出处:冲弱's Blog
早在上世纪50年代,美国神经生物学家David Hubel通过研究猫和猴子的瞳孔区域与大脑皮层神经元的对应关系就发现视觉系统的信息处理方式是分级的。这一发现,促成了神经网络在图像处理上的发展。
神经网络的发展史可以分为三个阶段,第一个阶段是Frank Rosenblatt提出的感知机模型[1],感知机模型的逻辑简单有效,但不能处理异或等非线性问题。第二个阶段是Rumelhart等提出的反向传播算法[2],该算法使用梯度更新权值,使多层神经网络的训练成为可能。第三个阶段得益于计算机硬件的发展和大数据时代的到来,促进了深度神经网络的发展。 卷积神经网络在图像处理上有着诸多突破性的进展。由于我对卷积神经网络较为熟悉,下面将根据神经网络的三个发展阶段阶段分析讨论卷积神经网络的发展史。
传统神经网络
感知机与多层网络
感知机(Perceptron)由两层神经元组成,是一种二分类的线性分类模型,也是最简单的单层前馈神经网络(Feedforward Neural Network)模型。感知机的提出受到生物神经元的启发,神经元在处理突触传递而来的电信号后,若产生的刺激大于一定的阈值,则神经元被激活,感知机也具有类似的结构。假设输入空间是χR^n,输出空间是y={+1,-1},x和y分别属于两个空间,则由感知机表示的由输入空间到输出空间的函数 为:f(x)=sign(wx+b)
其中w和b是感知机模型的参数,w∈R^n称为权重(Weight),b∈R^n称为偏置(Bias),wx表示两个向量间的内积。
Minsky和Papert已证明若决策区域类型是线性可分的,则感知机一定会学习到收敛的参数权重w和偏置b,否则感知机会发生震荡[3](fluctuation)。因此,感知机在线性可分数据中表现良好,如果设定足够的迭代次数,能很好的处理近似线性可分的数据。但如果对非线性可分的数据,如异或问题,单层感知机不能有效的解决。由于不能用一条直线划分样本空间,有学者想到用多条直线来划分样本,多层感知机就是这样一个模型。多层感知机结构如图1所示,相比较于单层感知机,多层感知机增加了隐藏层的层数。
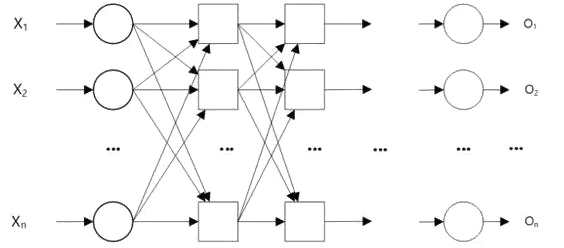
随着隐藏层数的增加,感知机的分类能力如表1所示。
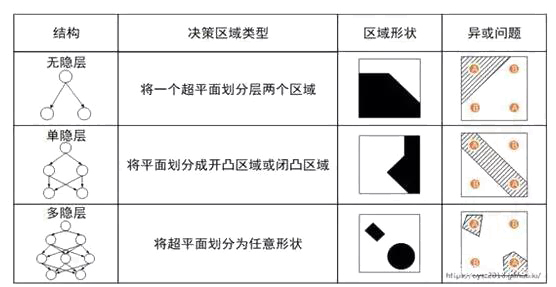
由表可知,在异或问题中,无隐层的感知机不能解决异或问题,引入了隐层后,异或问题得到解决,而随着层数越多,对于异或问题的拟合会越来越好。这说明,在感知机中随着隐藏层层数的增多,决策区域可以拟合任意的区域,因此理论上多层感知机可以解决任何线性或非线性的分类问题。但是,Minsky和Papert提出隐藏层的权重和偏置参数无法训练,这是由于隐藏层不存在期望的输出,无法通过单层感知机的训练方式训练多层感知机[4]。
反向传播算法
如何训练多层感知机的难点在很长一段时间没有得到解决,要训练多层网络,需要更有效的学习算法。反向传播(BackPropagation,BP)算法[1]是训练多层网络的常用方法,该方法用链式法则对网络中所有权重和偏置计算损失函数的梯度,将梯度反馈给随机梯度下降或其它最优化算法,用来更新权值以最小化损失函数。在网络中,正向传播和反向传播的过程如图2所示。在这个例子中输入图片经过网络正向传播后得到的分类是狗,与实际类别的人脸不符,此时会将误差逐层反向传播,修正各个层的权重和偏置参数后,再进行正向传播,反复迭代,直至网络的参数能正确的分类输入的图片。

反向传播算法的主要步骤如下:
(1) 随机初始化多层网络的权重和偏置参数,将训练数据送入多层网络的输入层,经过隐藏层和输出层,得到输出结果。完成网络的前向传播过程;
(2) 计算输出层实际值和输出值间的偏差,根据反向传播算法中的链式法则,得到每个隐藏层的误差,根据每层的误差调整各层的参数。完成网络的反向传播过程;
(3) 不断迭代前两步中的正向传播和反向传播过程,直至网络收敛。
由于还不熟悉markdown的公式编辑,这里省去反向传播的推导过程,感兴趣的朋友可以阅读周志华教授的《机器学习》第五章神经网络里面有详尽的推导过程。
卷积神经网络的基本思想
在BP神经网络中,每一层都是全连接的,参数数量随着网络宽度和深度增加会指数级增长。多层网络结合BP算法对输入数据虽然有强大的表示能力,但巨大的参数一方面限制了每层能够容纳的最大神经元数量,另一方面也限制了神经网络的深度。受到动物视觉皮层中感受野的启发,效仿这种结构的卷积神经网络具有局部连接和权值共享的特点,可以有效的减少网络的相关参数数量,优化网络的训练速度。
局部连接
Hubel和Wiesel在二十世纪五十年代和六十年代的研究表明,猫和猴子的视觉皮层中的神经元只响应特定的某些区域的刺激。将这种视觉刺激影响单个神经元反应的区域称为感受野(receptive field),相邻神经元细胞具有相同或相似的感受野[5]。正是由于发现了感受野等功能在猫的视觉神经中枢中的作用,催生了日本学者福岛邦彦提出带卷积和下采样层的多层卷积神经网络[6-8]。
当我们在处理一副图像时,其输入往往是高维的。传统的神经网络将下一层神经元连接到上一层所有神经元。这种方式随着网络层数的增加,参数数量会爆炸式增加,在实际运用中,会无法训练网络。卷积神经网络中采取的做法是将每个神经元连接到上一层的部分神经元。这种连接的空间范围是一个超参数,称为神经元的感受野,感受野实际上是神经元映射到输入图像矩阵空间的大小。
局部连接的实现方式是引入卷积层,通过卷积层对应局部的图像,每一层的神经元组合在一起对应图像的全局信息。如图3所示,在网络的第m层,每个神经元感受野大小为3,能连接到上一层的3个神经元。m+1层与m层类似。随着层数增加,神经元相对于输入层的感受野会越来越大。每个神经元不会响应感受野以外神经元的变化。受启发于动物的视觉神经元只响应局部信息,这样的结构确保了卷积神经网络只响应上一层局部神经元的变化,起到过滤作用的同时,减少了网络参数。而且随着层数的增加,这种过滤作用会越来越全局。
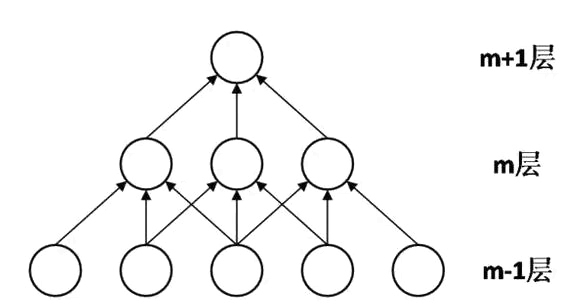
权值共享
卷积的优点除了局部连接外还有权值共享。如图所示,假设第m-1层有5个神经元,m层有3个神经元,对第m-1层的特征进行卷积,得到第m层共有3个单元的输出特征图。虽然第m层每个神经元都与第m-1层中的3个神经元连接,但同一组卷积操作的权重参数相同。在这个例子中,通过权值共享,将9个参数较少到了3个。
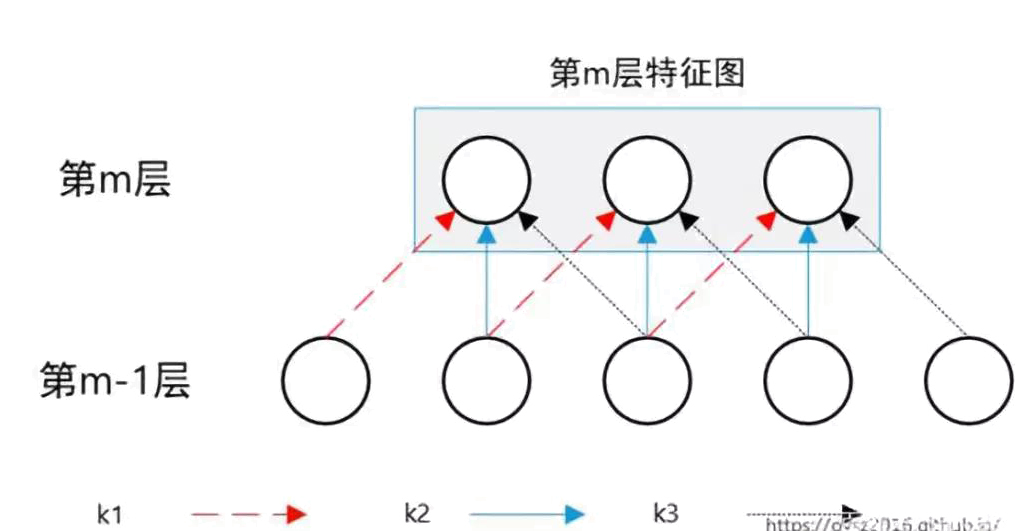
卷积神经网络中权值共享的实现方式是让同一个卷积核去卷积整张图像,生成一整张特征图[9]。在卷积操作中,同一个卷积核内,所有神经元共享相同权值,权值共享的策略可以很大程度上降低网络需要计算的参数数量。通过权值共享,不仅大大增加了参数的训练效率,而且提取的特征在一定程度上具有位置不变性,加强了特征对输入图像的表达能力。
卷积神经网络结构
卷积神经网络是一种层次模型(Hierarchical Model),其输入是RGB图像,视频,音频等数据。卷积神经网络通过一系列卷积(Convolution)操作,非线性激活函数(Non-linear Activation Function),池化(Pooling)操作层层堆叠,逐层从原始数据获取高层语义信息[10]。 如图5所示,在结构上,卷积神经网络分类器有四种类型的网络层:卷积层、池化层、全连接层和分类器。各层次之间的有如下约束:
(1)多个卷积(C)和池化(S)层,将上一层的输出图像与本层权重W做卷积得到各个C层,然后经过下采样得到S层。
(2)全连接层:全连接层的输入是最后一个卷积池化层的输出,其输出是一个N维的列向量,维度对应类别的个数。
(3)分类器:p_1,p_2,p_n的具体数值代表输入图像属于各类别的概率,分类器根据提取到的特征向量将检测目标划分到合适的类中。

卷积
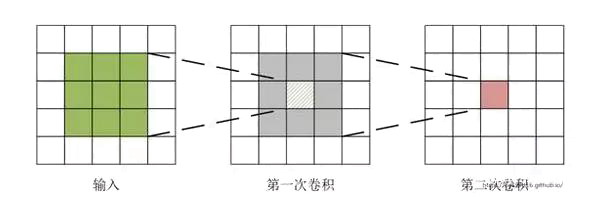
图片有着固有的特性,这意味着,图像的一部分特征与其他部分相似,对一张图片学习到的一部分特征可以用于其他部分。卷积操作受启发于这种特性,具体操作如图6所示,输入图片大小为5×5,经过卷积核大小为3×3的卷积后,原来的输入空间映射到3×3的区域。再经过一次相同大小的卷积核后,图片大小变为了1×1。可见,卷积层逐层提取特征的方式,能从庞大的像素矩阵中,提取到对图像更有代表性的特征。卷积层最重要的是卷积核的设计,卷积核有几个参数:大小、步长、数目、边界填充。这些参数会对卷积的效果带来很大的影响。若卷积核设计的较大,如AlexNet[11]中使用的11×11和5×5的卷积核,其感受野很大,能覆盖图像更大的区域,对图像的“抽象”能力会较好,但较大的卷积核也会带来参数过多的负面影响。卷积核的步长指卷积每次滑动的距离,在一定程度上影响了特征提取的好坏。每一层网络的多个卷积核保证了提取到的特征是图像的多个方面,但卷积核的数量也不是越多越好,过多的卷积核会增加参数数量,计算复杂的同时容易过拟合。边界填充可用于卷积核与图像尺寸不匹配时,填充图像缺失区域。
池化
卷积后的特征依然十分巨大,不仅带来计算性能的下降,也会产生过拟合。于是产生了对一块区域特征进行聚合统计的想法.例如,可以计算图像在某一块区域内的最大值或平均值代替这一块区域的特征,在降低特征维度的同时能使提取到的特征更具有代表性,还会使得处理过后的特征图谱拥有更大的感受野,这种用部分特征代替整体特征的操作称为池化[10](Pooling)。常用的池化方法如下:最大值池化(Max Pooling);均值池化(Mean Pooling);随机池化(Random Pooling)。池化操作具有以下优良特性:
(1)平移不变性(Translation Invariant)。无论是哪种池化方式,提取的都是局部特征。池化操作会模糊特征的具体位置,图像发生了平移后,依然能产生相同的特征。
(2)特征降维(Feature Dimension Reduction),池化操作将一个局部区域的特征进一步抽象,池化中的一个元素对应输入数据中的一个区域,可以减少参数数量,降低维度。
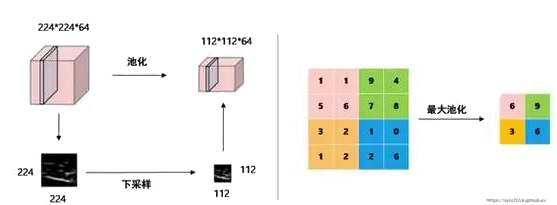
池化操作的功能是减小特征空间的大小,以减小网络中的参数和计算量,从而避免过度拟合。如图7所示,224×224×64经过大小为2×2,步长为2的池化核,变成了112×112×64,使得特征图谱减少为原来的1/2。图7中池化方式是最大池化,即将一个区域内的最大值表示为这个区域的池化结果。
全连接层
前面讨论的卷积层,池化层等操作是将原始数据映射到特征空间,使得到的特征矩阵越来越抽象并对特征有良好的表达能力。Softmax分类器要求输入是列向量,需要全连接层将卷积和池化的输出映射到线性可分空间。 全连接层可以聚合卷积和池化操作得到的高阶特征,并且可以简化参数模型,一定程度的减少神经元数量和训练参数。为了能用反向传播算法训练网络,全连接层要求图片有固定的输入尺寸。因此早期网络中,需要对不同尺寸的图片进行裁剪或拉伸,这种操作会带来图片信息的失真和损失。在第三章讨论的感兴趣(Region of Interest)池化方法,可以很好的解决这一问题。
卷积层是由全连接层发展而来,全连接层可以用特殊的卷积层表示,对于前一层全连接的全连接层可以用卷积核大小为1×1的卷积层替代,而对于前一层是卷积的全连接层可以用对上一层所有输入全局卷积的卷积层替代。在全连接层中可以认为每个神经元的感受野是整个图像。全连接层隐藏层节点数越多,模型拟合能力越强,但参数冗余会带来过拟合的风险而且会降低效率。对于这个问题,一般的做法是采用正则化(Regularization)技术,如L1、L2范式。还有通过Dropout随机舍弃一些神经元,来减少权重连接,然后增强网络模型在缺失个体连接信息情况下的鲁棒性[10]。
分类器
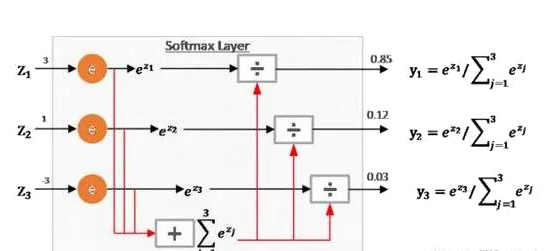
经过全连接层将特征映射到线性空间后,最后还需要将实例数据划分到合适的分类中。分类器有多种,常用的有支持向量机和Softmax回归,此处以Softmax为例子。Softmax函数用于将多个神经元的输出映射到(0,1)之间,转化为概率问题,从而处理多分类问题。如图8所示,Softmax层的输入分别是3、1和-3,在经过Softmax层后分别映射为0.85、0.12和0.03,三个值的累加和为1,其数值可以理解为概率,则属于y_1类的概率最大为0.85。这幅图是Softmax的通俗理解,具体推导过程可以参考这篇文章。
参考文献
[1] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors [J]. Nature, 1986, 323(6088): 533-536.
[2] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets [J]. Neural Computation, 2006, 18(7): 1527-1554.
[3] Minsky M, Papert S. Perceptrons: An introduction to computational geometry [J]. 1969, 75(3): 3356-3362.
[4] Minsky M L, Papert S A. Perceptrons (expanded edition) mit press [J]. 1988.
[5] 刘建立, 沈菁, 王蕾, 等. 织物纹理的简单视神经细胞感受野的选择特性 [J]. 计算机工程与应用, 2014, 50(1): 185-190.
[6] Fukushima K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position [J]. Biological Cybernetics, 1980, 36(4): 193-202.
[7] Fukushima K. Neocognitron: A hierarchical neural network capable of visual pattern recognition [J]. Neural Networks, 1988, 1(2): 119-130.
[8] Fukushima K, Miyake S. Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position [J]. Pattern Recognition, 1982, 15(6): 455-469.
[9] 曹婷. 一种基于改进卷积神经网络的目标识别方法研究 [D]. 湖南大学, 2016.
[10] LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition [J]. Neural computation, 1989, 1(4): 541-551.
[11] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks [C]. Proceedings of 26th Annual Conference on Neural Information Processing Systems, Nevada:NIPS, 2012: 1097-1105.
作者:冲弱
原始链接:https://oysz2016.github.io/post/4ec18e58.html
转载此文目的在于传递更多信息,版权归原作者所有,转载请保留原文链接及作者。





