主要的想法是:一个全新的模型框架,探索使用模型融合的方式将神经网络可解释同时化整为零将模型更加小巧化,训练更加迅速。
当处理不同类型的问题时,大脑在想什么?
在做知乎看山杯的文本标签(该问题可以理解为一个简单的文本主题分类问题,为一段话赋予一个主题,如篮球、情感、国际新闻、娱乐八卦等)的模型时,我遇到一个非常困惑的问题,就是无论我怎么调整nlp模型的结构,都不能对样本中冷门标签做好分类。
同时在其他数据集上时,当分类足够多,一些标签甚至开始互相影响,使用较深的模型抽象的标签(如情感、娱乐八卦)准确性更好;而使用规模较小的模型,则词语直接匹配的标签(如体育、军事)更加准确。
这些问题可能大家也司空见惯:第一个问题,原因是冷门标签太少。第二个问题人们通常使用异构的模型进行融合,弥补部分损失。
回想一下中学课堂里的场景,一个上午四节课不乏这样的插曲:在做完了一套数学练习课后紧接着开始了语文的文言文默写,大脑从数字及公式中立即跳跃到了唐宋元明清的时空。注意到这个时候你的大脑接收到的输入是一样的,同样是一样的文字,很显然你的大脑不会用诗词歌赋填充数学考卷上的空白,也不会尝试使用因式分解去解析李白的诗歌。
以往的模型融合无论是stacking还是bagging,都是在训练集全集随机抽样上进行训练,然后使用一个二级模型进行融合结果;或是像gbdt一样使用前面的tree预测结果,找出得分较低的结果对进行后续的tree训练。
而一个更合理的方案应该是根据输入信息判断该使用哪种模型。
前置路由的模型框架
综上所述,我们应该将选择模型前置,模型框架如下:
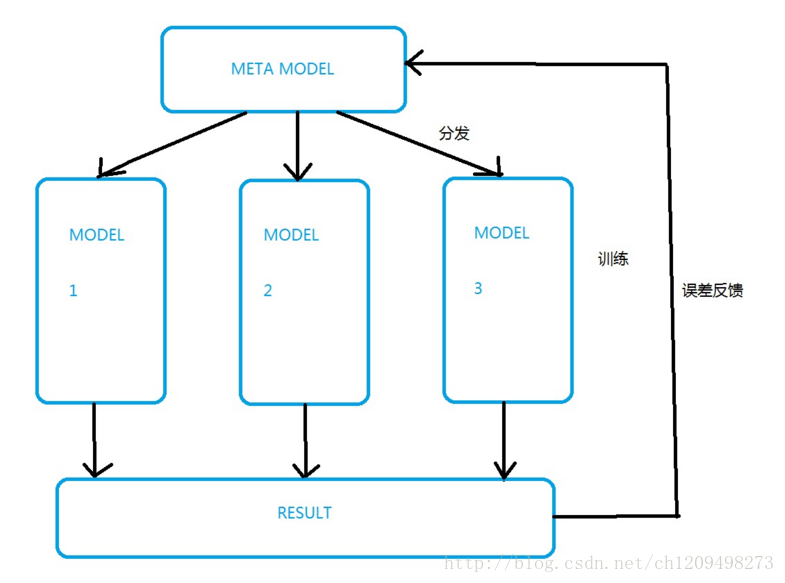
由一个Meta模型根据输入信息判断这个输入该由哪个子模型处理,然后把这条样本直接扔给相应子模型。
我选择了一个非常简单的案例,数据样本由两部分构成,一部分是3位数的加法计算、一部分是1位数乘法运算。并没有任何标志位标志出该条记录是加法还是乘法。这可以简单的模拟上文说的文本主题问题,模型首先需要判断文本属于哪个分类,才能更好的做细化判断。(当然文本分类不仅仅只有两大类)
模型的训练过程如下:
1.初始化meta模型以及子模型,训练集使用meta模型进行预测,然后使用softmax或sigmoid分给相应的子模型;
2.子模型训练自己分到的一批数据,并将训练结果的误差同时也反馈给meta模型,如果某条记录训练误差较大,meta下次则会降低它分到这个子模型的概率;
3.为了防止所有的数据倾斜在一个子模型里过拟合,meta模型的预测结果随机混入一定偏置,让所有样本都可能随机跳到不属于它的子模型。
看起来很简单,那么比起之前的融合方案或者一些hierarchy模型,这个体系的优势在哪呢?它是否work?首先放一下这个代码单个大模型和双模型的结果差距。各位可以自行改变line 165-line 166进行测试,默认是双子模型,如果想测试单模型只要删掉model2即可。
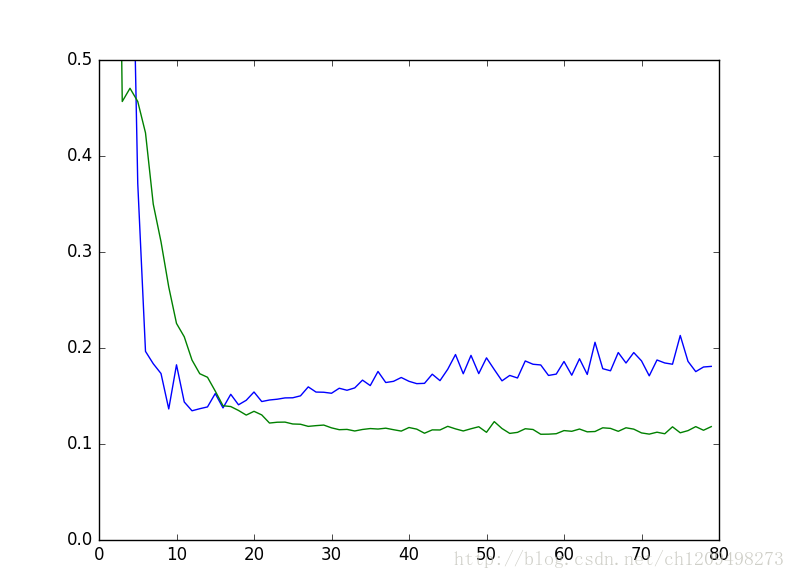
上图是当乘法与加法样本一样多时两个模型的误差,横坐标是迭代轮次,纵坐标是mape误差值。蓝线是单模型(该模型是绿线模型的两倍宽度)、绿线是有route效果的双模型。虽然是两个完全一样的子模型,但在这个体系下,它们自动完成了分工,分别分走了一半数据。可以看到双子模型不但没有过拟合现象,而且得分也高于单模型。
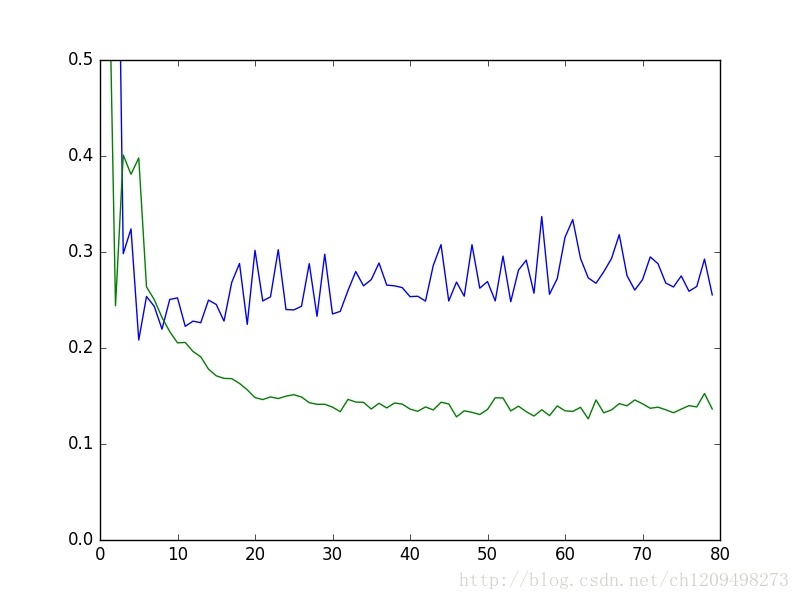
上图是当乘法与加法样本二比一时两个模型的mape误差。蓝线是单模型、绿线是有route效果的双模型。可以看到当不同的样本出现数据倾斜时,双子模型仍然没有降低预测效果,而单模型效果显著变差。有兴趣的朋友可以debug代码观察,meta模型很好的把两种输入分成给了两个子模型。
为什么单个模型不能处理好这部分问题呢,理论上说只要模型足够大足够深,神经网络不是应该也能很好的拟合训练集吗?原因就在于神经网络的训练方式是batch训练反馈机制,在单模型里你没有办法让对加法的样本进行加深学习而不影响计算乘法的神经元。所谓更深更大的神经网络像一个在舞台上叠罗汉顶着若干表演者保持平衡的演员,任何一点压力都会改变演员的节奏,拿掉任何一点配重就会坍塌。这也是我对神经网络最痛恨的一点,在这个系列连载中我会一点一点尝试将神经网络可控化。而在这个框架下,训练加法样本时乘法模型处于一个休眠状态,加法样本只会影响加法的模型。
这还仅仅两个完全一样的子模型的情况,在这个框架下,你甚至可以使用若干个异构的子模型,将合适的样本分给合适的模型,甚至放入一些gbdt或者规则子模型也无不可。无限可能。
不仅仅是同样输入的场景
是的,我想这个模型应该不止限于处理相同输入的数据集,在我的特征自然语言化一文中已经讨论过将一切输入自然语言化。不仅仅是加法和乘法,即使是数学和语文问题同时放入这个框架也未尝不可。
也许探索单个结构优秀的模型并不是一个正确的方向,而是应该使用大量自适应的小模型解决不同的问题。不同的样本进入时进行不同模块的学习过程,而不是每次训练都需求全量的样本,更加贴合人类学习的过程。至于子模型自适应性及管理训练,之后的更新会讨论。
一点总结
这一part虽然只讨论了一个前置的路由选择模型框架,但它是后续模型框架的核心,敬请期待后面的更新。
总结一下这个框架的几个显著优点:
1.初步的模型可解释,可以看到哪个模型训练了哪些样本;
2.样本的迭代训练,不再需要将所有的样本同时喂给一个模型,一定程度上可扩展性更加强大,gpu危机的拯救者;
3.效果更加优秀,至少不可能差于单模型。同时将端到端的神经网络与其他模型融合成为可能。
代码:https://github.com/white-bird/white-bird.github.io/blob/master/code/Y_1/...
版权声明:本文为CSDN博主「芦金宇」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ch1209498273/article/details/78526340





