1. 极大似然估计中取对数的原因:
取对数后,连乘可以转化为相加,方便求导;
对数函数ln为单调递增函数,不会改变似然函数极值点。
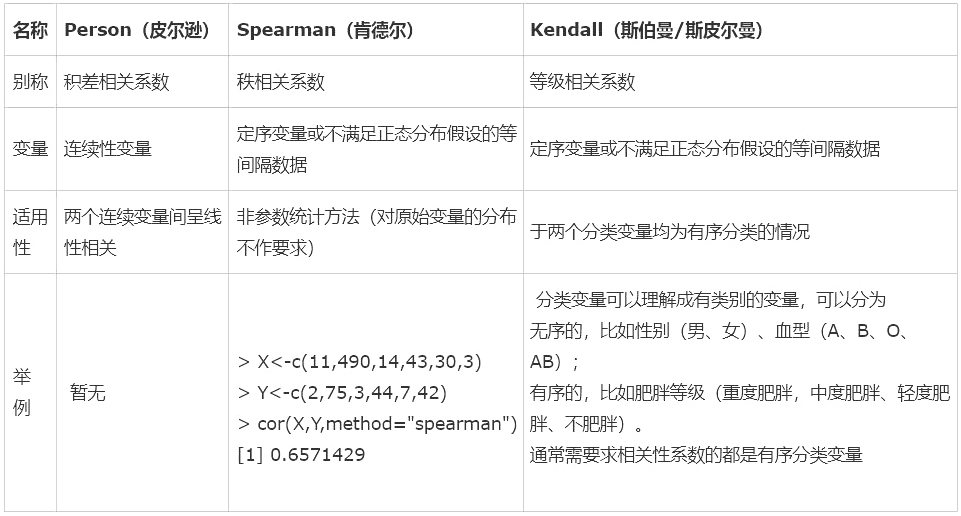
2. 统计学三大相关系数对比:
pearson积差相关系数,计算连续性变量才可采用;Spearman秩相关系数或Kendall等级相关系数,适合于定序变量或不满足正态分布假设的等间隔数据;
当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用spearman或kendall相关。
3. LR和SVM的联系与区别?
联系:
- LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
- 两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
- LR是参数模型,SVM是非参数模型。
- 从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
- 逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
- logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
4. 决策树、Random Forest、Booting、Adaboot、GBDT和XGBoost的区别和联系是什么?
集成学习的集成对象是学习器, Bagging和Boosting属于集成学习的两类方法。
- Bagging方法有放回地采样同数量样本训练每个学习器,然后再一起集成(简单投票);
- Boosting方法使用全部样本(可调权重)依次训练每个学习器,迭代集成(平滑加权)。
决策树属于最常用的学习器,其学习过程是从根建立树,也就是如何决策叶子节点分裂,ID3/C4.5决策树用信息熵计算最优分裂,CART决策树用基尼指数计算最优分裂,xgboost决策树使用二阶泰勒展开系数计算最优分裂。
Bagging方法:
- 学习器间不存在强依赖关系, 学习器可并行训练生成, 集成方式一般为投票;
- Random Forest属于Bagging的代表, 放回抽样, 每个学习器随机选择部分特征去优化;
Boosting方法:
- 学习器之间存在强依赖关系、必须串行生成,集成方式为加权和;
- Adaboost属于Boosting, 采用指数损失函数替代原本分类任务的0/1损失函数;
- GBDT属于Boosting的优秀代表,对函数残差近似值进行梯度下降,用CART回归树做学习器, 集成为回归模型;
xgboost属于Boosting的集大成者,对函数残差近似值进行梯度下降,迭代时利用了二阶梯度信息,集成模型可分类也可回归。由于它可在特征粒度上并行计算,结构风险和工程实现都做了很多优化,泛化,性能和扩展性都比GBDT要好;
随机森林Random Forest是一个包含多个决策树的分类器;
至于AdaBoost,则是英文"Adaptive Boosting"(自适应增强)的缩写;
GBDT(Gradient Boosting Decision Tree),即梯度上升决策树算法,相当于融合决策树和梯度上升boosting算法。
xgboost类似于gbdt的优化版,不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:
- 损失函数是用泰勒展式二项逼近,而不是像gbdt里的就是一阶导数
- 对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性
- 节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
5. 朴素贝叶斯“朴素”的含义?
“朴素”的含义:假定所有的特征在数据集中的作用是同样重要、彼此独立的。这个假设现实中基本上不存在,但特征相关性很小的实际情况还是很多的, 所以这个模型仍然能够工作得很好。
6. KNN中的K值选取的影响
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,学习的近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是学习的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
7. 马氏距离较欧式距离的优点?
- 尺度不变性
- 考虑了模式的分布
8. 随机森林如何评估特征重要性?
- Decrease GINI: 对于回归问题,直接使用argmax(VarVarLeftVarRight)作为评判标准,即当前节点训练集的方差Var减去左节点的方差VarLeft和右节点的方差VarRight。
- Decrease Accuracy:对于一棵树Tb(x),我们用OOB样本可以得到测试误差1;然后随机改变OOB样本的第j列:保持其他列不变,对第j列进行随机的上下置换,得到误差2。至此,我们可以用误差1-误差2来刻画变量j的重要性。基本思想就是,如果一个变量j足够重要,那么改变它会极大的增加测试误差;反之,如果改变它测试误差没有增大,则说明该变量不是那么的重要。
9. 什么是共线性, 跟过拟合有什么关联?
共线性:多元线性回归中,变量之间高度相关,而使回归估计不准确;
共线性会导致冗余,造成过拟合;
解决办法:排除高度相关变量 / 加入权重正则
10. 模型的高bias是什么意思, 我们如何降低它?
bias(偏差)太高说明模型太简单了,数据维数不够,或训练样本较少, 无法准确预测数据, 所以,增加训练样本,添加特征。
11. SVM、LR、决策树的对比
- 模型复杂度:SVM支持核函数,可处理线性非线性问题;LR模型简单,训练速度快,适合处理线性问题;决策树容易过拟合,需要进行剪枝;
- 损失函数:SVM hinge loss; LR L2正则化;;adaboost 指数损失;
- 数据敏感度:SVM添加容忍度对outlier不敏感,只关心支持向量,且需要先做归一化;LR对远点敏感;
- 数据量:数据量大就用LR,数据量小且特征少就用SVM非线性核。
12. 什么是ill-condition病态问题?
训练完的模型,测试样本稍作修改就会得到差别很大的结果,就是病态问题,模型对未知数据的预测能力很差,即泛化误差大。
13. RF与GBDT之间的区别与联系?
相同点:都是由多棵树组成,最终的结果都是由多棵树一起决定;
不同点:
- 组成RF的树可以分类树也可以是回归树,而GBDT只由回归树组成 ?????????
- 组成RF的树可以并行生成,而GBDT是串行生成
- RF的结果是多数表决表决的,而GBDT则是多棵树累加之和
- RF对异常值不敏感,而GBDT对异常值比较敏感
- RF是减少模型的方差,而GBDT是减少模型的偏差
- RF不需要进行特征归一化。而GBDT则需要进行特征归一化
14. 什么是OOB?
- p = 1 - (1 - 1/N)^N,其意义是:一个样本在一次决策树生成过程中,被选中作为训练样本的概率,当N足够大时,当N足够大时,p = 1- 1/e 这个值,约等于63.2%。简言之,即一个样本被选中的概率是63.2%,根据二项分布的期望,大约有63.2%的样本被选中,即有63.2%的样本是不重复的,有36.8%的样本可能没有在本次训练样本集中。
- RF中,把这63.2%的数据称为袋外数据oob(out of bag),它可以用于取代测试集误差估计方法。
15. L0、L1、L2对比
L0范数是指向量中非0的元素的个数,如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀疏的;
L0和L1范数都可以实现特征系数,为什么不用L0而用L1呢?因为L0范数很难优化求解(NP难问题),L1作为L0范数的最优凸近似,更容易优化求解;
L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,并且特征趋于平滑。
参数稀疏的优点:
- 通过稀疏规则化算子,实现特征自动选择
- 模型更容易解释
16. 最大似然估计和最大后验概率的区别
- 通俗来讲,最大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。重要的假设是所有采样满足独立同分布。
- 最大后验概率与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
17. 主成分分析(PCA)过程
第一步,对每个维度进行标准化处理(z-score);
第二步,求出特征协方差矩阵;
第三步,求出协方差矩阵的特征值和特征向量;
第四步,选择其中最大的k个特征值,并将其对应的特征向量作为列向量,组成特征向量矩阵;
第五步,将样本点投影到选取的特征向量上,即用样本标准化后的特征矩阵点乘特征向量矩阵,两个矩阵的内积即为投影后的数据,即降维后的结果。
PCA的解释理论基础有:最大方差理论和最小平方理论
18. Jensen (詹森)不等式
如果f是凸函数,X是随机变量,那么 :
特别地,如果f是严格凸函数,那么 且仅当 ,也就是说X是常量;
Jensen不等式应用于凹函数时,不等号方向反向,也就是 。
19. 逻辑回归的损失函数为什么要使用极大似然函数作为损失函数?
- 将极大似然函数取对数以后等同于对数损失函数,在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的。
- 如果你使用平方损失函数,你会发现梯度更新的速度和sigmod函数本身的梯度是很相关的。sigmod函数在它在定义域内的梯度都不大于0.25。这样训练会非常的慢。
20. 特征选择和降维的区别
降维本质上是从一个维度空间映射到另一个维度空间,所有的特征都参与映射,构造出新的特征;
特征选择是选取其中一部分特征,特征的值保持不变,只不过特征维数变少;
两者都是可以防止过拟合的有效手段。
21. 熵的连锁规则与互信息
H(X,Y) = H(X)+ H(Y | X) = H(Y)+H(X | Y)
互信息 I(X ; Y)= H(X)- H(X | Y)= H(Y)- H(Y | X)
互信息表示已知Y以后,X的不确定性减少量,即随机变量Y揭示了多少关于X的信息。
互信息是一种计算两个随机变量之间共有信息的度量,满足非负性和对称性;
互信息是验证变量是否互不相关的手段,当两个随机变量无关时,互信息为零;当变量间存在依赖关系时,它们的互信息不仅和依赖程度有关还有变量的熵相关。
22. 基尼系数与熵
信息增益 = 熵 - 条件熵(偏向选择特征值比较多的属性),信息增益越大,特征越好;
信息增益比 = 信息增益/所选特征的熵 ,信息增益比越大,特征越好;
基尼系数 = 1 - 全体数据集中每种类别概率的平方之和;
基尼系数可以用来评测分类器的分类效果,它代表了模型的不纯度,基尼系数越小,基尼不纯度越低,特征越好;
熵模型涉及大量的对数运算,计算更加复杂。
ps:熵是描述系统混乱的量,熵越大说明系统越混乱,携带的信息就越少,熵越小说明系统越有序,携带的信息越多。在决策树模型中,父节点的熵大于子节点的熵。
23.sklearn中的决策树、随机森林
sklearn.tree.DecisionTreeClassifier 使用的是CART树,稍稍有区别的是它对CART的计算性能进行了优化。我们不可以指定它使用其他算法,但是可以设置criterion参数为"entropy",也就是信息增益,这样就几乎是ID3了。不过C4.5是基于信息增益率的,所以sklearn.tree.DecisionTreeClassifier做不到C4.5算法。
CART树为二叉树,但是sklearn中的决策树依然可以处理多分类问题。
sklearn中的随机森林实现是取每个分类器预测概率的平均,而不是让每个分类器对类别进行投票。
24. sklearn交叉验证模型评估中的 scoring 参数,对回归模型评估采用的“误差指标的否定值”
对回归模型进行评估,scoring 可选择参数有‘neg_mean_absolute_error’、‘neg_mean_squared_error’等,所得的结果均为负值,因为取了’neg‘。为什么不直接用’mean_absolute_error‘,而要取负呢?因为mean_squared_error是一种损失函数,优化的目标的使其最小化,而分类准确率是一种奖励函数,优化的目标是使其最大化(scoring是奖励函数)。scoring的结果越大,意味着误差越小。
本文转自:博客园 - Solong1989,转载此文目的在于传递更多信息,版权归原作者所有。





