原文作者:Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pierazzi, Christian Wressnegger, Lorenzo Cavallaro, Konrad Rieck
原文标题:Dos and Don'ts of Machine Learning in Computer Security
原文链接:https://arxiv.org/pdf/2010.09470.pdf
笔记作者:nerd@SecQuan
简介
该文主要研究了将机器学习方法应用在计算机安全领域中(恶意软件检测、二进制代码分析等)一些常见的陷阱。踩到这些陷阱会降低模型性能并使其难以有效部署。因此,在本篇论文中,作者通过对过去10年间30余篇安全顶会论文研究,系统性的总结出10种陷阱,并提出一些方法以帮助安全研究人员能尽量避开它们,促进机器学习方法在安全领域的设计、开发、应用、评估与部署。
缺陷
如下图所示,作者将一个安全问题从提出到给出解决方法抽象为6个步骤。刨除提出问题和问题解决,剩余四个主要流程:收集数据与打标签、系统设计与机器学习、表现评估、部署与操作中共存在10种陷阱可能导致结果失真或降低性能。

1. 样本偏差
如果样本数据的分布不能很好的反应出现安全问题的真实环境情况,那么很难从训练数据中得出有意义的结论。例如在网络入侵检测方法中,通常使用人工制造的攻击数据进行评估,这些攻击在评估数据集中出现的频率远高于现实环境。如下图所示,作者对某个网络入侵检测方法中使用的数据集进行分析,发现攻击流量十分明显,并且正常流量随着攻击开始而停止了。这样的训练样本会让模型在训练中学习到虚假的因果关系,降低其性能。
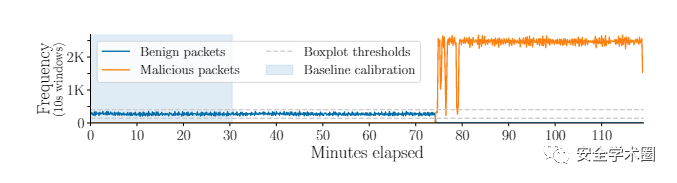
2. 标签不准
许多安全问题是使用机器学习中的分类模型解决的。为了训练这些模型,就需要给样本打标签,但是许多安全问题无法获得准确的标签(例如检测网络攻击和恶意软件)。因此,研究人员选用像VirusTotal这样的外部工具来打标签,这种操作在一定情况下是不可靠的。此外,攻击者手法的变化会引入新的标签或者造成不同种类标签之间的比例发生变化,这就使得真实情况与训练时的情况产生差异。不能适应这些变化的系统一旦部署就会出现性能下降。
3. 数据窥探
最基础的数据窥探就是无意中将测试集应用于与模型训练相关的某个步骤中,这相当于在一定程度上让模型“偷看了答案”,从而在实验评估中获得了更好的结果。此外,作者发现了另外两类更加隐瞒与微妙的数据窥探陷阱:时间窥探、选择性窥探。前者讲得是在训练时忽视了数据内部的时间特征,例如针对恶意软件数据集进行k-folds验证时,训练集中可能包括每个恶意软件家族的样本,但是对于老的软件家族来说,属于新家族的恶意软件相关数据应是未知的,因此不应该将未来的知识整合进来进行训练;后者讲得是在训练前,就将一些数据通过规则过滤掉。作者对数据窥探陷阱的细分可以参考下表。

4. 错误的因果关系
安全任务时常会使用具有不可解释特征空间来构建复杂学习模型,从而错误的因果关系。例如在某个希望通过学习编码风格从而识别代码归属的工作中,其数据采集自某项竞赛选手使用的代码。为了方便选手,竞赛组织者向选手提供了一些模板,导致模型通过这些模板内容对代码归属进行识别,而不是编码风格。
5. 参数偏向性
使用未校准的评价指标或者使用测试集指导参数设定会导致参数选择上的偏向性。另外,实验环境和真实环境的差异也会造成实验环境下选择的参数无法适应真实环境,导致性能下降。
6. 不合适的基线方法
简单的模型不一定不好,复杂的学习方法不仅会增加过度拟合的风险,还会增加运行时开销、攻击面、以及部署的时间和成本。同样,机器学习也不一定是解决安全问题的唯一方法。
7. 不合适的评价指标
不合适的评价指标选择可能会夸大事实,掩盖其真实水平。如下图所示,在一个不平衡数据集(1:100)上,仅从ROC曲线来看,性能表现出色,但精度低下却暴露了分类器的真实性能。
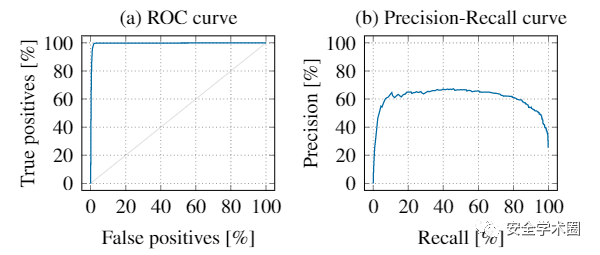
8. 基准比例谬误
与7相比,此陷阱重点在于对于结果的恰当解释。以上图中不平衡的数据集实验结果举例,是可能同时出现99%的真阳率和1%的假阳率,但是这样的指标实际上表明每检测出99个阳性样本,就会出现100个误报的阳性样本。实际上的性能并没有看上去那么好。
9. 只在实验环境下验证
许多基于机器学习来解决安全问题的方法仅在实验室环境中进行评估,夸大了它们的实际效果。
10. 模型威胁
这一陷阱表示在将机器学习方式应用到安全领域问题时,没有考虑模型本身存在的安全问题,例如其是否会遭到成员推理攻击、预处理攻击、数据投毒、后门攻击或者模型窃取的威胁。尤其是针对那些部署在真实环境下需要面临对抗性的系统,忽视模型自身的安全性问题所带来的影响是致命的,这些并不健壮的系统将无法提供值得信赖的、有意义的结果。
建议
针对上述10种陷阱,作者针对其所属的4个阶段分别给出了不同的建议。
1. 收集数据与打标签
尽量以真实环境中的比例来收集样本,如果实在无法贴合真实环境情况,应对真实的数据分布情况做出多种假设,并分别进行实验;使用迁移学习方法弥补在一个领域内难以采集足够数据的问题;谨慎地对待公开的数据集,应将其主要用于和过去方法的对比;尽可能地验证标签的真实性;不能简单地去除标签不确定的数据,应想办法进行处理;预防数据随时间变化而带来的标签偏移。
2. 系统设计与机器学习
使用可解释的机器学习技术以检查模型是否依赖于错误的因果关系;从最开始就严格区分训练集、验证集、测试集,防止测试集在任何阶段干预到系统的构建。
3. 表现评估
选择的评价指标应有助于从业人员在部署期间评估安全系统的性能;安全问题通常是围绕检测罕见事件展开,可以选择不受类不平衡影响的指标,如精确召回曲线;在选择基线对比方法时,需要考虑简单的机器学习模型(如线性分类器、朴素贝叶斯等)和非机器学习模型。
4. 部署与操作
应将系统部署于真实环境下观察在实验室环境下观察不到的问题,分析真实数据的复杂性与多样性以对系统进行调整;应假设基于机器学习的系统将面临对抗性的考验,考虑机器学习各个搭建步骤中可能存在漏洞;假设遭到白盒攻击这种最差的情况来做预案,搭建系统时遵守Kerckhoff原则。
总结
作者系统地评估了在安全领域中使用机器学习时可能遇到的10种微妙的陷阱。这些问题可能会严重影响研究的有效性并导致高估了安全系统的性能。其中部分偏向于学术上,是由于实验设计与操作存在瑕疵而产生问题,另一部分偏向工业界,是由于需要将机器学习方法落地于真实环境中而产生的问题。作者指出这些问题即使是在已发表的顶会论文中也很普遍存在,并举例验证了其会导致关键结果出现严重偏差。为了让安全研究人员能够避免这些陷阱,作者针对使用机器学习方法解决安全问题的4个主要阶段分别给出了一般性的建议。
本文转自: 安全学术圈,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





