Deep Learning with Python 4.5节
1. 定义问题并装载数据集(Defining the problem and assembling a dataset)
首先,你必须定义你手头的问题:
- 输入数据是什么?你希望预测什么?只有在能够获得训练数据的情况下你才能进行预测:举个例子,如果你同时又电影的影评和对应的情感注释,你只能从中学习分类电影影评的情绪。因此,数据可用性是这个阶段的限制因素(除非你有办法雇人帮你收集数据)
- 你面临什么类型的问题?它是二元分类吗?还是多类分类?标量回归?向量回归?多类多标签分类?或者其他的类型,例如聚类,生成问题或者增强学习?识别问题的类型能够指导你选择模型的构架,损失函数等等
直到你知道你的输入和输出是什么,以及你将使用哪些数据,你才能进入下一个阶段。注意你在这个阶段所做的假设:
- 你假设你可以根据给定的输入预测输出
- 你假设你的可用数据有足够的信息用于学习输入与输出之间的关系
当然,这仅仅只是假设,直到你有一个确切的模型,这些假设才能被验证或者被否定。并非所有问题都能解决。只是因为你仅仅收集了一些输入X和目标Y,这并不意味着X包含足够的信息去预测Y。举个例子,如果你试图通过股票的历史价格去预测股票的价格,那么你不可能成果,因为股票的历史价格不包含太多的预测信息。
非平稳问题是一种不可解决的问题,你应该注意此类问题。假设你正在尝试建立一个衣服的推荐引擎,你在某一个月的数据上进行训练(比如说,8月),你希望能够在冬天的开始的时候推送你的推荐。这里有一个很大的问题:人们购买的衣服类型会根据季节的变化而变化。衣服的购买在几个月的时间跨度中是一种非平衡现象。在这种情况下,正确的做法是不断地对过去的数据训练新的模型,或者在问题处于静止的时间范围内收集数据。对于想购买衣服这样的周期性问题,几年内的数据足以捕捉到季节的变化,但是记住要让一年中的时间成为你模型的输入。
请记住,机器学习只能记住训练数据中存在的模式。你只能认识你已经看到过的东西。利用机器学习对过去的数据进行训练,用于预测未来,这样的做法假设未来的行为将于过去类似。但是,通常并非如此。
2. 选择成功的衡量指标(Choosing a measure of success)
要控制某些东西,你需要能够观察到它。为了取得成功,你必须定义成功是什么,是正确率?精度或者召回率?还是客户保留率?你的成功指标的定义将会指导你选择损失函数,损失函数就是你模型将要优化的内容。损失函数应该能够直接与你的目标保持一致,例如你业务的成功。
对于均衡分类问题,这类问题中每个类别都有相同的可能性,准确率和ROC AUC是常用的指标。对于类不平衡问题,你可以用精度和召回。对于排名问题或者多标签问题,你可以用平均精度。定义你自己的评价指标并不罕见。要了解机器学习成功指标的多样性以及它们是如何关系不同的问题域,有必要去了解Kaggle上的数据科学竞赛,这些竞赛展示了广泛的问题和评价指标。
3. 决定一个验证策略(Deciding on an evaluation protocol)
一旦你知道你的目标是什么,你必须确定你将如何衡量你当前的进度。
我们之前已经了解了三种常用的验证策略:
- 保留一个hold-out验证集,当你有足够多的数据时,用这种方法
- K-fold 交叉验证。数据太少,不足以使用第一种验证方法的使用,用这种方法。
- 迭代 K-fold 交叉验证。只有很少的数据可用时,用于执行高度准确的模型评估。
选择其中一个。在大多数情况下,第一种方法工作得很好。
4. 准备你的数据(Preparing your data)
一旦你知道你在训练什么,你正在优化什么,如何评估你的方法,你几乎已经准备好开始训练模型。但是首先,你应该将数据格式化为机器学习模型所能接受的形式。这里,我们假设这个模型是一个深度学习模型,那么:
- 正如前面提到的那样,你的数据应该格式化为张量
- 通常情况下,这些张量的值被缩小为较小的值,比如说缩放到[-1,1]或者[0,1]
- 如果不同的特征采取不同范围的值,那么数据应该做归一化处理
- 你可能想做一些特征工作,特别是对于数据集不大的问题
5. 开发一个比基线好的模型(Developing a model that does better than a baseline)
在这个阶段,你的目标是做到statistical power(不会翻译),也就是开发一个能够击败基线的模型。在MNIST数字分类示例中,任何达到大于0.1精度都可以说是具有statistical power; 在IMDB的例子中,大于0.5就可以了。
请注意,达到statistical power并不总是可能的。如果在尝试了多个合理的体系构架之后,仍然无法打败一个随机基线,那么可能是你要求的问题的答案无法从输入数据中获得。记住你提出的两个假设:
- 你假设你可以根据给定的输入预测输出
- 你假设你的可用数据有足够的信息用于学习输入与输出之间的关系
这些假设有可能是错误的,在这种情况下你必须重新开始。
假设目前为止一切都很顺利,你需要作出三个关键的选择来建立你的第一个工作模型:
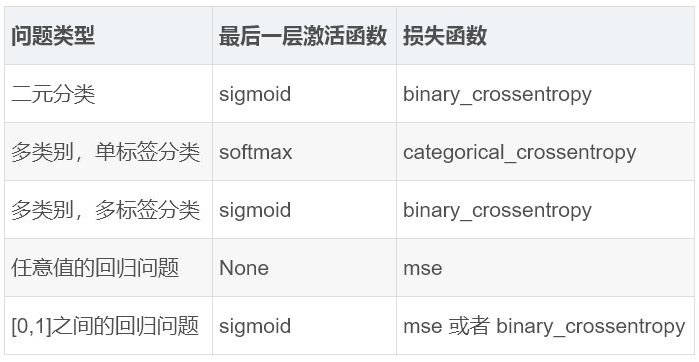
- 最后一层的激活函数,这为网络的输入设定了限制。例如,在IMDB分类问题中,最后一层使用了sigmoid; 在回归问题中,最后一层没有使用任何激活函数
- 损失函数,这应该与你正在尝试解决的问题的类型相匹配。例如在IMBD二元分类问题中,使用了binary_crossentropy,回归问题中使用了mse等等。
- 优化配置,你将使用什么优化器?学习率是多少?在大多数情况在,使用rmsprop和默认的学习率是安全的。
关于损失函数的选择,请注意,并不总是可以直接优化metric。有时候,没有简单的方法可以将metric转换为损失函数;损失函数毕竟只需要一个小批量的数据就能计算(理想情况下,损失函数只需要一个数据就能计算),并且损失函数必须是可微分的(否则,你不能使用反向传播来训练你的网络)。例如,广泛使用的分类度量ROC AUC就不能直接优化。因此,在分类问题中,通常针对ROC AUC的代理指标(例如,交叉熵)进行优化,一般来说,你希望如果越低的交叉熵,你就能获得更高的ROC AUC。
下面的表格可以帮助为几种常见的问题选择最后一层激活函数和损失函数
6. 全面升级:开发一个过拟合的模型
一旦你的模型达到了statistical power,那么问题就变成了:你的模型是否足够强大?你是否有足够多的网络层和参数来正确建模你的问题?例如,具有两个神经元的单层网络在MNIST具有statistical power,但是不能很好的解决MNIST分类问题。
请记住,机器学习中最困难的就是在优化和泛华之间取得平衡;理想的模型就是站在欠拟合与过拟合之间。要弄清楚这个边界在哪里,你必须先穿过它。
要弄清楚你需要多大的模型,你必须先开发一个过拟合的模型。这很容易:
- 1. 增加网络层
- 2. 让网络层变大
- 3. 训练更多次
始终监视着训练误差和验证误差,以及你所关心的metrics。当你看到模型在验证集上性能开始下降,就达到了过拟合。下个阶段是开始正则化和调整模型,尽可能的接近既不是欠拟合又不是过拟合的理想模型。
7. 正则化你的模型并调整你的超参数(Regularizing your model and tuning your hyperparameters)
这一步将花费大量时间,你将重复修改你的模型,并对其进行训练,在验证集上进行评估,再次修改,如此重复,知道模型达到所能达到的最佳效果。以下是你应该尝试做的一些事情:
- 添加Dropout
- 尝试不同的体系结构的网络:添加或者删除网络层
- 添加 L1/L2 正则化
- 尝试不同的超参数(例如每一层的神经元个数或者优化器学习率),以获得最佳的参数选择
- (可选)迭代特征工程:添加新特征,或者删除似乎没有提供信息的特征
请注意以下几点:每次使用验证集来调整模型参数时,都会将有关验证的信息泄露在模型中。重复几次是无害的;但是如果重复了很多很多次,那么最终会导致你的模型在验证集上过拟合(即使没有直接在验证集上进行训练),这使得验证过程不太可靠。
一旦你开发出令人满意的模型,你可以根据所有可用的数据(训练集和验证集)来训练你最终的模型。如果测试集的结果明显低于验证集上结果,那么可能意味着你的验证过程不太可靠,或者你的模型在验证集中已经过拟合了。在这种情况下,你可能需要更为靠谱的验证策略(例如迭代K-fold验证)
来源:CSDN - 小墨鱼.曾,转载此文目的在于传递更多信息,版权归原作者所有。





