Unity 近日发布了 Unity 计算机视觉数据集,该数据集将有效降低计算机视觉应用的开发成本,加快为制造业、零售业和安防行业训练人工智能(AI)的速度。计算机视觉方案提供商现在可以为其 AI 训练需求购买定制化的数据集,同时保证符合严格的隐私和监管标准。
对于人工智能训练来说合成数据非常重要,因为往往现实世界所收集的真实数据无法满足特定的条件或需求。比如隐私规定限制了真实数据的可用性,或规定了数据只能以何种方式被使用。合成数据的一种常见用途是用于预发布的产品测试,此时现实数据可能不存在或无法被测试人员获取。此外,机器学习需要大量的数据用于训练算法,这也有赖于合成数据。因为在现实生活中,尤其是在自动驾驶汽车行业,生成能够用于算法训练的数据非常昂贵。如今 Unity 已经推出了计算机视觉数据集,未来在获取用于人工智能和机器学习训练的高质量合成数据集上,成本将不再是障碍。
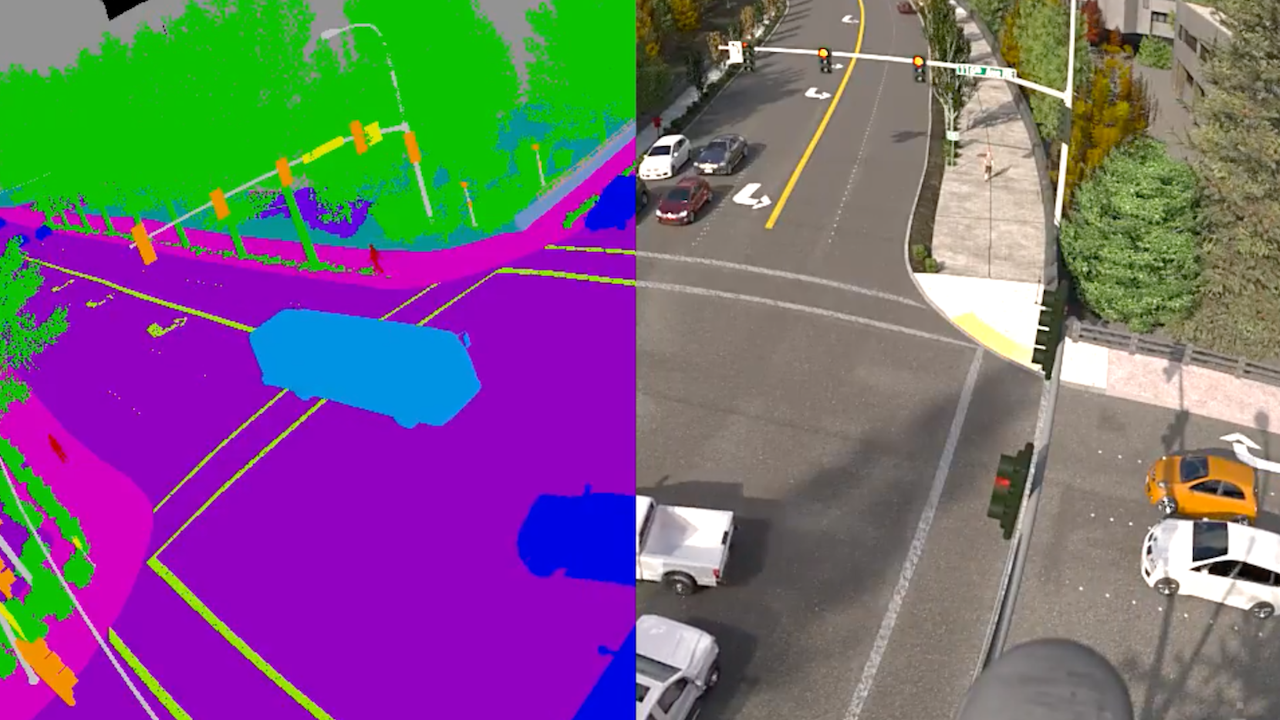
“通过提供符合隐私规定且如实反映真实世界的合成数据,我们能够让这些具有开创性的数据集为更多创新者所用。根本上来说,这些数据集能帮助企业规划和模拟尚未出现过的场景,甚至能够模拟真实世界的用户增长来不断调整训练数据。因此,随着客户应用领域的扩展,我们将能看到更智能的室内环境,比如全自助无人零售店等等。” Unity 人工智能和机器学习高级副总裁 Danny Lange 博士表示,“合成数据正在彻底改变机器学习模型的训练方式,它弥补了人工收集和标记真实世界数据的许多不足之处。我们正在探索一切可能性,帮助创作者们获取他们决策所需、并且负担得起的数据,推动 Unity 技术在各个领域的应用。这也是为什么我们推出这些数据集,并竭力帮助客户满足他们的需求。”
给物品“帖上”正确的标签

合成数据拥有诸多优势,但是上手可能并不轻松:该技术本身对许多机器学习从业者来说都略显新鲜,而为研究对象制作一整套的 3D 资源也是耗时耗力。
而由我们制作的 3D 资源皆为定制资源,每个导入 Unity 的数据集都会匹配模型的具体训练需求。有 3D 模型的,可转换成 CAD 模型,没有模型的,我们会使用先进的图像扫描技术来扫描现实物品,或交由专业艺术团队制作 3D 数字孪生。

在制作完 3D 模型后,我们再制定资源每帧上的行为、加上正确的标签。Unity 使用“域随机化”(domain randomization)技术来创建各种计算机视觉数据集,以此来提高数据质量并控制实际应用中的偏差值。在合成数据的过程中,该技术将对目标物体的位置和朝向进行各种排列组合,还有光照和摄像机角度的变化,以及可能实现的 Unity 环境的无数变量配置等。而且,Unity 的合成数据集还可以避免真实数据获取过程中可能存在的隐私违规或不可控的人工偏差。比如有些包含真实的人或地点的图像是直接从互联网上非法抓取的,或是花费大量人力从真实世界中拍摄获得。
动态的环境

数据集项目中的每个环境要素都可以随机化:光照、纹理、摄像机位置、镜头属性、信号噪波等等皆可改变,用多样化的数据集来应对最为广泛的用例。
在使用合成数据时,组成数据环境的背景并不一定要反映现实。部分计算机视觉的应用可能还需高度随机的背景,当然也有需要一定背景结构的情况存在,比如建筑或住宅内部。

我们团队已开发出一系列针对各种应用的无结构与结构化合成环境制作方法,专家们将针对不同的问题、情景和数据范围推荐环境类型。
数据集规模可大可小
不同的应用有不同的数据要求,图像的数量取决于场景复杂度、物品品类数和方案精确度。我们将深入理解客户的需求,帮助划定项目的框架,与客户多次交流来保证数据集达到标准。
我们计划在未来提供一个自助式接口,让用户能自行生成额外数据,不必再依赖 Unity 团队。
服务价格分为多个阶梯,不同数据量报价不同,帮助你掌控预算。对于真实世界的数据,标注的价格随着标注类型的复杂性而增加。Unity 则提供了一个适用于任何标签类型的较低价格,客户无论是为简单还是复杂的行业标准都将支付相同的标签价格,如 2D 和 3D 边框盒、类别分割和实例分割。合成数据集是按等级定价模型收费的,客户所需合成的图像数量越多,每幅图像的价格越低。
了解更多关于 Unity 人工智能数据集,请访问:
https://unity.com/products/computer-vision
本文转自: Unity官方平台,转载此文目的在于传递更多信息,版权归原作者所有。





