简介
NNLM是从语言模型出发(即计算概率角度),构建神经网络针对目标函数对模型进行最优化,训练的起点是使用神经网络去搭建语言模型实现词的预测任务,并且在优化过程后模型的副产品就是词向量。
进行神经网络模型的训练时,目标是进行词的概率预测,就是在词环境下,预测下一个该是什么词,目标函数如下式, 通过对网络训练一定程度后,最后的模型参数就可当成词向量使用。
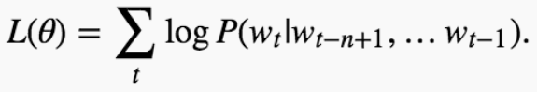
模型
NNLM的网络结构(四层神经网络)如右图,主要参数有:
[1]词库大小(假定有8W个词)
[2]转化的词向量大小(假定为300维长度)
[3]输入层神经元数(即词的滑动窗口容量,假定滑窗大小为4)
[4]隐层神经元数量(假定为100个)
[5]输出层神经元数(对应词容量,有8W个)
[6]由输入层到投影层的矩阵C(一个大的矩阵,大小为8W*300,是最后求解的目的,开始时随机初始化)
[7]从投影层到隐层的权值矩阵H和偏置矩阵B
[8]从隐层到输出层的权值矩阵U和偏置矩阵D
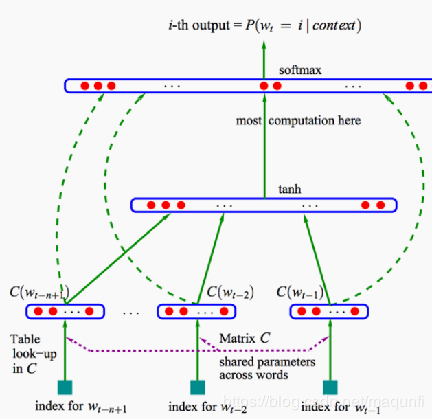
现在咱们针对NNLM模型,由下往上进行分析:
[1]每次从语料库中滑动4个数据,将其中前三个词转为one-hot编码形式,将三个one-hot形式作为输入喂入网络。
[2]从输入到映射层所做的事情是(one-hot向量 * 矩阵C),这里词的one-hot编码会根据为1的位置去对应C矩阵,去抽出对应位置的300维的词向量,将此向量作为投影层的输出。

[3]上一步投射层会将词的one-hot表示表示成300维的稠密向量,从投影层到隐层是一种全连接的连接方式,线的数量是3*100个,每个隐层神经元有3条线相连接,最后使用tan函数结合H与B获取激活输出。
[4]从隐层到输出层也是一直全连接的形式,连接线数量为100*8W,使用softmax函数结合U与D获取最后的概率输出。 [5]计算交叉熵损失函数值,以梯度下降方式进行反向传播,在反向传播过程中对参数矩阵C、H、B、U、D进行更新。
通过不断的喂入批次数据,对网络进行反向传播调参,最后训练出一个进行词预测任务的模型,并将训练好模型中的C矩阵里的每一列都作为,对应于one-hot编码中位置为1词的词向量(大小为1*300),这个词向量就是我们要转化的结果。
特点
优点:使用NNLM模型生成的词向量是可以自定义维度的,维度并不会因为新扩展词而发生改变,而且这里生成的词向量能够很好的根据特征距离度量词与词之间的相似性。
缺点:计算复杂度过大,参数较多(word2vec是一种改进)。
来源:CSDN,作者:马飞飞,转载此文目的在于传递更多信息,版权归原作者所有。
原文:https://blog.csdn.net/maqunfi/article/details/84455434
版权声明:本文为博主原创文章,转载请附上博文链接!





