机器学习模型通常分为有监督和无监督学习算法。当我们定义(标记)参数时创建监督模型,包括相关的和独立的。相反,当我们没有定义(未标记)参数时,使用无监督方法。在本文中,我们将关注一个特定的监督模型,称为随机森林,并将演示泰坦尼克号幸存者数据的基本用例。
在深入了解随机森林模型的细节之前,重要的是定义决策树、集成模型、Bootstrapping,这些对于理解随机森林模型至关重要。
决策树用于回归和分类问题。它们在视觉上像树一样流动,因此得名,在分类情况下,它们从树的根开始,然后根据变量结果进行二元拆分,直到到达叶节点并给出最终的二元结果。决策树的示例如下:
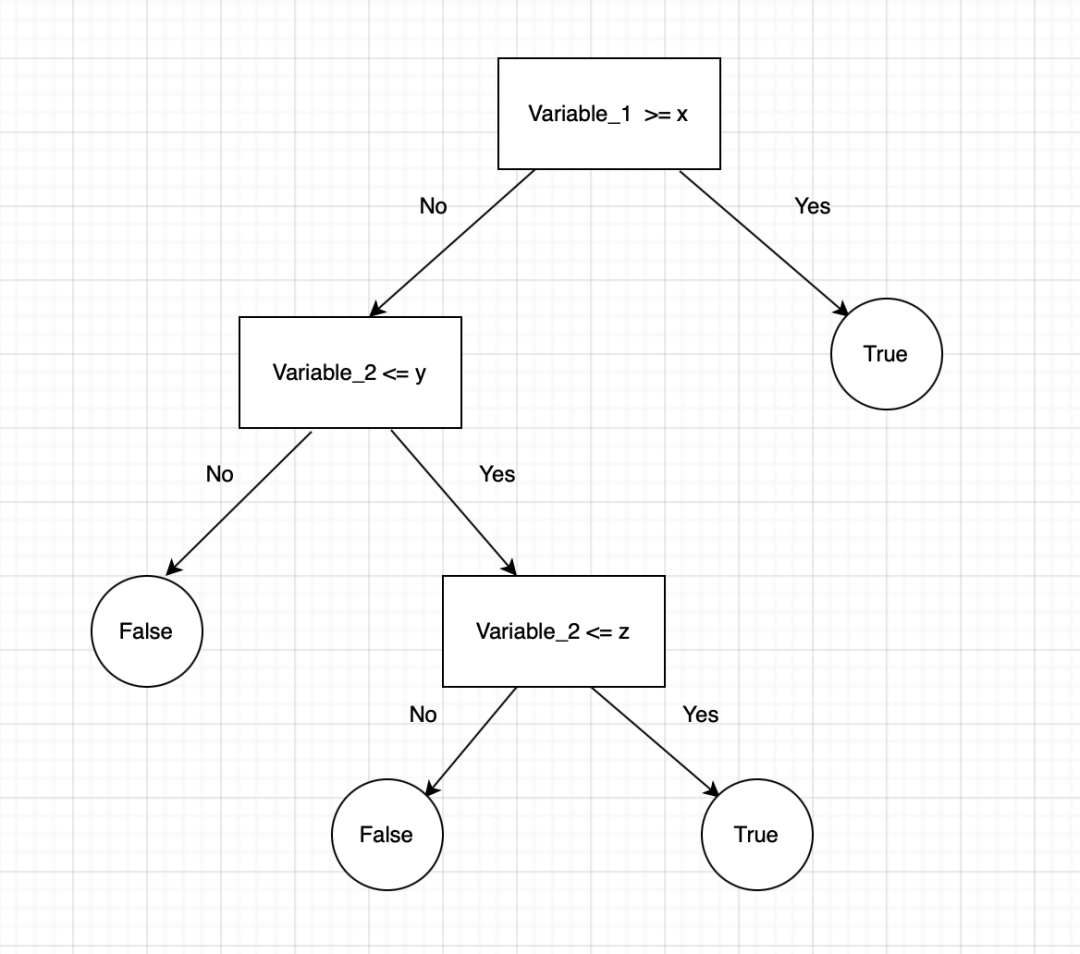
在这里,我们看到决策树从 Variable_1 开始,并根据特定标准进行拆分。当“是”时,决策树分类为 True(True-False 可以被视为任何二进制值,例如 1-0、Yes-No)。当“否”时,决策树下到下一个节点并重复该过程,直到决策树到达叶节点并决定结果。
集成学习是使用多个模型的过程,在相同的数据上进行训练,平均每个模型的结果,最终找到更强大的预测/分类结果。
Bootstrapping是在给定数量的迭代和给定数量的变量上随机抽样数据集子集的过程。然后将这些结果平均在一起以获得更强大的结果。Bootstrapping是应用集成模型的一个例子。
Bootstrapping随机森林算法将集成学习方法与决策树框架相结合,从数据中创建多个随机绘制的决策树,对结果进行平均以输出通常会导致强预测/分类的结果。
在本文中,我将演示一个随机森林模型,该模型是根据 Syed Hamza Ali 发布到 Kaggle 的泰坦尼克号幸存者数据创建的,该数据位于此处,该数据已获得 CC0 - Public Domain 的许可。该数据集提供有关乘客的信息,例如年龄、机票类别、性别以及乘客是否幸存的二元变量。这些数据也可以用来参加 Kaggle Titanic ML 比赛,所以本着保持比赛公平的精神,我不会展示我进行 EDA 和数据分析所采取的所有步骤,也不会直接发布代码。相反,我将提到一些一般概念和技巧,然后重点介绍随机森林模型。
EDA & Data Wrangling
进行 EDA 时面临的挑战之一是丢失数据。当我们处理缺失数据值时,我们有几个选项,我们可以用固定值填充缺失值,例如平均值、最小值、最大值。我们可以使用样本均值、标准差和分布类型生成值,以提供每个缺失值的估计值。第三种选择是只删除缺少数据的行(我通常不推荐这种方法)。其中一些选项的示例如下:
import pandas as pd
# 填充平均值
df.fillna(np.mean('column_name')
# 创建正态分布
np.random.normal(mean, standard_deviation, size= size_of_sample)此外,即使数据类型是整数,也必须将分类变量视为此类变量。这样做的一种常见方法称为单热编码,下面是其中的一个示例。
import pandas as pd pd.get_dummies(df, columns=['list_of_column_names'])
最后,重要的是要考虑到您拥有的某些变量可能在模型中没有用处。可以通过诸如正则化或根据您的经验和直觉做出的判断调用等方法来确定这些变量。出于直觉删除变量时要小心,因为您可能会错误地删除对模型实际上很重要的变量。
训练/测试拆分
我们将使用 sklearn 模块进行大部分分析,特别是在这个阶段,我们将使用该包的 train_test_split 函数来创建数据的单独训练集和测试集。对于一个完整的数据科学项目,我们还希望执行交叉验证并选择具有最佳结果的选项。但是,为了简单起见,我没有在本文中使用交叉验证,并将在以后的文章中讨论交叉验证和网格搜索。运行 train_test_split 的代码如下:
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = .25, random_state = 18)
传递给我们的 train_test_split 函数的参数是“X”,它包含我们的数据集变量而不是我们的结果变量,“y”是 X 中每个观察的数组或结果变量。test_size 参数决定数据的哪一部分将为测试数据集保留。在这种情况下,我选择了 0.25 或 25%。random_state 参数仅确定对数据进行的特定拆分,以便您以后可以复制结果。使用此功能后,我们现在拥有可用于模型训练和测试的数据集。
随机森林模型
我们将继续使用 sklearn 模块来训练我们的随机森林模型,特别是 RandomForestClassifier 函数。RandomForestClassifier 文档显示了我们可以为模型选择的许多不同参数。下面突出显示了一些重要参数:
- n_estimators — 您将在模型中运行的决策树的数量
- max_depth — 设置每棵树的最大可能深度
- max_features — 模型在确定拆分时将考虑的最大特征数
- bootstrapping — 默认值为 True,这意味着模型遵循bootstrapping原则(之前定义)。
- max_samples - 此参数假定bootstrapping设置为 True,如果不是,则此参数不适用。在 True 的情况下,此值设置每棵树的每个样本的最大大小。
其他重要参数是criterion、min_samples_split、min_samples_leaf、class_weights、n_jobs 和其他可以在 sklearn 的 RandomForestClassifier 文档中阅读的其他参数。
出于本文的目的,我将为这些参数选择基本值,而无需进行任何重大微调,以了解该算法的整体性能如何。使用的训练代码如下:
clf = RandomForestClassifier(n_estimators = 500, max_depth = 4, max_features = 3, bootstrap = True, random_state = 18).fit(x_train, y_train)
我选择的参数值为 n_estimators = 500,这意味着该模型运行了 500 棵树;max_depth = 4,因此每棵树的最大可能深度设置为 4;max_features = 3,因此每棵树中最多只能选择 3 个特征;bootstrap = True 再次,这是默认设置,但我想包含它以重申bootstrap如何应用于随机森林模型;最后是 random_state = 18。
我想再次强调,这些值是通过最少的微调和优化来选择的。本文的目的是演示随机森林分类模型,而不是获得最佳结果(尽管该模型的性能相对较好,我们很快就会看到)。
为了测试经过训练的模型,我们可以使用内部的“.predict”函数,将我们的测试数据集作为参数传递。我们还可以使用以下指标来查看我们的测试效果如何。
# Create our predictions prediction = clf.predict(x_test) # Create confusion matrix from sklearn.metrics import confusion_matrix, f1_score, accuracy_score confusion_matrix(y_test, prediction) # Display accuracy score accuracy_score(y_test, prediction) # Display F1 score f1_score(y_test,prediction)
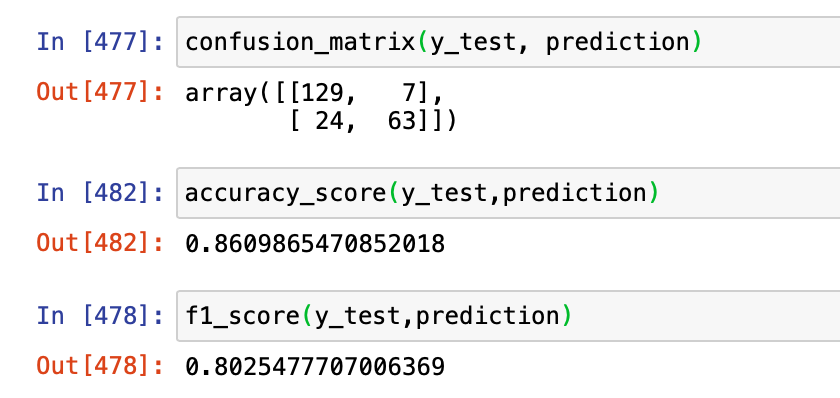
我们的模型提供了 86.1% 的准确度和 80.25% 的 F1 分数。
accuracy衡量为(TP + TN)/(所有样本)的总数,而 F1 分数由 2*((precision*recall)/(precision + recall))计算,precision = TP/(TP+FP), and recall = TP/(TP+FN).
通常,accuracy不是我们用来判断分类模型性能的指标,原因包括数据中可能存在的不平衡,由于对一类的预测不平衡而导致准确性高。但是,为了简单起见,我将其包含在上面。我还包括了 F1 分数,它衡量了precision和recall之间的调和平均值。F1 分数指标能够惩罚precision之间的巨大差异。一般来说,我们更愿意通过评估precision, recall, 和 F1的性能。
结论
本文的目的是介绍随机森林模型,描述sklearn的一些文档,并提供模型在实际数据上的示例。使用随机森林分类的accuracy得分为 86.1%,F1 得分为 80.25%。这些测试是使用正常的训练/测试拆分进行的,没有太多的参数调整。在以后的测试中,我们将在训练阶段包括交叉验证和网格搜索,以找到性能更好的模型。
原文:https://towardsdatascience.com/random-forest-classification-678e551462f5
本文转自:程序员zhenguo,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





