本文将由游戏开发者Michael Short分享Unity中的阴影优化。
我们在开发游戏的过程中使用了一个投影式阴影系统,它类似阴影贴图,会从光源的角度渲染对象,然后把阴影从光源投射到场景。
在开发游戏的过程中,使用功能丰富的Unity阴影贴图解决方案会显得有些浪费。因为我们不希望为所有内容渲染动态阴影,而只打算对场景的较小物体渲染动态阴影。我们想更好控制对阴影的过滤,通过添加模糊效果,使阴影更加柔和。

我们在对游戏进行性能分析时,发现生成这类阴影贴图需要总体帧时间中大约12%,因此我们仔细研究如何减少这项开销,以及系统消耗的内存量。
优化工具
首先是启动性能分析工具,对Android系统进行分析时,使用RenderDoc,对iOS系统进行分析时,使用XCode。
如下图所示,RenderDoc是一款免费的性能分析和调试工具,可以连接到托管Android设备,获取帧的跟踪信息。
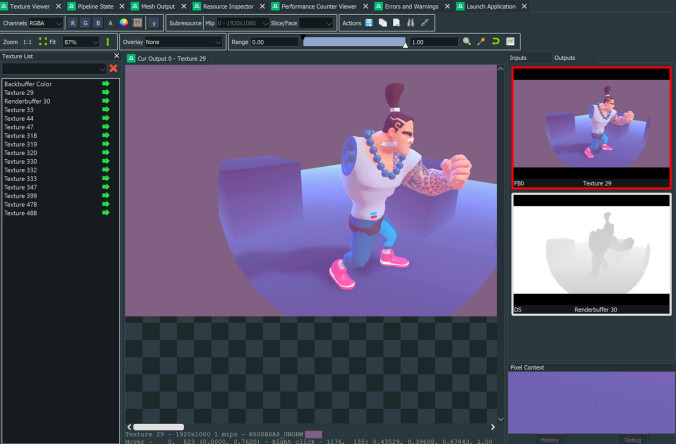
如下图所示,XCode是MacOS上的首选开发应用程序,我们可以通过在调试菜单选择选项,随时获取GPU帧信息。
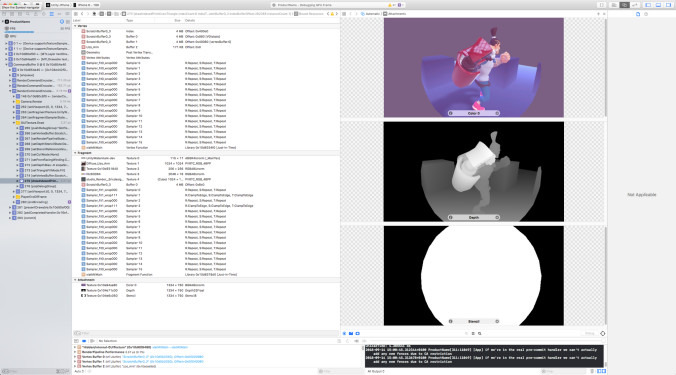
充分利用空间
通过对两个平台使用渲染目标查看器,我们发现阴影贴图渲染目标的内容只是整个纹理的一小部分。渲染目标中大概有超过50%的像素未被使用,这是对空间的极大浪费。
我们使用了投射阴影和定向光,正交投影模式往往更容易控制和调整。使用该模式可能会丢失一些方向,但这不算什么问题。我们把投影模式改为正交模式并调整好光源位置,从而更好地使用可用的渲染目标空间。
最后,我们可以把阴影贴图纹理的分辨率从128×128减少为64×64,即原始大小的1/4。移动设备的最大瓶颈之一是带宽,移动设备具有小型总线。在总线上减少75%的数据量会节省很多带宽,而且同时会减少75%的着色片段后,因此我们可以实现很大的性能增益效果。

多重采样抗锯齿
由于我们使用了较小渲染目标,在对象开始在渲染目标中移动时,我们会注意到大量锯齿现象。由于移动端GPU的工作方式,多重采样抗锯齿效果MSAA的开销很小。
移动端GPU使用了基于平铺的架构,所有抗锯齿工作都在芯片上完成,额外内存都在平铺内存上。通过使用4x MSAA和较小渲染纹理可以获得更好的结果,只需稍微增加处理开销。
渲染目标格式
我们的阴影贴图渲染纹理使用R8G8B8A8格式,而且仅使用了两个通道。第一个通道是R通道,用于存储阴影本身,第二个通道是G通道,用于存储线性衰减。我们的美术要求阴影强度随距离而衰减。
通过进一步研究发现,实际上并不需要存储这两个信息,我们只需要阴影值或衰减值,具体取决于为阴影投影对象启用的功能。我们把渲染目标格式改为8位单通道格式即R8格式,这样进一步减少1/4的纹理大小,而且大大降低带宽。
模糊方法
在给阴影贴图填充渲染纹理后,我们要使阴影贴图变得模糊。这样可以减少使用较小纹理时出现的瑕疵,同时呈现出柔和的阴影效果。
我们使用了3×3方块模糊,在每个像素有9个纹理采样。此外,我们之前没有使用带有半像素偏移的双线性滤镜。我们添加了该选项,使其仅采样周围边缘的像素和半像素偏移,这样使采样数量从9降低到5。
如下图所示,由左至右分别是原图、采样5模糊、采样9模糊。

通过使用纹理坐标,我们会从纹理采样体素。启用点过滤时,在两个体素之间采样会导致只有其中一个体素被采样。
由于启用了双线性过滤,GPU会线性混合两个体素,返回两个体素的平均值。如果我们添加额外的半像素偏移,我们能够以一个像素的开销采样两个像素。
减少算术逻辑单元指令
Unity不支持通用边界纹理包装模式,因此我们必须给模糊着色器添加逻辑,使它检查当前体素是否是边界体素,如果是的话,使它保持清晰效果。这样可以避免阴影在接收平面上变得模糊不清。
着色器代码使用内在函数Step来计算当前体素是否是边界体素。固有函数Step类似if语句,我通过调整这部分代码,使它改为使用floor函数,这样使算术逻辑单元数量从13减少为9。虽然看似不多,但在渲染纹理中对每个像素这样做时,优化效果会逐渐积累。
在编写着色器时,我们可以观察Unity的检视窗口。在检视窗口中,选中着色器时,单击“Compile and show code”按钮。这样会编译着色器代码,并在文本编辑器中打开它。
在编译后的着色器代码顶部,我们会看到着色器使用了多少算术逻辑单元和Tex指令。
// 统计:5次数学运算,5个纹理 Shader Disassembly: #version 100 #ifdef VERTEX
如果想要更多信息,我们可以下载并使用Mali Offline Shader Compiler。只需复制编译后的着色器代码,即#if VERTEX或#if FRAGMENT下的代码,把它保存到.vert或.frag格式的文件中即可。
我们可以通过编译器运行文件,它会展示我们着色器的统计信息。
malisc --vertex myshader.vert malisc --fragment myshader.frag
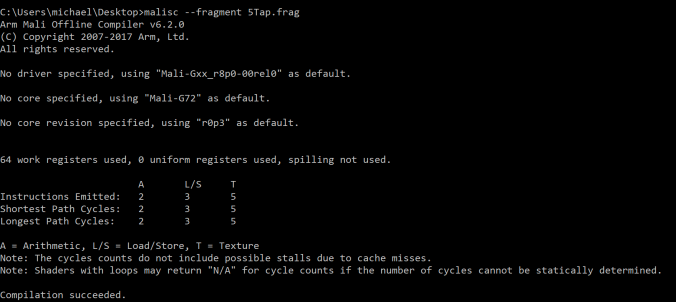
从上图中,我们发现名为5Tap的模糊着色器使用了:
• 2个算术逻辑单元指令
• 3个读取/存储指令
• 5个纹理指令
OnRenderImage函数
在模糊通道的结尾,我们发现还有一个额外的Blit函数,它会复制模糊纹理到另一个渲染目标。经过研究发现,即使我们指定模糊的渲染纹理为R8格式,它的格式依旧为R8G8B8A8,其实这是一个Bug。
OnRenderImage会传递32位的目标纹理,然后它的数值会复制到最终目标格式。这样是无法接受的,因此我们对管线进行了修改。
我们现在会手动分配渲染纹理,在OnPostRender函数中执行模糊过程。
private void OnPostRender()
{
if (shadowQuality != ShadowQuality.Hard)
{
SetupBlurMaterial();
blurTex.DiscardContents();
Graphics.Blit(shadowTex, blurTex, blurMat, 0);
}
}深度缓冲区
如果我们非常希望节省内存,可以禁用深度缓冲区,但这意味着色调的Overdraw增多。
如果我们清楚这对阴影贴图渲染目标产生什么影响,而且知道这不会产生过多Overdraw,那么可以考虑禁用深度缓冲区。
但是一定记得进行性能分析,并在禁用前确定自己是否真的很想要这些额外的几千字节空间。
性能指标
我们可以看到本文示例项目中渲染单个阴影贴图的开销。通过使用XCode GPU Frame Debugger对iPhone 6s进行测试,我们得到了下面的数据。
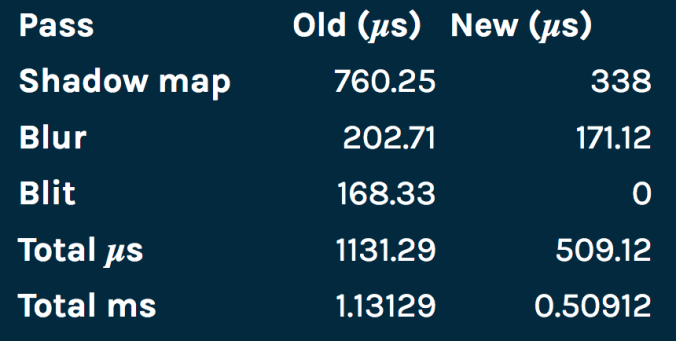
我们发现,渲染该阴影贴图的开销和原始开销相比,减少了50%。由于减少渲染目标的大小,使用较小纹理格式,去掉不必要的Blit函数,并且可以不使用深度缓冲区。
我们的内存消耗量从320kb减少为8kb,使用16位深度缓冲区会使内存消耗量变为16kb,节省了大量带宽。
小结
在最佳情况下,我们可以减少超过40倍的内存消耗和带宽使用量,还可以将阴影系统的整体开销降低50%以上。
这样的优化效果不意味着我们可以拥有两倍数量的阴影。所以我们花了2~3天进行性能分析,优化和修改,这些时间都是值得的。
本文转自:Unity官方平台,作者:Michael Short,转载此文目的在于传递更多信息,版权归原作者所有。





