当前,人工智能(AI)应用在我们的生活中越来越多地出现,比如出行安检中的人证对比,商场和饭店里的服务机器人,以及一些新兴汽车的自动泊车功能,等等。这些AI应用的实现都离不开AI芯片的支持,因此近年来有越来越多的企业投身于AI芯片的研发,尤其在中国,一时间形成百花齐放之势。
Imagination Technologies作为一家半导体行业领先的底层IP技术公司,投身于AI领域已超过7年,先后发布了三代高性能AI加速器IP产品,助力众多SoC厂商实现了行业领先的AI处理功能。12月1日,在智东西主办的“GTIC 2020 AI芯片创新峰会”上,Imagination副总裁、中国区总经理刘国军表示,Imagination领先的技术能力和创新的IP产品可以助力从云到端的AI应用加速落地。

GTIC(Global Technology Innovation Conference)是由智东西(智一科技)从2016年开始主办的前沿科技峰会,本次AI芯片创新峰会已是其第七届会议。刘国军副总裁受邀出席本届峰会,并在“边缘端AI芯片加速规模化落地”板块发表“多核GPU与专用NNA推动从云到端侧智能应用”主题演讲,全面介绍了Imagination全新发布的B系列(B-Series)多核GPU和第四代神经网络加速器(Series4 NNA)IP产品。
“据ABI Research预测,AI训练芯片和推理芯片未来几年都呈明显上升趋势,尤其是推理芯片,预计到2024年,全球边缘推理和云端推理芯片市场规模将达到110亿美元。”刘国军指出,Imagination在11月全新推出的Series4 NNA可以满足从云到端的AI推理芯片对算力的高要求。
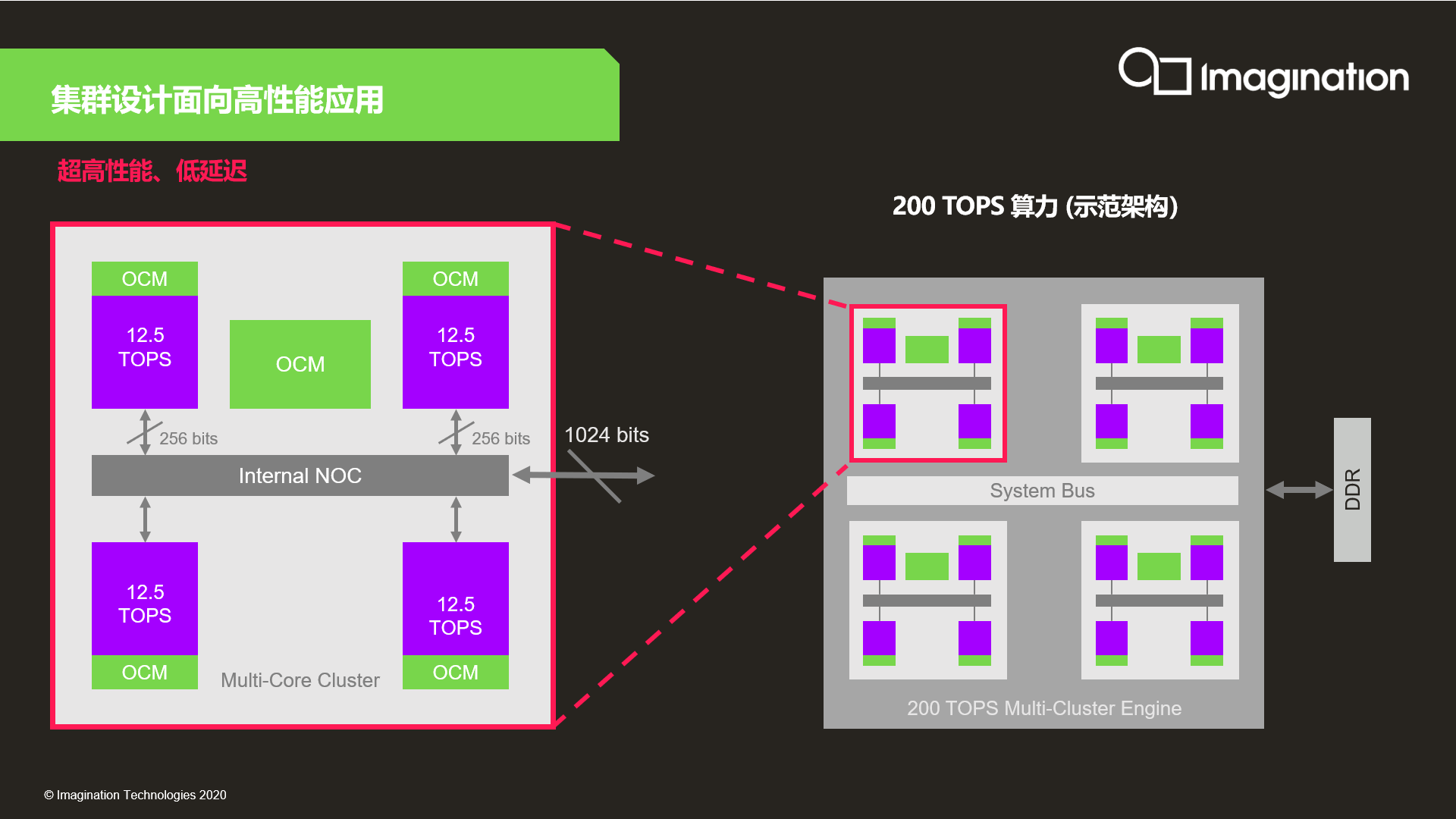
Series4的每个单核能以不到一瓦的功耗提供12.5 TOPS的算力,多核则可提供高达600 TOPS的算力(6个8核集群的解决方案)。在AI推理方面,Series4 NNA的性能比嵌入式GPU快20倍以上,比嵌入式CPU快1000倍,可以高效地助力物联网、消费电子、智能安防、自动驾驶、云计算等场景实现AI加速。
此外,Series4还可以凭借Imagination创新性的Tensor Tiling技术将任务在多个内核之间进行有效的划分,减少对外部存储的访问,从而将带宽需求降低多达90%。
除了发布全新一代NNA产品外,Imagination还在10月发布了最新的IMG B系列多核GPU,这是Imagination GPU技术的又一次重要演进。相比前几代产品,B系列功耗降低多达30%,带宽降低35%,面积缩减25%,旗舰款4核BXT GPU的算力可达6 TFLOPS,车用BXS GPU则完全符合ISO 26262车规功能安全标准。
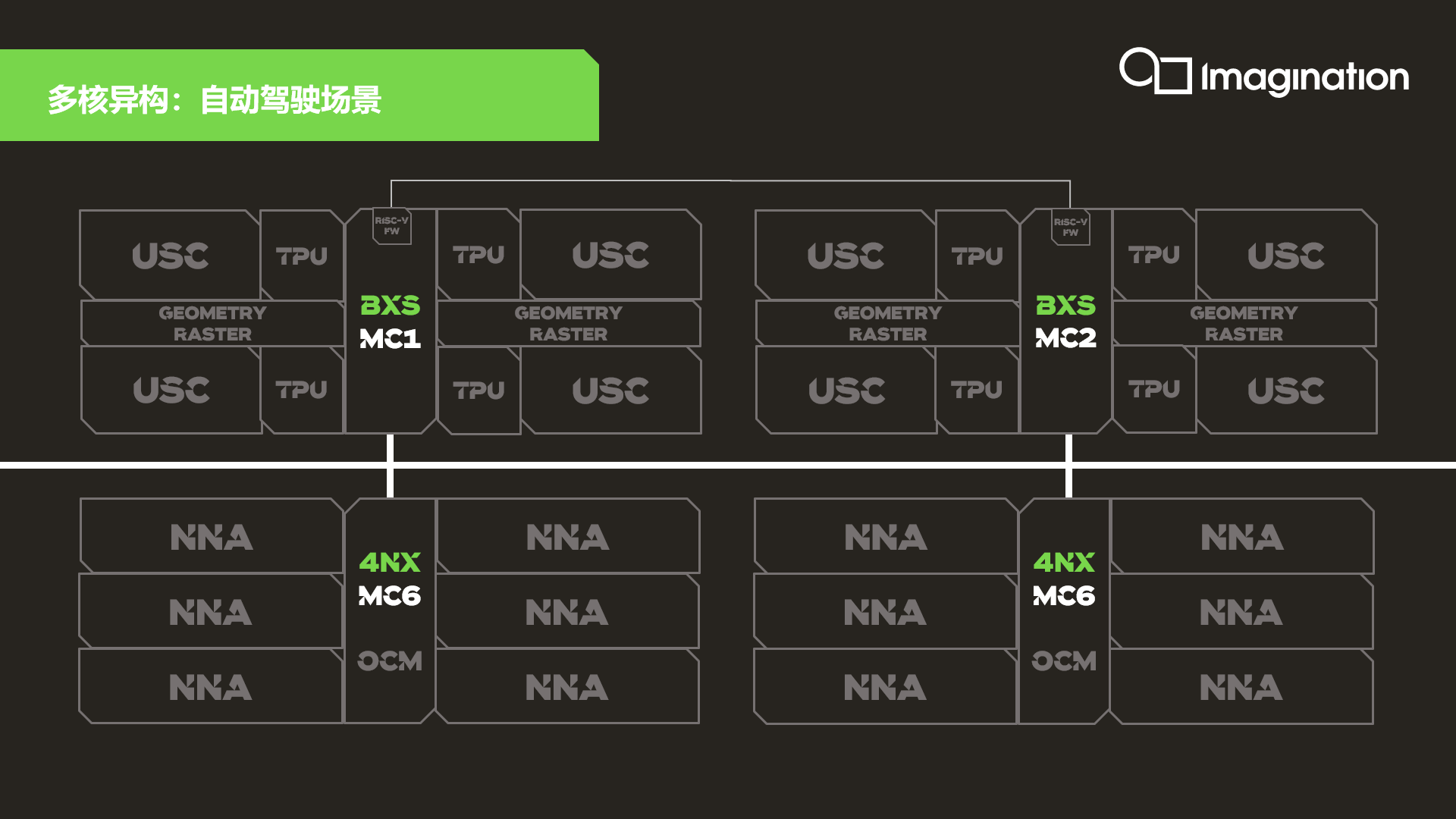
B系列GPU包括BXE、BXM、BXT和BXS四大类产品,共33种不同的配置,可以支持移动设备、消费类设备、物联网、数字电视、桌面、汽车、服务器等全应用场景,目前每类产品都已有授权客户,有的甚至已进入流片阶段。
“Imagination的NNA+GPU可以形成高效、普适的异构计算平台,兼具高算力和灵活性,而且二者可以共享统一的API接口和同一套开发工具,是众多智能化应用的完美解决方案。”刘国军表示。





