作者:Chris von Csefalvay
编译: ronghuaiyang - AI公园(AI_Paradise)
迁移学习的好处不用多说,那么,什么时候用,什么时候不该用,为什么有用?看看就知道。
如果你最近工作在深度学习领域,特别是图像识别,你可能看到过大量的博客,承诺教会你如何建立一个世界级的图像分类器,只需在一个GPU上用十几行或更少的代码跑上几分钟。令人震惊的不是这个承诺,而是在这些教程中,大多数最终都实现了。这怎么可能呢?对于那些接受过“传统”机器学习技术培训的人来说,为一个数据集开发的模型可以简单地应用于另一个数据集的想法听起来很荒谬。
答案当然是“迁移学习”,这是深度神经网络最吸引人的特性之一。在这篇文章中,我们将首先看看什么是迁移学习,什么时候可行,什么时候不可行,为什么在某些情况下行不通,最后总结一些关于迁移学习的最佳实践的建议。
迁移学习是什么?

Pan and Yang(2010)对迁移学习给出了一个优雅的数学定义(见第2.2小节)。然而,对于我们的目的,一个简单得多的定义就足够了:迁移学习使用针对特定任务(有时称为源任务)的所学知识来解决另一个任务(目标任务)。当然,假设源任务和目标任务非常相似。这种假设是转移学习的核心。因此,我们必须首先理解为什么转移学习是有效的。
你可能还记得,典型的当代神经网络—例如,多层卷积深度神经网络(cDNN)—由多层神经元组成,每层神经元根据训练结果计算出的网络权重和偏差将结果前馈。这一结构是根据人类大脑中与之相当相似的特定过程—Ventral Visual Stream——而设计的。
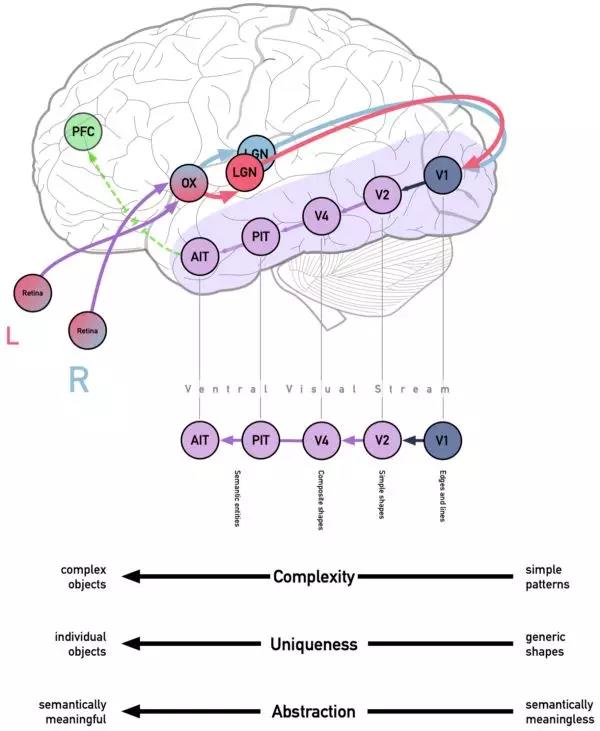
ventral stream开始于初级视觉皮质或V1,枕叶的一部分。V1从外侧膝状体核接收视觉信息,丘脑的一部分将光信息发送到枕叶而细分成两种类型的信息——这样的输入对于决定你看的是什么更有用而且对于你确定东西在哪里也更有用。它们都位于初级视觉皮层,但ventral visual stream由LGN的单细胞层的“是什么”信息提供:有关物体的缓慢但持续的详细信息,来自视网膜神经节细胞P细胞。
然后,P细胞的输出(有时称为投影)经过ventral visual stream(从V1到V2, V4,最终到颞下叶)时被处理。通过激发实验发现,V1中的细胞对相当简单的图案(主要是边缘、它们的方向、颜色和空间频率)有反应,而V2对更复杂的概念有反应,包括某些格式塔现象,如“主观轮廓”。最终,逐渐进入下颞叶,神经元对越来越复杂的模式做出反应。

我们看到这在深层神经网络中的重复。Zeiler-Fergus反卷积网络允许我们看到对于特定的层会对哪些模式有反应。也就是说,这些结构会引起这些特定的神经元的兴奋。随着层数的增加,形状的复杂性也随之增加。当我们在第一层看到简单的边缘甚至是颜色块时,后面的层会显示更复杂的图案,最后一层的激活通常可以被识别为目标类。它们也变得越来越语义化——线条的组合被加权在一起,就像一个能识别三角形的过滤器,三角形过滤器的组合能识别两只耳朵,再加上其它过滤器,它开始识别狗的脸与猫的脸是不同的。
迁移学习的概念是与生俱来的,因为神经网络是分层自包含的——也就是说,你可以在一个特定的层之后移除所有的层,将一个全连接的层与不同数量的神经元和随机权重连接起来,得到一个可以工作神经网络。这是迁移学习的基础。在转移学习中,我们使用训练有素、构造良好的网络在大集合上所学到的知识,并将它们应用于在较小的(通常是几个数量级!)数据集上提高检测器的性能。
迁移或者不迁移
从上面看来,一些关于迁移学习的作用(和负作用)的事实浮出水面。迁移学习的最大好处体现在目标数据集相对较小的时候。在许多这样的情况下,模型可能容易过拟合,而数据增强可能并不总是能解决整个问题。因此,迁移学习最适用于源任务的模型在比目标任务获得的训练集大得多的训练集上训练的情况。这可能是因为对一个特定实例的事情很难遇得到,或者标注过的样本很难获得(例如在诊断放射学,对图片做标记往往很难,尤其是罕见的条件)。
如果存在过拟合的风险,那么每个任务的数据量大致相同的模型仍然可能受益于迁移学习,因为目标任务通常是高度领域特定的。事实上,在训练大型特定领域的dCNN时可能会适得其反,因为它可能会过度适合特定领域。因此,有时建议在源任务和目标任务的训练集大小相同的情况下使用迁移学习。
在实践中,在计算机视觉中,使用标准网络是非常普遍的,它训练了大量的图像数据集——比如ImageNet的超过1000个类别的120万幅图像——作为起点,甚至可以完成特定领域的任务,比如评估胸片。许多机器学习框架,特别是像Caffe、fastai和keras这样的高级软件包,都自带了model zoo,可以方便地访问预先训练好的dCNN。因此,只需要删除最顶层,添加一个或多个新层并对模型进行再训练(finetuen)。新模型将不用再为了构建像ResNet50,NASNet或Inceptionv3这样的模型而进行的数周艰苦训练了。总的来说,如果使用得当,迁移学习将给你带来三重好处:更高的起始精度、更快的收敛速度和更高的逼近精度(训练收敛的精度水平)。最近,一些很有前途的网站出现了,它们列出了各种各样的预培训模型——我最喜欢的是ModelDepot和ModelZoo,后者有一个庞大的数据库,可以通过框架和解决方案进行过滤,包括许多预先训练的GANs。
一些最佳的实践经验
大多数深度学习框架允许你“选择性地解冻”深度神经网络的最后n层,而将其余部分学习到的权重冻结。总的来说,这个特性并不像它最初听起来那么有用。经验表明,花时间进行彻底的模型内省,并试图确定在哪里切断解冻几乎是不值得的。一个例外是,如果你训练的是一个非常大的网络,它可能在你的GPU内存里放不下——在这种情况下,资源限制将决定你能解冻多少。
与其解冻特定的层,使用不同的学习率可能是更好的主意,其中学习率是根据每一层来确定的。底层的学习速度将非常低,因为这些泛化得非常好,主要对边缘、水滴和其他琐碎的几何图形作出响应,而对更复杂的特性作出响应的层将具有更大的学习速度。在过去,2:4:6规则(10-4)对我非常有用——对最下面的几层使用10-6的学习率,对其他传输层使用10-4的学习率,对我们添加的任何额外层使用10-2的学习率。我也听到其他人在不同的架构中使用2:3:4:5:6或2:3:4。对于ResNet及其衍生品,我总是觉得2:4:6比2:3:4更合适,但我绝对没有经验证据支持这一点。、
通过重新训练所有层来迁移学习并不总是一个好主意。如果目标任务是一个小数据集,而且非常类似(如识别一个新不包括在ImageNet的动物类别或车辆),把权重冻结,在顶端放一个线性分类器来输出概率可能是更有用的,能够得到类似的结果也不用担心过拟合。
当迁移到具有较大数据集的任务时,你可能希望从零开始训练网络(完全不需要迁移学习)。同时,考虑到这样一个网络将随机初始化,你使用预先训练的权重来初始化也没有什么损失!解除整个网络的冻结,删除输出层,并用一个匹配目标任务类数量的输出层替换它,并对整个网络进行finetune。
最后:知道你正在重用什么。这不仅是一个很好的练习,要知道你是从哪个网络转过来的——这是深入学习商业技巧的关键。虽然普遍信任的主要网络如ResNet一次又一次被证明是健壮,可靠的网络,选择适合你的任务一个网络和可能是最有效的几种替代网络,如果存在的话,正是给深度学习专业人士付这么多钱的价值所在。如果使用非标准网络——任何没有数百个经过同行评审的应用程序的网络都被认为是非标准的——请确保网络体系结构是健全的,并且确实是最佳选择。Tensorboard和Netscope等工具可以帮助你得到一个神经网络的很好的洞察,而且可以帮助你评估网络结构。当使用一个不熟悉的网络时,我发现内省,包括反卷积网络或其他逆向工程解决方案来查看层和神经元水平的激活最大值可以带来很大的好处。
英文原文:https://medium.com/starschema-blog/transfer-learning-the-dos-and-donts-1...
本文转自: AI公园(AI_Paradise),转载此文目的在于传递更多信息,版权归原作者所有。





