作者:黄烨锋,资深产业分析师
来源:电子工程专辑
随着HPC应用地位的日益攀升,GPU的受关注程度似乎达到了新高度。不过现在探讨的重点,更偏向于GPU在数据中心、汽车等设备之上的应用;毕竟手机、PC之类的消费电子产品近半年略有式微之感。不过原本,GPU在更多市场发挥作用也是当前的大趋势。
其中比较显著的一个议题,就是不只是手机之类的电池驱动型设备对元件功耗、能效有高要求,像数据中心这类原本对芯片功耗没那么敏感、更偏向高性能的场景,如今也在追求高能效,和算力密度(单位空间内所能提供的算力);以及如汽车电动化趋势之下,“续航里程焦虑”也让其中各类组件的功耗、能效变得尤为关键。负责图形乃至通用计算加速的GPU自然是其中之一;性能和功耗双方需要进一步得到兼顾。

最近Khronos & Imagination技术研讨会在上海举办,主体上还是围绕Khronos的API标准,以及Imagination的GPU IP展开的技术探讨。包括芯动科技、芯驰科技等在内的下游芯片设计企业,以及腾讯、字节跳动等应用端企业也参与了这次活动。
我们比较感兴趣的是,在应对当前GPU发展趋势的过程中,Imagination在技术层面都做了些什么。本次研讨会的多个议题实际上都着力于解答该问题。而Imagination对GPU架构和技术的呈现,也有利于我们进一步理解GPU技术现如今正在发生怎样的转变。
市场对GPU的新需求
Imagination对于GPU芯片当前的市场需求与趋势方面的总结大致上有下面这4点:
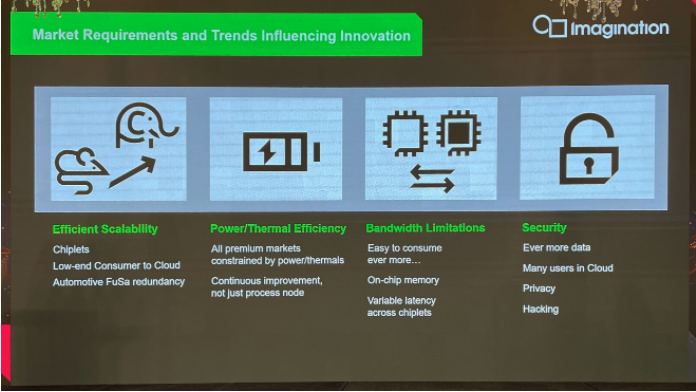
其一是扩展性、弹性(scalability)要求,从手机这样的小设备,到云数据中心规模级别的算力都覆盖——如果在芯片架构上能够提供对应的弹性,自然能够达成更高的芯片设计效率。这似乎也是当代几个比较主流的GPU供应商,在做架构设计时普遍考虑的问题。
这其中有一些对应的新技术和新需求涌现,例如chiplet、先进封装。汽车应用方向上,则有FuSa功能安全方面的需求——“不管冗余设计要求算两遍,还是某些功能失效后怎么办的问题,都需要考虑。”
第二,就是文首提到的能耗比、热效能、算力密度。不同方向的应用当前对“效率”都越来越看重,不同规模的设备都开始受到功耗、发热等方面的限制。这方面“我们不能单单以制造工艺的进步,来主导我们往前走。”
第三,则在于带宽方面的限制。主流冯诺依曼体系架构中,制约芯片性能的关键在数据存取和通信的过程中——这是能耗与热量开销的大头;另外在chiplet之类的新技术大规模应用之际,chiplet之间的数据同步、通信延迟等问题也都需要考虑进来。不过实际上,我们认为带宽问题也可以归属到第二点。Imagination将这一点单独拿出来谈,当与其GPU的TBDR架构有很大关系。
第四个新需求在安全(security)方面。尤其当GPU应用于云以后,GPU也成为安全链上的一环,硬件层面的安全支持也显得很重要。实际上像英伟达这样的GPU企业,这两年的GTC上也越来越多地去谈信息安全话题,亦能明确这方面的未来趋势。
IMG GPU的几个架构特色
针对这几个问题,Imagination在研讨会上给出了一些“方案”,或者说其PowerVR GPU IP产品现有的一些架构特性,是如何去满足市场需求的。对PowerVR比较熟的读者应该也都不会陌生。
首先是针对架构弹性扩展的问题,这一直以来都是Imagination的GPU特色:即模块化、层级化的方式,通过一种架构的弹性化扩展,覆盖从手机到服务器市场的各类需求。
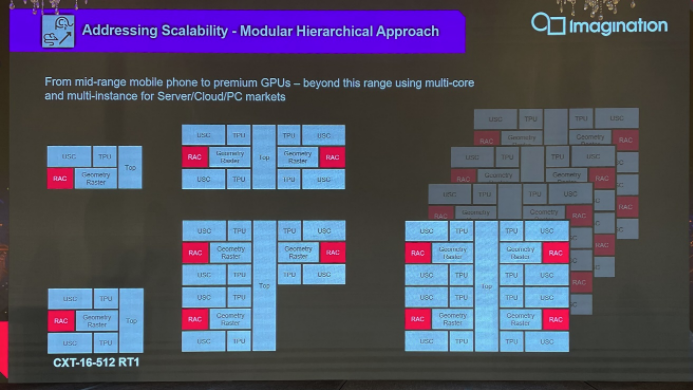
比如这一代CXT架构,如上图中左下的CXT-16-512 RT1(16 Pixels/Clock,512 FP32 FLOPs/Clock,1个RT核心),规模可以翻倍达成填充率、算力等性能成倍提升,直至4倍时形成单core——在有更高性能要求时还有多核的MC2-MC8不同规模版本;从多核再扩展到多实例(multi-instance)——多GPU卡应用于服务器和云市场。

Imagination表示,在具体设计上加上标准NOC片上网络技术,这样的弹性方案也很符合chiplet结构的需求——复用相同的模块,将多个模块以chiplet的方案封装到一起,形成更大的GPU。其关键点也在于避免采用过于中心化的逻辑,以及复杂信号设计,而采用相对松散、去中心化的结构,灵活性更好。
这种设计也在很多层面带来了好处,比如说硬件虚拟化、汽车功能安全的冗余设计,以及各chiplet之间的异步操作等等。
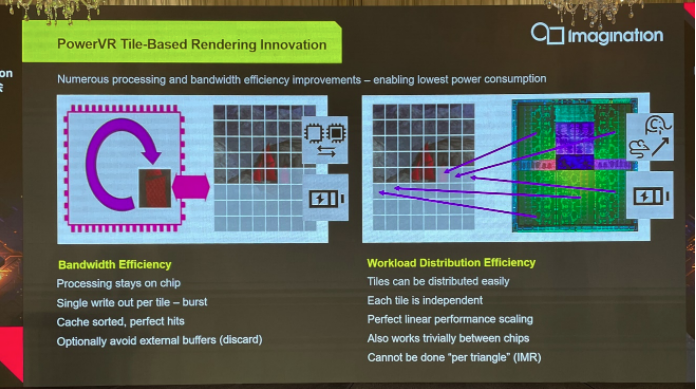
其次Imagination谈到了tile-based,也就是基于分块的渲染架构在满足当代GPU需求方面的优势。传统意义上,基于tile的渲染方式一直是移动领域的重要艺能,主要是考虑到移动设备的带宽、功耗等方面受到的限制都比较大。Imagination、苹果、Arm、高通的GPU方案都是基于tile的渲染方式。
着眼于前文提到不同应用市场对于带宽、功耗方面的新需求,这种基于tile的渲染方式在移动之外的市场也能延续效率上的显著优势。因为基于tile的处理方式,是在对对象做sort以后,以tile为单位做处理——如此一来不少处理过程就能在片内cache上做,也就提升了能效,降低了功耗;写出tile更加的"burst effective",对于cache与内存相关操作更友好。
另外基于tile渲染还有个优势,按照Imagination的说法,它天然地更适合弹性扩展。因为每个tile都是相对独立的,“也就有利于在多核或多设备之间分发这些tile,也有利于达成性能的线性scaling”。相对的“传统IMR(立即渲染模式)以三角形为单位的渲染方式”就无法达成这样的效果。

在tile-based基础上,接下来当然就要提到Imagination长久以来引以为傲的TBDR了,这其实一直也是Imagination对自家GPU IP的宣传点,如上图所示。在流程上同在采用TBDR的厂商主要还有苹果。藉由所谓的perfect tiling、culling,提升带宽利用率和整体效率也都算是TBDR的传统特色了。
当然其中有很多细节,比如说三角形binning精准地落到对应的tile之上,避免数据的overfetch;再比如更高效的场景中被遮挡三角形的抛弃、对于后面光栅化(rasterization)阶段贡献很低的小型三角形的抛弃等等,对于缩减带宽、功耗都是有价值的。
还有数据的硬件压缩也是缩减带宽需求的重要组成部分。
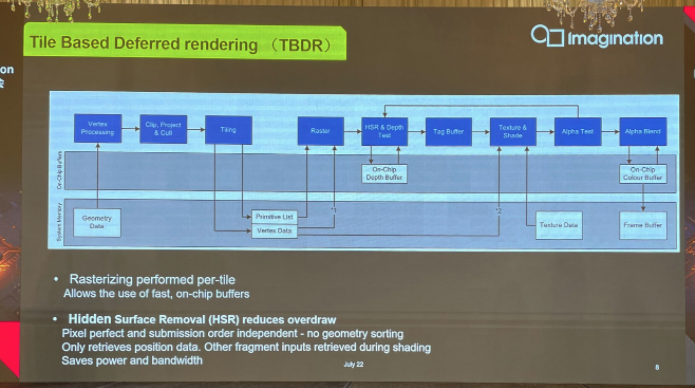
TBDR中的“D”是指“延后”渲染,在流程上和一般的TBR还是有不同。在tiling之后,primitive list和顶点数据是有一次写出的。“写出是要把tile list表达清楚,哪个三角形在对应的tile区域内,在这个环节表达清楚。在此之后,其他任务就相对独立,都在tile上面,通过on-chip memory来做HSR消隐等操作。”
尤其HSR(隐面消除)所在位置,一直都是Imagination这种TBDR结构提升效率的优势。本质也在于尽早抛弃不需要的部分,在后期阶段也就节约了不必要的资源开支。Imagination表示在考虑对框架做改进——在几何阶段,Imagination内部正考虑引入新的特性,以其令其更有利于多核GPU的任务分发,提升并行率;另外对于需要写出到系统内存的数据,“我们也在考虑,可以通过压缩来处理这几块buffer的data。”Imagination在主题演讲中谈到。
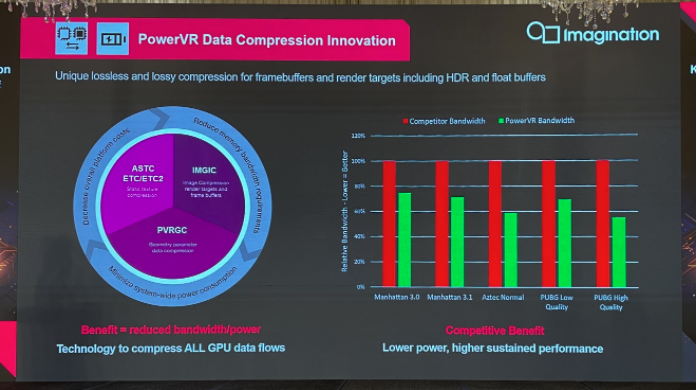
数据压缩也是节约带宽的重要技术。针对不同阶段、各种数据的压缩,Imagination形容“渲染里面几乎所有的data,都做压缩”。包括对开发者可见的纹理压缩以及无需开发者关心的几何压缩。
还有Imagination花了不少工夫的IMGIC,针对系统内存中render target的读写frame buffer image压缩——应当是Imagination在发布B系列GPU的时候引入的,用于替代此前逐渐不再有优势的PVRIC。无损和有损压缩均支持:对于有损压缩,据说能够在对质量仅有轻微影响的情况下,获得非常大的压缩比。
Imagination表示,相比于市面上的竞争对手,其GPU可达成20-40%的带宽节约——上图的测试场景和游戏中都有所体现。带宽需求更低,也就意味着能够提供更好的持续性能或者更低的功耗。

顺应时代发展趋势,GPU从硬件层面开始注重安全以及虚拟化特性。上面这张图的例子是当GPU应用于汽车之时——当代座舱内就有好几块屏幕,用途各异——它们在系统内可能会由同一个GPU来驱动。那么虚拟化在此就能发挥作用,包括从操作系统层级来做性能负载的分配。
还有负载的安全和隔离——比如仪表盘、导航、娱乐系统都跑在一个GPU上,则在某个系统崩溃时不会影响到仪表盘,即功能安全相关负载——GPU在此就是将使用场景,在硬件级上实现切分。另外在其他一些使用场景上,比如手机之上,对应的特性就能对神经网络加速,和UI特性做到资源均衡分配。当然还有在云服务器上,硬件虚拟化多租户也是十分必要的特性。
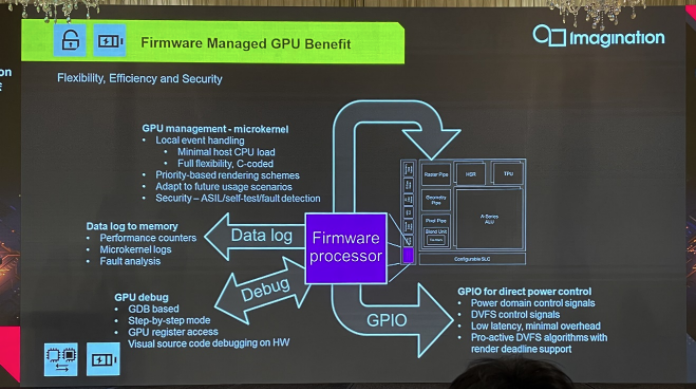
最后一个亮点特性,在于其firmware processor固件处理器上。前年我们细谈Imagination的A系列GPU微架构时,就特别谈到过当时架构改进中新增的这个“固件功能”。这次的研讨会上,固件功能也被当做一个重点做了介绍。
基于其可编程性,这个processor可以帮助降低主CPU的负载开销。“渲染的时候,有很多中断信号或申请信号,就不需要回到主CPU去,这个小的CPU也能响应。”固件功能也能做到虚拟化隔离,“我们甚至能够做到每一个USC给某一个应用来用。”
另外,不少复杂调度、安全、保护特性需要这样的固件功能。应对未来的新需求,自然也能通过固件来做调整。而且其可编程可扩展性,就令其很适用于调试,当GPU崩溃时能够给出完整的数据log。所以这对于功能安全的错误分析也就很有帮助。而在上面跑个debugserver,连接GDB来做debug,就是个不错的debug工具。
与此同时“firmware其实知道GPU里面的不少信息,包括寄存信息、memory信息、当前绘制的workload信息——基于此可以和外部设备做交互。”通过GPIO口进行电源管理。“firmware处理器知道GPU有多忙,那么我们就能快速高效地,在硬件上原生实施DVFS机制。”“所以总的来说,在带宽效率、能耗比以及安全方面,它都能带来帮助。”
以光追架构为例
如果要用一个词来总结Imagination当前做GPU IP的理念的话,应该就是“efficiency”(效率)了,所以Imagination才会在研讨会上反复强调能效、算力密度、带宽效率这些词。
我们倒是觉得,如果要举一个具体的例子的话,则Imagination的光追技术及架构应该是能够代表对“效率”一词的贯彻的。不过受限于篇幅,最后只能再简单谈一谈。

Imagination在技术白皮书里谈到过,他们将光追实现分成了6个等级,此前我们详细撰文探讨过。除了L0是早年各自为政的技术探索、L1是从软件层面来做光追、L2部分加入硬件专门的支持(ray-box与ray-triangle相交处理问题),L3往后实则是我们现在普遍理解中的光线追踪技术。
L2、L3把光线遍历、追踪和监控算法通过专门的硬件来实现,在性能和效率上有了成倍提升。关键是这里的L4:Imagination认为L4是要在L3硬件实现的基础上,给BVH(bounding volume hierarchy,层次包围体)处理再加个“Coherency Sorting”。
因为在Imagination看来,要在对功耗非常敏感的移动平台上实践光线追踪,还需要更进一步提升效率。考虑光线穿过BVH有不同的路径,需要频繁进行内存访问,不同路径又与不同三角形相交加重了shader的工作量。所以这里coherency sorting的意义在于对具有相干性的光线进行sorting——比如某些材质反射同方向光线做分组,来达成更高的数据复用、提升并行ALU管线利用率。
在Imagination看来,coherency sorting之于光线追踪,就相当于tile-based rendering对于GPU效率的意义。这一点实则是能够看出Imagination在GPU IP上对“efficiency”一词的贯彻的。
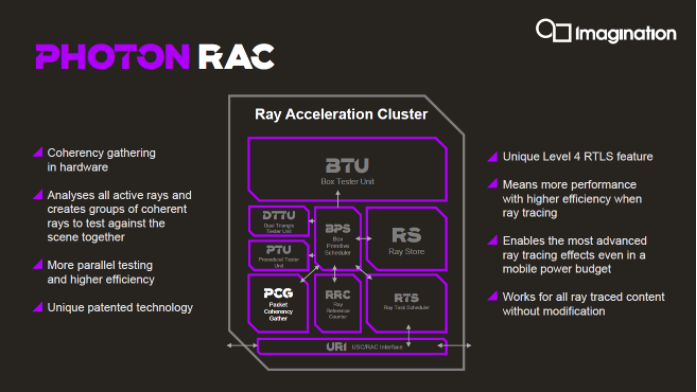
上面这张图是Imagination当前光追的硬件实现:一个RAC光追单元簇,由以上这些主要的单元模块构成。光追L4实现就在其中的PCG(packet coherency gathering)单元上:它会对所有活跃光线做分析,然后对“相干”光线做分组。
这也是Imagination眼中,未来手机这类功耗受限的设备上实现光追的必行之策。而且这个特性是不需要开发者去关心的。
Imagination表示,相比于市面上的其他解决方案,这种光追架构能够在光追负载上最多达成2.5倍的效率领先。

另外,前文提到的各种技术特性实则都能在Imagination的光追架构上有所体现。比如弹性扩展方案:此处GPU的基本单元是其中的SPU。RAC作为光追单元簇也是包含其中,并可做扩展的——两个ALU引擎共享一个RAC。而SPU本身也包含了其他完整的固定功能单元。
Imagination在推行高能效GPU一事上的思路还是相当清晰的,虽说研讨会上谈到的不少技术仍有偏向自家架构和技术的意思,不过大方向的确没错。即不只是手机这样的移动设备,包括PC、汽车、数据中心、云等不同规模GPU算力需求的设备和应用场景都会越来越看重效率——不管是带宽效率、算力密度还是整体能效比。
这就要求在架构层面有可扩展的弹性设计、各种能够节约带宽资源和提升效率的技术,再加上符合现代GPU发展需求的新特性:如安全、虚拟化。不管达成这些目标的具体技术是不是基于tile的、延后渲染的,或者各类数据压缩方案,未来市场对GPU的技术需求都将是如此。
本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有。





