GAN是一个非常巧妙并且非常有用的模型。当有大量关于 GAN 的论文时,但是你会发现这些论文通常很难理解,你可能会想要一些对初学者更友好的东西。所以本文的对非传统机器学习人员来说,是我能想到的最好的例子。
什么是 GAN?
GANs 或 Generative Adversarial Networks 是一类机器学习技术,由两个网络组成,相互进行对抗性学习。
这一切都是为了创造。音乐?绘画?不存在的人的可怕逼真的照片?大声笑等等。
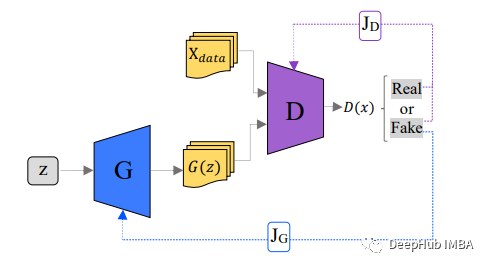
GAN中的网络一个被称为 Generator,可以将其视为一种伪造者,第二个称为 Discriminator,可以将其视为侦探。生成器的主要目标是生成逼真的图像,而鉴别器则试图区分真假图像。
假设生成器正在尝试创建猫的图片,而鉴别器必须确定它是真正的猫还是 AI 生成的。

它是如何工作的?
判别器和生成器都在开始时随机初始化并同时进行训练。开始时生成器只产生一些随机噪声,经过训练在创建逼真的图像方面越来越好,而鉴别器在区分它们方面越来越好。在模型达到平衡后,鉴别器就无法区分真实图像和假图像。在推理阶段,我们不再需要判别器,只是用生成器进行工作。
生成器试图最小化以下函数,而鉴别器试图最大化它:
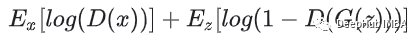
损失函数,D(y) 是判别器对真实数据实例 y 为真实的概率的估计。G(z) 是给定噪声 z 时生成器的输出。D(G(z)) 是鉴别器对假实例是真实的概率的估计。
简单来说,生成器目的是希望欺骗鉴别器让其相信输出是真实的,这意味着生成器的权重经过优化,以最大限度地提高此处任何假图像输出属于真实数据集的概率,而判别器应该最小化相同的概率。生成器不能直接影响函数中的 log(D(x)) 项,因此对于生成器来说最小化损失相当于最小化 log(1-D(G(z)))。
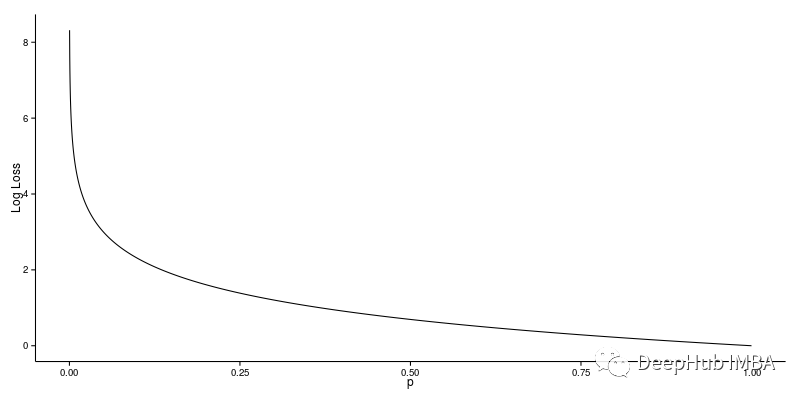
生成模型一般基于马尔可夫链、最大似然估计(maximum likelihood estimation, MLE)和近似推理,其似然值在区间[0,1]内。
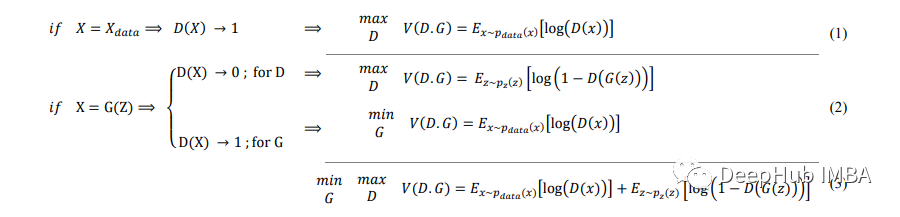
在均衡时D输出1/2,因为鉴别器不能区分生成的虚假数据和真实数据。
在无监督学习(数据没有标签)中,我们选择G生成的数据有0标签表示false(不管discriminator返回什么),真正的学习数据有1标签表示true。所以GAN的损失函数是下面这样的:
# Wasserstein losses from `Wasserstein GAN` (https://arxiv.org/abs/1701.07875).
def wasserstein_generator_loss(
discriminator_gen_outputs,
weights=1.0,
scope=None,
loss_collection=tf.compat.v1.GraphKeys.LOSSES,
reduction=tf.compat.v1.losses.Reduction.SUM_BY_NONZERO_WEIGHTS,
add_summaries=False):
"""Wasserstein generator loss for GANs.
See `Wasserstein GAN` (https://arxiv.org/abs/1701.07875) for more details.
Args:
discriminator_gen_outputs: Discriminator output on generated data. Expected
to be in the range of (-inf, inf).
weights: Optional `Tensor` whose rank is either 0, or the same rank as
`discriminator_gen_outputs`, and must be broadcastable to
`discriminator_gen_outputs` (i.e., all dimensions must be either `1`, or
the same as the corresponding dimension).
scope: The scope for the operations performed in computing the loss.
loss_collection: collection to which this loss will be added.
reduction: A `tf.losses.Reduction` to apply to loss.
add_summaries: Whether or not to add detailed summaries for the loss.
Returns:
A loss Tensor. The shape depends on `reduction`.
"""
with tf.compat.v1.name_scope(scope, 'generator_wasserstein_loss',
(discriminator_gen_outputs, weights)) as scope:
discriminator_gen_outputs = _to_float(discriminator_gen_outputs)
loss = - discriminator_gen_outputs
loss = tf.compat.v1.losses.compute_weighted_loss(loss, weights, scope,
loss_collection, reduction)
if add_summaries:
tf.compat.v1.summary.scalar('generator_wass_loss', loss)
return loss
def wasserstein_discriminator_loss(
discriminator_real_outputs,
discriminator_gen_outputs,
real_weights=1.0,
generated_weights=1.0,
scope=None,
loss_collection=tf.compat.v1.GraphKeys.LOSSES,
reduction=tf.compat.v1.losses.Reduction.SUM_BY_NONZERO_WEIGHTS,
add_summaries=False):
"""Wasserstein discriminator loss for GANs.
See `Wasserstein GAN` (https://arxiv.org/abs/1701.07875) for more details.
Args:
discriminator_real_outputs: Discriminator output on real data.
discriminator_gen_outputs: Discriminator output on generated data. Expected
to be in the range of (-inf, inf).
real_weights: Optional `Tensor` whose rank is either 0, or the same rank as
`discriminator_real_outputs`, and must be broadcastable to
`discriminator_real_outputs` (i.e., all dimensions must be either `1`, or
the same as the corresponding dimension).
generated_weights: Same as `real_weights`, but for
`discriminator_gen_outputs`.
scope: The scope for the operations performed in computing the loss.
loss_collection: collection to which this loss will be added.
reduction: A `tf.losses.Reduction` to apply to loss.
add_summaries: Whether or not to add summaries for the loss.
Returns:
A loss Tensor. The shape depends on `reduction`.
"""
with tf.compat.v1.name_scope(
scope, 'discriminator_wasserstein_loss',
(discriminator_real_outputs, discriminator_gen_outputs, real_weights,
generated_weights)) as scope:
discriminator_real_outputs = _to_float(discriminator_real_outputs)
discriminator_gen_outputs = _to_float(discriminator_gen_outputs)
discriminator_real_outputs.shape.assert_is_compatible_with(
discriminator_gen_outputs.shape)
loss_on_generated = tf.compat.v1.losses.compute_weighted_loss(
discriminator_gen_outputs,
generated_weights,
scope,
loss_collection=None,
reduction=reduction)
loss_on_real = tf.compat.v1.losses.compute_weighted_loss(
discriminator_real_outputs,
real_weights,
scope,
loss_collection=None,
reduction=reduction)
loss = loss_on_generated - loss_on_real
tf.compat.v1.losses.add_loss(loss, loss_collection)
if add_summaries:
tf.compat.v1.summary.scalar('discriminator_gen_wass_loss',
loss_on_generated)
tf.compat.v1.summary.scalar('discriminator_real_wass_loss', loss_on_real)
tf.compat.v1.summary.scalar('discriminator_wass_loss', loss)
return
GAN 与以前的生成方法(例如变分自动编码器或受限玻尔兹曼机)相比,已经显示出令人印象深刻的改进。GAN在计算机视觉、信号处理、图像合成和编辑语音处理等各个领域已经有很多应用的例子,例如文本到图像的合成、图像到图像的翻译以及许多潜在的医学应用。
正因为如此,所以GAN也出现了很多变体,例如下图是 CycleGAN 做的一些很酷的事情

最后,如果你对GAN比较感兴趣,这里有个项目使用Pytorch实现了30多个GAN的经典论文,有兴趣的可以看看:
https://github.com/eriklindernoren/PyTorch-GAN
作者:Simran Sachdeva
本文转自:DeepHub IMBA,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





