深度学习中的技巧:
初始化参数尽量小一些,这样 softmax 的回归输出更加接近均匀分布,使得刚开始网络并不确信数据属于哪一类;另一方面从数值优化上看我们希望我们的参数具有一致的方差(一致的数量级),这样我们的梯度下降法下降也会更快。同时为了使每一层的激励值保持一定的方差,我们在初始化参数(不包括偏置项)的方差可以与输入神经元的平方根成反比
学习率(learning rate)的设置应该随着迭代次数的增加而减小,个人比较喜欢每迭代完一次epoch也就是整个数据过一遍,然后对学习率进行变化,这样能够保证每个样本得到了公平的对待
滑动平均模型,在训练的过程中不断的对参数求滑动平均这样能够更有效的保持稳定性,使其对当前参数更新不敏感。例如加动量项的随机梯度下降法就是在学习率上应用滑动平均模型。
在验证集上微小的提升未必可信,一个常用的准则是增加了30个以上的正确样本,能够比较确信算法有了一定的提升
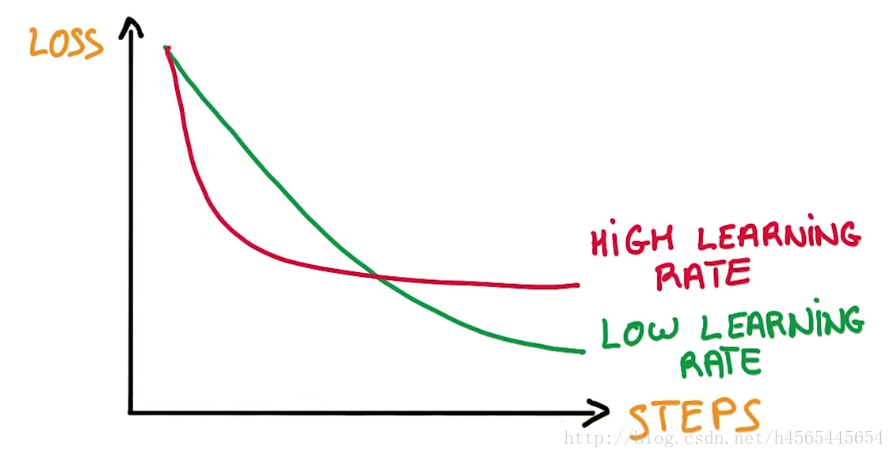
如上图所示,不要太相信模型开始的学习速度,这与最终的结果基本没有什么关系。一个低的学习速率往往能得到较好的模型。
在深度学习中,常用的防止过拟合的方法除了正则化,dropout和pooling之外,还有提前停止训练的方法——就是看到我们在验证集的上的正确率开始下降就停止训练。
当激活函数是RELU时,我们在初始化偏置项时,为了避免过多的死亡节点(激活值为0)一般可以初始化为一个较小的正值。
基于随机梯度下降的改进优化算法有很多种,在不熟悉调参的情况,建议使用Adam方法
训练过程不仅要观察训练集和测试集的loss是否下降、正确率是否提高,对于参数以及激活值的分布情况也要及时观察,要有一定的波动。
如果我们设计的网络不work,在训练集的正确率也很低的话,我们可以减小样本数量同时去掉正则化项,然后进行调参,如果正确率还是不高的话,就说明我们设计的网络结果可能有问题。
fine-tuning的时候,可以把新加层的学习率调高,重用层的学习率可以设置的相对较低。
在隐藏层的激活函数,tanh往往比sigmoid表现更好。
针对梯度爆炸的情况我们可以使用梯度截断来解决,尤其在RNN中由于存在相同的循环结构,导致相同参数矩阵的连乘,更加容易产生梯度爆炸。当然,使用LSTM和GRU等更加优化的模型往往是更好地选择。
正则化输入,也就是让特征都保持在0均值和1方差。(注意做特征变换时请保持训练集合测试集进行了相同的变化)
梯度检验:当我们的算法在训练出现问题而进行debug时,可以考虑使用近似的数值梯度和计算的梯度作比较检验梯度是否计算正确。
搜索超参数时针对经典的网格搜索方法,这里有两点可以改善的地方:
1)不用网格,用随机值,因为这样我们一次实验参数覆盖范围更广,尤其在参数对结果影响级别相差很大的情况下。
2)不同数量级的搜索密度是不一样的,不能均分。
卷积神经网络(CNN)中的独有技巧:
CNN中将一个大尺寸的卷积核可以分解为多层的小尺寸卷积核或者分成多层的一维卷积。这样能够减少参数增加非线性
CNN中的网络设计应该是逐渐减小图像尺寸,同时增加通道数,让空间信息转化为高阶抽象的特征信息。
CNN中可以利用Inception方法来提取不同抽象程度的高阶特征,用ResNet的思想来加深网络的层数。
CNN处理图像时,常常会对原图进行旋转、裁剪、亮度、色度、饱和度等变化以增大数据集增加鲁棒性。
版权声明:本文为CSDN博主「张月鹏」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/h4565445654/article/details/70477979





