本篇的任务是回答:在Untiy的渲染流程中CPU和GPU分别做了什么。
渲染到设备屏幕显示的每一帧的画面,都经历几个阶段的加工过程:
应用程序阶段(CPU):识别出潜在可视的网格实例,并把他们及其材质提交给GPU以供渲染。
几何阶段(GPU):进行顶点变换等计算,并将三角形转换到齐次空间并进行裁剪。
光栅化阶段(GPU):把三角形转换为片元,并对片元执行着色。片元经过多种测试(深度测试,alpha测试等)之后,最终与帧缓冲混合。
CPU的工作流程:
CPU
① 准备好需要被渲染的对象。也就是哪些物体需要被渲染,哪些物体需要被剔除(culled),剔除的常用方式包括视锥体剔除和遮挡剔除,并对需要渲染的对象进行排序。
设置每个对象的渲染状态。渲染状态包括所使用的着色器、光源、材质等。
发送DrawCall。当给定一个DrawCall时,GPU会根据渲染状态和输入的顶点数据进行计算。
Unity的渲染顺序可以简单的理解为是从近到远(实际上要复杂的多)。根据渲染对象的排序,会为每一个渲染对象的每一个材质,生成一个渲染批次batch。在不考虑动态批处理和静态批处理的情况下,总的batch量就是每个渲染对象所包含的材质的总和。但是因为存在动态/静态批处理的情况,所以实际产生的batch数量要小于前面计算的总和。
在我一贯的测试过程中,SetPass call与渲染状态的切换是最吻合的,所以我将SetPass call简单的理解成设置渲染状态。但是,要说明的是,这只是我的个人想法,并没有其他支持。
SetPass call 和Draw call作为渲染命令队列的组成内容,担负着不同的任务。可以这样理解,SetPass call是告诉GPU接下来要用到哪些资源了,抓紧准备起来,而draw call则是把要求GPU根据顶点数据进行绘制。所以在执行SetPass call时,会向现存中传递大量的资源信息,包括纹理资源也是在这时候加载到缓存中,仅当下一个需要渲染的网格需要变更渲染状态时,才会产生SetPass call。所以,SetPass call和Draw call虽然是相伴产生的,但是两者却不一定对等。在某些情况下,一个batch可能会用到多个pass,比如mesh的反向描边。对于不同的pass,CPU将发送新的SetPass call 和Draw call。而在静态批处理中,因为顶点限制而不能在同一批次处理而被分割的紧邻的多个批次,因为使用的是相同的渲染设置,所以也只会产生一个SetPass call。
通常来说在优化时我们关注的是DrawCall,但也有不同的声音说,SetPass call更有意义。我觉得用哪个做分析从优化角度来说,差别不大。他们传递的都是指令和地址,真正耗时的是执行绘制阶段。并且两者的产生也基本是相伴的。
GPU的工作流程:
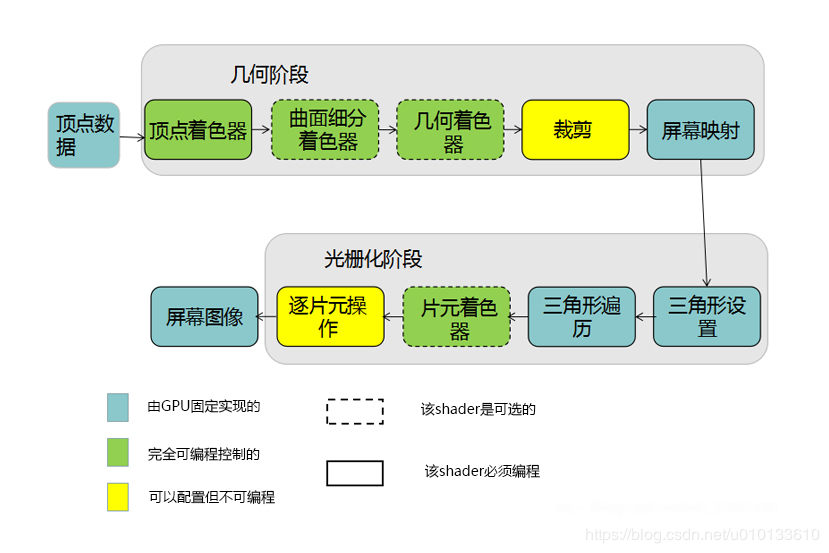
顶点着色器:
顶点着色器负责变换及着色/光照顶点。顶点着色器的输入来自于CPU,CPU输入的每个顶点都会执行一次顶点着色器,顶点着色器本身无法创建和销毁顶点,并且无法得到顶点与顶点之间的关系。正因为这样的独立关系,GPU可以利用自身的特性进行并行运算,所以顶点着色器的运算速度非常快。在此阶段也会进行透视投影、顶点光照、纹理计算、蒙皮。也可以通过修改顶点位置生成程序式动画(procedural animation),例如模拟风吹草动,碧波荡漾。
几何着色器:
几何着色器因为在手机端不支持,所以Unity开发程序员也许并不熟悉。几何着色器也是完全可编程的。几何着色器处理以齐次裁剪空间表示的整个图元(三角形,线段,点)。它能够剔除和修改输入的图元,也能生成新的图元。典型应用包括阴影的体积拉伸(shadow volume extrusion)、渲染立方体贴图(cube map)的六个面、在网格的轮廓边拉伸毛发(fur fin)、从点数据生成粒子四边形、动态镶嵌、把线段以分形细分(fractal subdivision)模拟闪电效果、布料模拟等。
裁剪:
最常用的裁剪设置是CULL OFF/BACK/FRONT,分别是不剔除/背面剔除/正面剔除。这里的正反面与摄像机没有一分钱的关系,而是通过法线方向决定的。
屏幕映射:
这里注意一点,虽然屏幕映射是玩家不可配置和编程的,但是屏幕分辨率确实玩家可以设置的,较小的屏幕分辨率对光栅化阶段是有非常重要的优化效果的。
三角形遍历:
三角形遍历阶段把三角形分解为片段(光栅化)。通常每个像素会产生一个片元,除非是使用MSAA,那么每个像素就会产生多个片元。三角形遍历也会对顶点属性进行插值,以生成每个片元的属性,供像素着色器使用。
片元着色器:
片元着色器是完全可编程的。其工作是为每个片元着色。片元着色器也能丢弃一些片元,例如根据透明度做剔除。像素着色器可以对多个纹理进行采样并计算逐像素光照和任何会影响片元颜色的计算。此阶段的输入是一组片元属性,这些属性是在三角形遍历阶段通过对顶点属性插值所得。输出则是一个颜色矢量。
逐片元操作:
该阶段也称为合并阶段(merge stage)或混合阶段(blending stage),NVIDIA称之为光栅化运算阶段(raster operations stage,ROP)。此阶段不可编程,但是可以高度配置化。最常用的逐片元操作测试包括深度测试ZTest、Alpha测试、模板测试Stencil test,当片元通过了所有测试以后,其颜色就会与帧缓冲原来的颜色进行混合(Blend),混合的方式是可配置的,如Blend One One。在该阶段另一个重要的配置是深度写入ZWrite。
版权声明:本文为CSDN博主「HelloMingo」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010133610/article/details/103389611





