人工智能正在攻克一个又一个的人类智力堡垒,这一次中招的是历史学领域。
在历史领域,经常会面对一些残缺的古籍。这些古籍记载了远古的文明,要了解历史就必须要解开这些谜团。

然而,要通过这些残缺的记忆碎片拼凑出整个完整的故事,并不容易。
比如下面这个,下面这段铭文记录了一个雅典卫城在公元前485或484年颁布的法令。但是,这段铭文很明显已经严重残缺不全了,缺失了大量的内容。历史学家、考古专家们的工作,就是要将这残缺不全的铭文恢复如初,其难度可想而知。

以前,这些工作靠的是专家们的专业知识和聪明才智。现在,这个工作可以交给AI系统了,并且他能做得更快更好。
近期,DeepMind与威尼斯大学人文系、牛津大学古典学院和雅典经济大学信息学系合作,探索机器学习如何帮助历史学家更好地解读这些残佚文本,从而让人们更深入地了解古代历史,并释放AI与历史学家之间的合作潜力。
在发表于《自然》杂志上的论文中,这些机构共同推出了名为伊萨卡(Ithaca)的AI,这是第一个可以恢复受损铭文缺失文本、识别其原始位置并确定其书写时间的深度神经网络AI。
目前,DeepMind已将伊萨卡的代码、训练前的模型等全部开源。
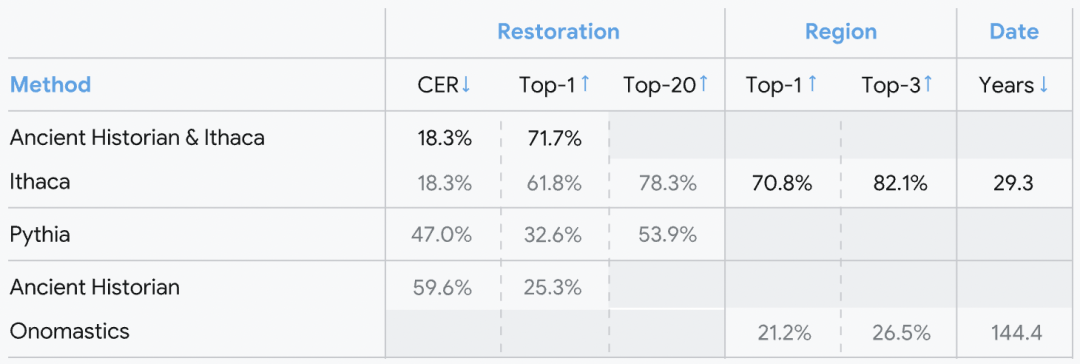
在测试集上对文本修复、地理(地区)和时间归属(日期)进行了评估
伊萨卡具体是怎么工作的呢?我们来看一个实际的例子。
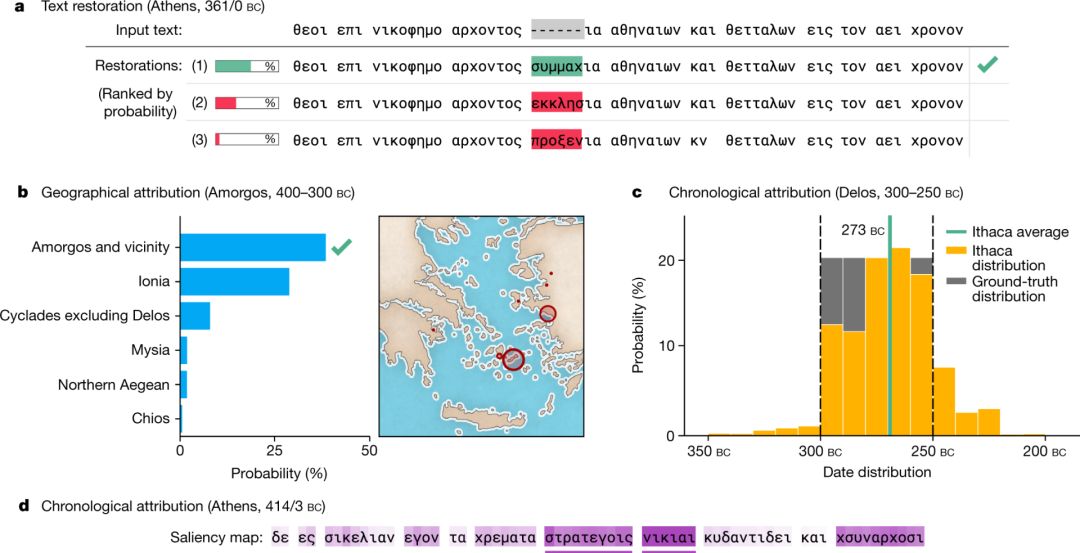
在这个例子中,伊萨卡进行如下的步骤:
对雅典铭文中6个缺失字符的修复预测,绿色表示正确的预测结果(συμμαχία,「联盟」)。注意这些字眼的预测输出(ἐκκλησία,「公民大会」;προξενία,「城邦与异邦人之间的条约」),被AI自动用红色标出。
来自阿摩尔戈斯的铭文的地域归属。伊萨卡的头一个预测是正确的,其他最接近的预测也在邻近地区。
德洛斯岛铭文的日期分布。公元前300-250年的真实日期区间为灰色;伊萨卡的预测分布为黄色,其平均值为公元前273年(绿色)。
伊萨卡AI将铭文句子中的个人姓名(Νικίας,尼基亚斯)和个人头衔(στρατεγοῖς,将军)自动变色标出。
伊萨卡是一种基于Transformer的人工神经网络,其数据训练集是帕卡德人文学院的希腊铭文文本数码库。这是世界上最大的古希腊铭文数据库,其中包含大约78,608条已解读好的古希腊铭文。
模型训练好之后,表现怎么样呢?出乎意料的好,把人类甩出了几条街那种程度。
在单独恢复受损文本方面,伊萨卡的字符错误率为26.3%,最确定预测结果的准确率达到了61.8%。别看没有达到100%,就觉得这个系统不行。事实上,这个成绩已经比单独人工预测的结果好2.2倍,也就是完胜人类了。
伊萨卡在识别铭文原始位置方面的准确率达到了70.8%,可以将文本的书写时间确定在其真实时间区间的平均值差异29.3年、中位值差异3年的范围内。作为对比,人工确定时间的精度是在真实时间区间的平均值差异144.4年、中位值差异94.5年的范围内。人类的表现,跟AI系统完全不在同一个级别,就好像小学生跟大学生的差别。
目前,DeepMind开发的这套AI古文修复系统还只适用于古希腊文。古希腊是西方文明的发源地,弄清楚了古希腊的历史和文明,就相当于搞清楚了西方国家的文明起源。
跟古希腊文明一样,我中华文明也是源远流长。中国也有大量的历史古籍遭到破坏,这些古籍也需要修复。既然AI系统在修复古希腊文献的时候很好用,那应该也可以用到中国古籍修复上啊。


要做到这件事情,有两个关键点,一个是算法,另一个是数据。
算法方面,需要针对中国古文的特点,开发出以神经网络算法为核心的AI系统。算法本身的好坏,将直接决定了AI系统的准确率。
除了要有核心算法外,还得有一个庞大的古文数据库。
DeepMind开发的AI系统伊萨卡之所以表现优秀,很重要的一个原因就是其用了世界上最大的古希腊铭文数据库——帕卡德人文学院的希腊铭文文本数码库。中国也需要尽快建立其古文的数据库,这个数据库要足够全,足够精准。用这个数据库训练出来的AI模型,才可能有很好的表现。
期待尽快看到这样的中文古籍AI修复系统,这可以让我们更好地了解中华民族的灿烂文明。





