作者:Carlos E. Perez
由于研究随机梯度下降(SGD)行为的多个研究小组进行了大量实验性工作,我们正在集中获得关于训练融合附近会发生什么的更清晰的了解。
本文源于2017年ICLR最佳论文奖获得者,“ 反思泛化 ”。这篇论文几个月前在一篇博客文章“ 重新思考深度学习中的泛化 ”中首次讨论。该论文中有一个有趣的观察是SGD的作用。结论非常激进,作者写道:
事实上,在神经网络中,我们几乎总是选择我们的模型作为运行随机梯度下降的输出。对线性模型来说,我们分析SGD如何作为一个隐式调节器。对于线性模型,SGD总是收敛到一个小规范的解决方案。因此,算法本身隐含地规范了解决方案。
这是一个非常奇怪的观点,即SGD被标记为“隐式正规化”。巧合的是,另一篇论文:Daniel Jiwoong Im,Michael Tao,Kristin Branson 的《对深度网络损失表面的实证分析》讨论了不同SGD算法的损失表面结构,并发现它们都不相同:

这些实验测量似乎支持类似于正则化的说法,您选择的SGD算法将影响网络收敛的位置。总之,您可以通过不同的SGD算法达到不同的休息位置。这与我们常规考虑SGD的方式不同。也就是说,由于不同的策略,不同的SGDs会给您带来不同的收敛速度,但我们确实期望它们都以相同的结果结束!我们认为,不论方法如何,SGD都会达到同样的最佳状态(顺便说一句,我提到的这篇精彩的论文在2017年ICLR会议上被拒绝,在深度学习空间中撰写学术论文是不合理的。
Leslie Smith和Nicholay Topin最近向ICLR 2017研讨会提交了一个研讨会论文:“ 探索具有循环学习率的损失函数拓扑 ”,他们发现了一些奇特的收敛行为:
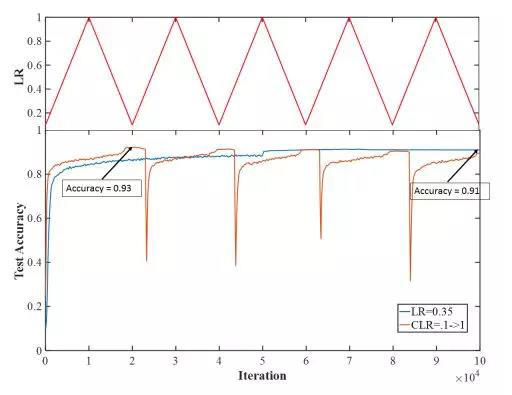
在这里,当你单调地增加和减少学习速率时,在收敛状态附近会出现一个转变,即一个足够大的学习速率扰动系统,马上就会流入一个更高损失的空间。然后,SGD再次迅速收敛(注意到收敛速度更快)。到底发生了什么?
最近Ravid Shwartz-Ziv和Naftali Tishby撰写的在Arxiv上的关于“通过信息打开深度神经网络黑匣子”的论文对SGD的情况进行了精辟的解释。他们将SGD描述为具有两个不同的阶段,即漂移阶段和扩散阶段。SGD在第一阶段,基本上探索解决方案的多维空间。当它开始收敛时,它到达扩散阶段,在这个阶段它非常混乱并且收敛速度变慢。对这一阶段发生的事情的直觉是网络正在学习压缩。该图最好地说明了这种行为:
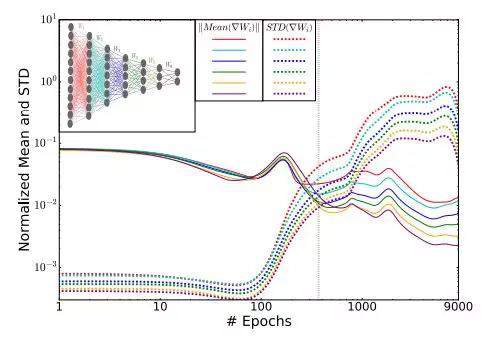
也就是说,这种行为产生一种从低均方差的高均值到低均值的高均方差的相变过渡。这为Smith等人的观察结果提供了进一步的解释。在接近收敛的地区,它非常混乱。这当然不能完全解释为什么高学习率会使系统陷入高损失的地方。
Tomaso Poggio和Qianli Liao有他们自己的实验,并且有一个理论:“ 理论II:深度学习中经验风险的景观 ”。他们详细描述了那个混乱地区的行为
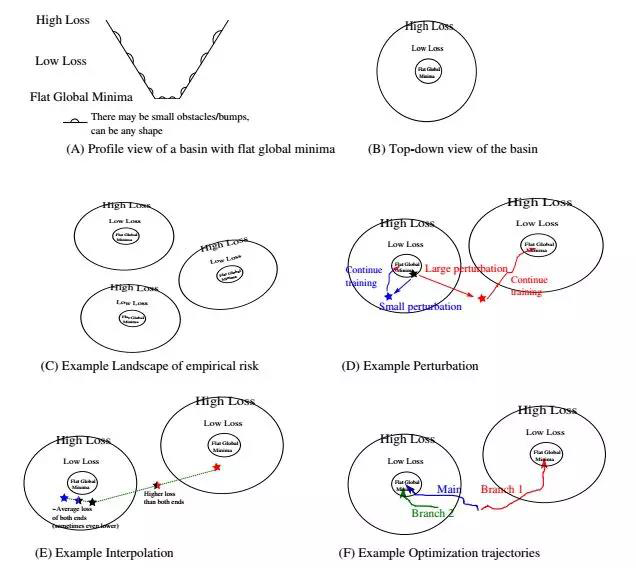
全球最低点的盆地是平坦的,但非常坎坷。不仅如此,还有很多这样的盆地。他们引用一些深奥的数学定理并得出这个结论:
我们可以调用Bezout定理得出结论:有很多零误差最小值,零误差最小值是高度退化的,而局部非零最小值,如果存在的话,可能不会退化。在分类的情况下,零误差意味着边缘的存在,即围绕零误差的所有维度中的平坦区域。
绝对引人入胜的论文,值得一读。然而,从这篇论文中可以看出一个实用的方法:“ 在一个盆地内平均两个模型往往会给出一个误差,即两个模型的平均值(或更少)。在不同盆地间的平均两个模型往往会给出比两个模型任意一个都高的误差“。
关于如何利用这些新知识还存在很多问题。我们如何利用这一点来实现转移学习,领域适应和避免遗忘等关键功能?这些阶段的关系是什么,特别是关于泛化的压缩阶段?这里肯定有很多有趣的路径!
总之,有很多研究小组试图更好地理解深度学习系统的行为。正是通过这项基础研究工作,我们才能集中获得改善自己工作的更好方法。不幸的是,会议倾向于通过良好的实验数据评估新型架构(越疯狂越好)。不幸的是,这有利于炼金术的实践,而不是追求化学科学。
原文链接:https://medium.com/intuitionmachine/the-peculiar-behavior-of-deep-learni...
本文转自:微信号 - fastai中文社区,作者:Carlos E. Perez,转载此文目的在于传递更多信息,版权归原作者所有。





