框,这在某些情况下是可以接受的
- 光照完全是内置的,如果需要更加逼真的效果可能就是问题
我们可以通过使形状更圆一些来减少浪费的像素,这本质上是像素和顶点数之间的权衡,一个镶嵌式的圆盘可能会更加接近原始形状,并且需要更少的透明度。在实践中没有必要在定点数方面做得太高,十来条边就足够了。

在这种情况下几何体的数量仍然是非常合理的,并且我们成功的消除了几乎所有浪费的透明空间。
现在因为只有表盘的外边缘需要是透明的,我们可以把这个对象一分为二:中间的圆盘是不透明的,外圈是透明的。这样我们不用在整个对象上使用alpha混合处理,就可以在边缘保持平滑的效果。但这意味着我们必须调用更多的处理同时渲染更多的三角形。

到目前为止我们设计了渲染效果非常好且光照也是静态的刻度盘,这意味着一旦光线或几何图形需要旋转,表面细节的效果将会完全被打破,根据设计师希望实现的风格,这是可以接受的,在这种情况下,本节的其余部分将是无关紧要的
如果需要动态的光照环境,这个渲染技巧则是值得大家知道的:它可以帮助模拟小的表面细节,而不需要调整实际的几何形状。最常用的方法就是法线映射,使用法线贴图在每个纹理的基础上调整表面法线(即计算光照时使用的方向)。

在法线贴图中颜色表示几何法线必须在三个轴中进行修改:红色通道空间修改法线的横向,绿色通道处理垂直方向,蓝色通道修改的是向外投影。在视觉上理解纹理的一个好方法是谨记最蓝的部分是显示变化最少的部分。
大部分3D资源包都能够很容易的从一对低密度和高密度的网格资源中生成这样的纹理资源。

使用法线贴图需要在渲染器中作一些修改,首先几何数据现在还必须包含每个顶点的切线空间,这是一个由三个方向组成的集合(其中一个方向是法线方向)。正切空间是法线贴图所指的三维空间——当法线贴图指示法线必须向左或向右倾斜时,正切空间将其转换为一个真实的三维方向。这个切线空间必须在顶点着色器中处理,将数据传递给像素着色器,最后用于解码法线贴图,这意味着增加带宽和处理成本。


现在我们有了一个平面几何图形,它对光线的反应和原始网格是一样的,快速检查一下:你能说出哪一个是原始的,哪一个是法线修正过的吗?
答案其实很明显,右边是最初的那个,它有一些混叠效果。
通过对法线映射和切线空间的理解,我们可以进一步改进对于纹理资源的使用。基本上我们不需要渲染整个对象的纹理,我们只需要提取楔形的法线贴图即可,然后进行循环复制。因为法线贴图是相对切线空间的,而且切线空间会随着它的几何形状进行旋转,因此在数学上是成立的,一切都会向预期那样进行。

三角形的数量再次完全取决于你:更薄的三角形意味着采用更多的三角形,但是浪费更少的纹理资源。
采用这种技术中心部分会变得比较混乱,从某些角度看上去三角形会变得非常的明显。

我不完全确定根本原因是什么,但这可能是纹理和过滤精度的问题:当我们观察中心部分时楔形的面积变得越来越小,即使一个微小的问题都可能产生严重的影响。大部分法线映射图都可以在纹理中进行填充,这会在一定程度上减少这个问题,但是本例中并没有这样做。实际的解决方案是在中间设计一个更小的圆形进行单独的处理。

看看下图的纹理设置,很明显第二张图节省了很多纹理空间:
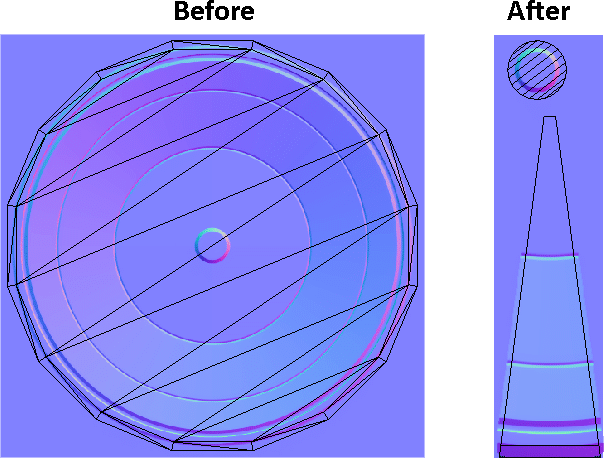
从视觉上看细节的质量得到了很大的提升,即使在放大时楔形的方法仍然能够保证刻度盘表面的光滑和真实的效果。

通过消除对大量冗余数据的需求,我们成功的增加了纹理密度,同时降低了实际的纹理分辨率,效果还是不错的。
经过这么多次迭代之后,现在可以想一想我们已经向前走了多远。曾经采用密集的网格来生成混叠的效果,而且无法估计采用MSAA技术处理的过程。我们现在采用一个非常小的网格对象并结合更少的纹理资源就可以实现更好的效果,而且不需要采用MSAA技术。
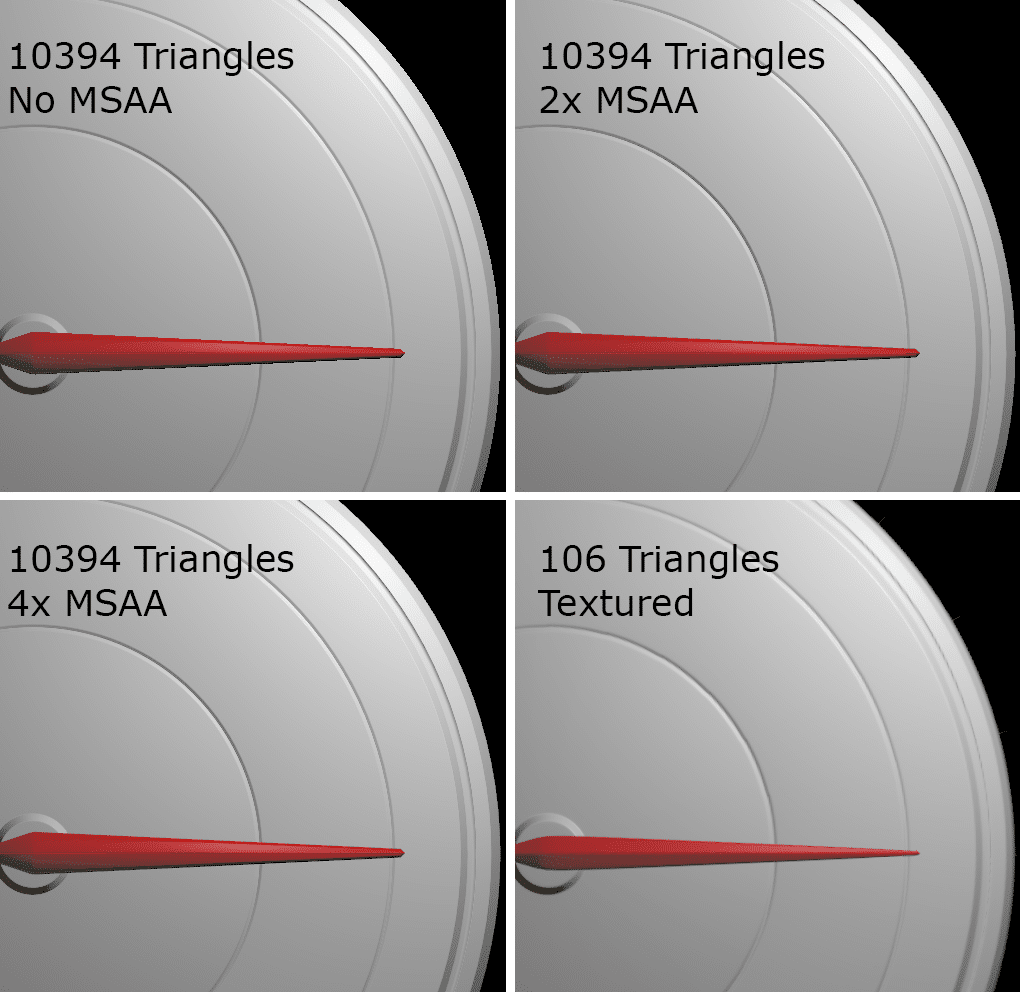
那么性能会是怎样的?我们已经移除了几何图形,但是我们在其他方面增加了复杂度:现在我们不得不需要更多的对象,采用Alpha混合技术,并执行更加复杂的分片着色器进行处理。
性能分析
为了测量性能。我们设计了一个自动化的基准测试,显示由单个动态光源点亮的多个刻度盘。。然后用我能找到的最小规模的GPU(PowerVR GE8300)在设备上完成部署并运行起来,最后采用PVRTune工具进行检测并分析性能数据。
让我们从采用最原始方法创建的刻度盘开始,下图显示的是渲染的不同刻度盘以及刻度线的清晰度:

专业提示:如果刻度线渲染效果是固定的那么说明设计方式采用了太多的三角形。
下图显示了GPU在渲染基准测试时所花费的时间,下面的块表示人物,颜色由帧号进行编码。任务是处理几何图形包括运行顶点着色器,剔除反向三角形以及屏幕外的三角形等。渲染任务是在像素级别下完成的,例如对三角形进行栅格化处理,还有执行像素着色器。
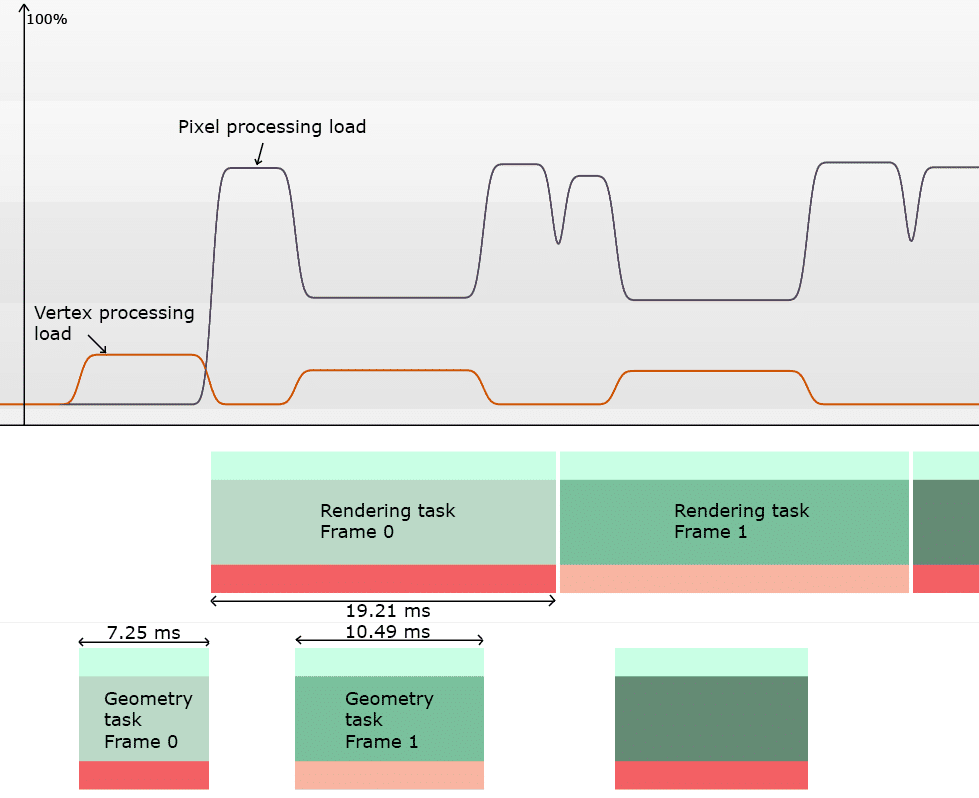
正如预期的那样,几何图形的处理占用了相当多的时间,这对于移动端的GPU这样的工作负载也是可以接受的。更令人惊讶的是将几何图形转换为像素所需的时间只有19ms,对于整个画面显示的时间预算在16ms,那么这个转换时间占用还是太高了。这里采用的像素着色器还是很简单的,对任何GPU来说应该都是没有问题的,那么到底是哪部分花费了这么长的时间呢?
如前文所述栅格化处理不好细长的三角形,效果如上图所示:像素处理负载计数器表示像素着色器处理部分像素所占用的时间,在正常情况下运行时间预计将接近100%,然而在本例中它甚至没有达到60%,这意味着GPU被卡住去处理其他的任务,最有可能是在几何图形的光栅化处理占用了太多性能。
启用4X MSAA技术后情况变得更糟糕了,应用运行时画面的帧率从50fps降低到30fps,现在30fps对于全高清的渲染本身并不可怕,实际上对于许多3D应用和游戏来说是相当标准的,我怀疑(并希望)这种情况最好不要出现在如此关键的汽车系统组件上。
现在让我们继续优化刻度盘的渲染器,在视觉上并没有什么不同:线框看起来很合理,而且最后一帧看起来也很完美。

但是在下图中我们现在可以看到它现在以60fps的速度运行,这意味着在应用程序中可以支持额外更多的特性和内容,这是一个非常大的提升。

有趣的是尽管我们给像素着色器分配了更多的工作,但是渲染任务现在完成的更快了。这主要是由于几个因素,一般的想法是不要将所有的处理操作都由GPU的某部分来单独完成,这样会使它最终完全超负荷工作,我们要做的是将任务分散给不同的专业单元来完成。此外合理的网格密度不会再导致光栅化效率低下,这可以在像素处理负载计数器中观察到,现在几乎可以达到100%的使用率。
总结
我们所展示的是虽然移动端GPU在性能方面已经取得了长足的进步,但我们还没有达到让其执行所有操作的程度,我们介绍了如何以一种更微妙和更聪明的方式来完成这些任务,设计也不一定要非常的复杂。的确这可能需要更多的技术支持和指导,因为需要工程师和设计者都要参与进来,并且要更大程度的进行合作,这带来的好处也是巨大的。在展示的示例中我们已经从难以接受的图形显示帧率过渡到甚至能够超越设备本身的性能,而且图像的处理过程也更加的清晰。
结果就是即使是我们中端GPU在移动端器件中也能够支持数字仪表盘在确保流畅显示的同时,支持最新且外观设计最漂亮的数字仪表盘,最重要的是有完美的圆形刻度盘。
原文链接:https://www.imgtec.com/blog/dialling-it-up-on-powervr-gpus-how-to-optimi...
声明:本文为原创文章,转载需注明作者、出处及原文链接,否则,本网站将保留追究其法律责任的权利。





