本文由@浅墨_毛星云 出品,首发于知乎专栏,转载请注明出处。
文章链接: https://zhuanlan.zhihu.com/p/32928016
文中列举了渲染管线各个阶段中用到的几十种主流的优化策略。其中,个人印象比较深刻的优化方法有使用实例(Instance)结合层次细节和impostors方法来对多人同屏场景的渲染进行优化,以及使用纹理页(Texture Pages)来进行批次的尺寸最大化。
这篇文章会是《Real-Time Rendering 3rd》第十五章“Pipeline Optimization”和《GPU Gem I》第28章“Graphics Pipeline Performance”的一个结合,而不是之前一贯的《Real-Time Rendering 3rd》的单篇章节为主线。
需要吐槽的是,如果你对照阅读《GPU Gem I》的英文原版和中文翻译版,会发现中文翻译版中有一些不合理甚至曲解英文原文意思的地方,在第五部分性能与实这一部分尤其明显。
OK,正文开始。
一、渲染管线的构成
通常,可以将渲染管线的流程分为CPU和GPU两部分。下图显示了图形渲染管线的流程,可以发现,在GPU中存在许多并行运算的功能单元,本质上它们就像独立的专用处理器,其中存在许多可能产生瓶颈的地方。包括顶点和索引的取得、顶点着色(变换和照明,Transform & Lighting,即T&L)、片元着色和光栅操作( Raster Operations ,ROP)。
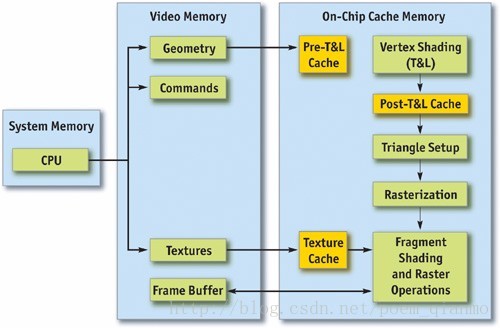
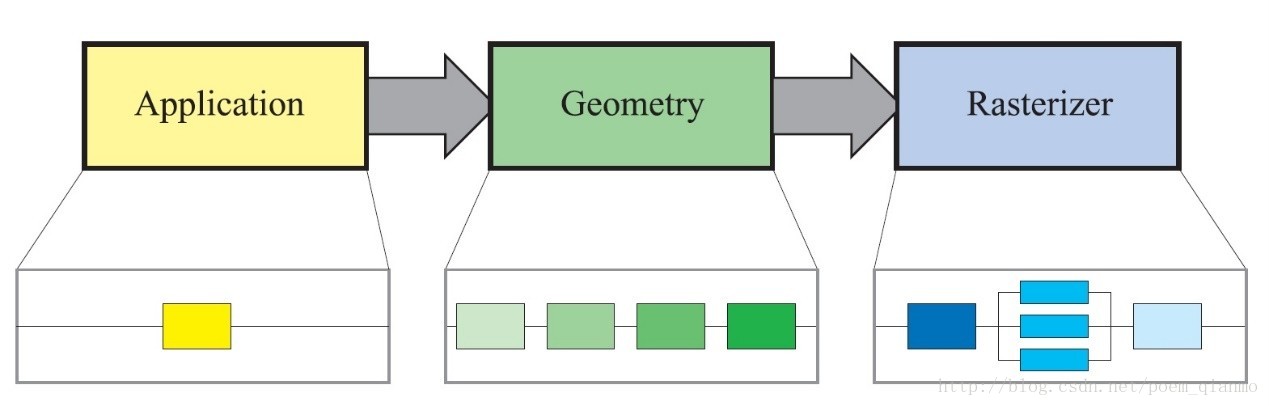
如《Real-Time Rendering 3rd》第二章所述, 图形的渲染过程基于由三个阶段组成的管线架构:
- 应用程序阶段(The Application Stage)
- 几何阶段(The Geometry Stage)
- 光栅化阶段(The Rasterizer Stage)
基于这样的管线架构,其中的任意一个阶段,或者他们之间的通信的最慢的部分,都可能成为性能上的瓶颈。瓶颈阶段会限制渲染过程中的整个吞吐量,从而影响总结渲染的性能,所以不难理解,瓶颈的部分便是进行优化的主要对象。
若有对渲染管线架构不太熟悉的朋友,具体可以移步回看这个系列的第二篇文章《【《Real-TimeRendering 3rd》 提炼总结】(二) 第二章 · 图形渲染管线 The Graphics Rendering Pipeline》:https://zhuanlan.zhihu.com/p/26527776
二、渲染管线的优化概览
准确定位瓶颈是渲染管线优化的关键一步。若没有很好确认瓶颈就进行盲目优化,将造成大量开发的工作的无谓浪费。
根据以往的优化经验,可以把优化的过程归纳为以下基本的确认和优化的循环:
- Step 1. 定位瓶颈。对于管线的每个阶段,改变它的负载或计算能力(即时钟速度)。如果性能发生了改变,即表示发现了一个瓶颈。
- Step 2. 进行优化。指定发生瓶颈的阶段,减小这个阶段的负载,直到性能不再改善,或者达到所需要的性能水平。
- Step 3. 重复。重复第1步和第2步,直到达到所需要的性能水平。
需要注意的是,在经过一次优化步骤后,瓶颈位置可能依然在优化前的位置,也可能不在。比较好的想法是,尽可能对瓶颈阶段进行优化,保证瓶颈位置能够转移到另外一个阶段。在这个阶段再次成为瓶颈之前,必须对其他阶段进行优化处理,这也是为什么不能在一个阶段上进行过多优化的原因。
同一帧画面中,瓶颈位置也有可能改变。由于某个时候要渲染很多细小的三角形,这个时候,几何阶段就可能是瓶颈;在画面后期,由于要覆盖屏幕的大部分三角形单元进行渲染,因此这时光栅阶段就可能成为瓶颈。因此,凡涉及渲染瓶颈问题,即是指画面中花费时间最多的阶段。
在使用管线结构的时候应该意识到,如果不能对最慢的阶段进行进一步优化,就要使其他阶段与最慢阶段的工作负载尽可能一样多(也就是既然都要等瓶颈阶段,不妨给其他阶段分配更多任务来改善最终的表现,反正是要等)。由于没有改变最慢阶段的速度,因此这样做并没有改变最终的整个性能。例如,假定应用程序阶段成为瓶颈,需要花费50ms,而其他阶段仅需要花费25ms。这意味着,在不改变管线渲染速度(50ms,即每秒20帧)的情况下,几何阶段和光栅化阶段可以在50ms内完成各自任务。这时,可以使用一个更高级的光照模型或者使用阴影和反射来提高真实感(在不增加应用程序阶段工作负载的前提下)。
管线优化的一种大致思路是,先将渲染速度最大化,然后使得非瓶颈部分和瓶颈部分消耗同样多的时间(如上文所述,这里的思想是,既然要等,不等白不等,不妨多给速度快的部分分配更多工作量,来达到更好的画面效果)。但这种想法已经不适于不少新架构,如XBOX 360,因其为自动加载平衡计算资源。
因为优化技术对于不同的架构有很大的不同,且不要过早地进行优化。在优化时,请牢记如下三句格言:
- “KNOW YOUR ARCHITECTURE(了解你所需优化的架构)”
- “Measure(去测量,用数据说话)”
- “We should forget about small efficiencies, say about 97% of the time: Premature optimization is the root of all evil.”(我们应该忘记一些小的效率,比如说97%的时间:过早的优化是万恶之源。)- Donald Knuth
OK,下面开始,本文的上篇,渲染管线的瓶颈定位。
三、上篇:渲染管线的瓶颈定位策略
正确定位到了瓶颈,优化工作就已完成了一半,因为可以针对管线上真正需要优化的地方有的放矢 。
提到瓶颈定位,很多人都会想到Profiler工具。Profiler工具可以提供API调用耗时的详细信息,由此可以知道哪些API调用是昂贵费时的,但不一定能准确地确定管道中哪些阶段正在减慢其余部分的速度。
确定瓶颈的方法除了用Profiler查看调用耗时的详细信息这种众所周知的方法外,也可以采用基于工作量变化的控制变量法。设置一系列测试,其中每个测试减少特定阶段执行的工作量。如果其中一个测试导致每秒帧数增加,则已经找到瓶颈阶段。
而上述方法的排除法也同样可行,即在不降低测试阶段的工作量的前提下减少其他阶段的工作量。如果性能没有改变,瓶颈就是工作负载没有改变的此阶段。
下图显示了一个确认瓶颈的流程图,描述了在应用程序中精确定位瓶颈所需要的一系列步骤。
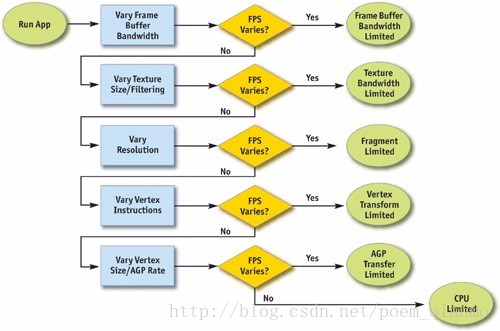
整个确认瓶颈的过程从渲染管线的尾端,光栅化阶段开始,经过帧缓冲区的操作(也称光栅操作),终于CPU(应用程序阶段)。虽然根据定义,某个图元(通常是一个三角形)只有一个瓶颈,但在帧的整个流程中瓶颈有可能改变。因此,修改流水线中多个节点的负载常常会影响性能。例如,少数多边形的天空包围盒经常受到片元着色或帧缓冲区存取的限制:只映射为屏幕上几个像素的蒙皮网络时常受到CPU或顶点处理的约束。因此,逐个物体地改变负载,或逐个材质地改变负载时常是有帮助的。
另外,管线的每个阶段都依赖于GPU频率(分为GPU Core Clock ,GPU核心频率,以及GPU Memory Lock,GPU显存频率),这个信息可以配合工具 PowerStrip(EnTech Taiwan 2003),减小相关的时钟速度,并在应用中观察性能的变化。
下文将按照按照优化定位的一般顺序(即上述图中的流程),按光栅化阶段、几何阶段、应用程序阶段的的顺序来依次介绍瓶颈定位的方法与要点。
3.1 光栅化阶段的瓶颈定位
众所周知,光栅化阶段由三个独立的阶段组成: 三角形设置,像素着色器程序,和光栅操作。
其中三角形设置阶段几乎不会是瓶颈,因为它只是将顶点连接成三角形。而测试光栅化操作是否是瓶颈的最简单方法是将颜色输出的位深度从32(或24)位减少到16位。如果帧速率大幅度增加,那么此阶段瓶颈。
一旦光栅化操作被排除,像素着色器程序的是否是瓶颈所在可以通过改变屏幕分辨率来测试。如果较低的屏幕分辨率导致帧速率明显上升,像素着色器则是瓶颈,至少在某些时候会是这样。当然,如果是渲染的是LOD系统,就需斟酌一下是否瓶颈确实是像素着色器了。
另一种方法与顶点着色器程序所采用的方法相同,可以添加更多的指令来查看对执行速度的影响。当然,也要确保这些额外的指示不会被编译器优化。
下文将对光栅化阶段三个常常可能是瓶颈的地方进行进一步论述。
3.1.1 光栅化操作的瓶颈定位
光栅化操作的瓶颈主要与帧缓冲带宽(Frame-Buffer Bandwidth)相关。众所周知,位于管线末端的光栅化操作(Raster
Operations,常被简称为ROP),用于深度缓冲和模板缓冲的读写、深度缓冲和模板缓冲比较,读写颜色,以及进行alpha 混合和测试。而光栅化操作中许多负载都加重了帧缓冲带宽负载。
测试帧缓冲带宽是否是瓶颈所在,比较好的办法是改变颜色缓冲的位深度,或深度缓冲的位深度(也可以同时改变两者)。如果此操作(比如将颜色缓冲或深度缓冲的深度位从32位减少到16位)明显地提高了性能,那么帧缓冲带宽必然是瓶颈所在。
另外,帧缓冲带宽也与GPU显存频率(GPU memory clock)有关,因此,修改该频率也可以帮助识别瓶颈。
3.1.2 纹理带宽的瓶颈定位
在内存中出现纹理读取请求时,就会消耗纹理带宽(Texture Bandwidth)。尽管现代GPU的纹理高速缓存设计旨在减少多余的内存请求,但纹理的存取依然会消耗大量的内存带宽。
在确认光栅化操作阶段是否是瓶颈所在时,修改纹理格式比修改帧缓冲区的格式更麻烦。所以,比较推荐使用大量正等级mipamap细节层次(LOD)的偏差,让纹理获取访问非常粗糙的mipmap金字塔级别,来有效地减小纹理尺寸。同样,如果此修改显著地改善性能,则意味着纹理带宽是瓶颈限制。
纹理带宽也与GPU显存频率相关。
3.1.3 片元着色的瓶颈定位
片元着色关系到产生一个片元的实际开销,与颜色和深度值有关。这就是运行”像素着色器(Pixel Shader )“或”片元着色器(Fragment Shader )“的开销。片元着色(Fragment shading)和帧缓冲带宽(Frame-Buffer Bandwidth)由于填充率(Fill Rate)的关系,经常在一起考虑,因为他们都与屏幕分辨率相关。尽管它们在管线中位于两个截然不同的阶段,区分两者的差别对有效优化至关重要。
在可编程片元处理的高级GPU出现之前,片元着色几乎没有什么局限性,时常是帧缓冲带宽引起的屏幕分辨率和性能之间不可避免的瓶颈。但随着开发者利用新的灵活性制造出一些新奇的像素,片元着色的性能问题也就出现了。
改变分辨率是确定片元着色是否为瓶颈的第一步。因为在上述光栅化操作步骤中,已经通过改换不同的深度缓冲位,排除了帧缓冲区带宽是瓶颈的可能性。所以,如果调整分辨率使得性能改变,片元着色就可能是瓶颈所在。而辅助的鉴别方法可以是修改片元长度,看这样是否会影响性能。但是要注意,不要添加可以被一些“聪明”的设备驱动轻松优化的指令。
片元着色的速度与GPU核心频率有关。
3.2 几何阶段的瓶颈定位
几何阶段是最难进行瓶颈定位的阶段。这是因为如果在这个阶段的工作负载发生了变化,那么其他阶段的一个或两个阶段的工作量也常常发生变化。为了避免这个问题,Cebenoyan [1] 提出了一系列的试验工作从光栅化阶段后的管线。
在几何阶段有两个主要区域可能出现瓶颈:顶点与索引传输( Vertex and
Index Transfer)和顶点变换阶段(Vertex Transformation Stage)。要看瓶颈是否是由于顶点数据传输的原因,可以增加顶点格式的大小。这可以通过每个顶点发送几个额外的纹理坐标来实现,例如。如果性能下降,这个部分就是瓶颈。
顶点变换是由顶点着色器或固定功能管线的转换和照明功能完成的。对于顶点着色器瓶颈, 测试包括使着色器程序更长。为了确保编译器没有优化这些附加指令,必须采取一些注意事项。对于固定功能管线,可以通过打开附加功能(如镜面高光)或将光源转换成更复杂的形式(例如聚光灯)来提高处理负荷。
下文将对几何阶段两个常可能是瓶颈的阶段的定位方法进行进一步论述。
3.2.1 顶点与索引传输的瓶颈定位
GPU渲染管线的第一步,是让GPU获取顶点和索引。而GPU获取顶点和索引的操作性能取决于顶点和索引的实际位置。其位置通常是在系统内存中(通过AGP或PCI Express总线传送到GPU),或在局部帧缓冲内存中。通常,在PC平台上,这取决于设备驱动程序而不是应用程序,而现代图形API允许应用程序提供使用提示,以帮助驱动程序选择正确的内存类型。
可以通过调整顶点格式的大小,来确定得到顶点或索引传输是否是应用程序的瓶颈。
如果数据放在系统内存内,得到顶点或索引的性能与AGP或PCI Express总线传输速率有关;如果数据位于局部缓冲内存,则与内存频率有关。
如果上述测试对性能都没有明显影响,那么顶点与索引传输阶段的瓶颈也可能位于CPU上。我们可以通过对CPU降频来确认这一事实,如果性能按比例进行变化,那么CPU就是瓶颈所在。
3.2.2 顶点变换的瓶颈定位
渲染管线中的顶点变换阶段(Vertex Transformation Stage)负责输入一组顶点属性(如模型空间位置、顶点法线、纹理坐标等等),以及生产一组适合裁剪和光栅化的属性(如齐次裁剪空间位置,顶点光照结果,纹理坐标等等)。当然,这个阶段的性能与每个顶点完成的工作,以及正在处理的顶点数量有关。
对于可编程的顶点变换,只要简单地改变顶点程序的长度,就能确定顶点处理是否是瓶颈。如果此时发生性能的变化,就可以判定顶点处理阶段是瓶颈所在。如上文提到过的,如果要增加指令,在添加富有意义的指令时需要留心,
以防止被编译器或驱动将指令优化掉。例如,因为驱动程序通常不知道程序编译时常量的值,没有被常量寄存器引用的空操作指令(no-ops)不能被优化(如加入一个含有值为零的常量寄存器)。
对于固定功能的顶点变换,判定瓶颈则有点麻烦。试着通过改变顶点的工作,例如修改镜面光照或纹理坐标生成的状态来修改负载。
另外需要注意,顶点处理的速度与GPU核心频率有关。
3.3 应用程序阶段的瓶颈定位
以下是应用程序阶段的瓶颈定位的一些策略的总结:
- 可以用Profiler工具查看CPU的占用情况。主要是看当前的程序是否使用了接近100%的CPU占用。比如AMD出品的Code
Analyst代码分析工具,可以对运行在CPU上的代码进行分析和优化。Intel也出品了一个称为Vtune的工具,可以分析在应用程序或驱动器(几何处理阶段)中时间花费的位置情况。 - 一种巧妙的方法是发送一些其他阶段工作量极小甚至根本不工作的数据。对于某些API而言,可以通过简单地使用一个空驱动器(就是指可以接受调用但不执行任何操作)来取代真实驱动器来完成。这就有效地限制了整个程序运行的速度,因为我们没有使用图形硬件,因此CPU始终是瓶颈。通过这个测试,我们可以了解在应用阶段没有运行的阶段有多大的改进空间。也就是说,请注意,使用空驱动程序还隐藏了由于驱动程序本身和阶段之间的通信所造成的瓶颈。
- 另一个更直接的方法是对CPU 进行降频( Underclock)。如果性能与CPU速率成正比,则应用程序的瓶颈与CPU相关。但需要注意,降频的方法可以帮助识别瓶颈,也有可能导致一个之前不是瓶颈的阶段成为瓶颈。
- 另外,则是排除法,如果GPU阶段没有瓶颈,那么CPU就一定是瓶颈所在。
来源:CSDN,作者:浅墨_毛星云,转载此文目的在于传递更多信息,版权归原作者所有。
原文:https://blog.csdn.net/poem_qianmo/article/details/79059583
版权声明:本文为博主原创文章,转载请附上博文链接!





