在走进深度学习的过程中,最吸引作者的是一些用于给对象分类的模型。最新的科研结果表示,这类模型已经可以在实时视频中对多个对象进行检测。而这就要归功于计算机视觉领域最新的技术革新。
众所周知,在过去的几年里,卷积神经网络(CNN或ConvNet)在深度学习领域取得了许多重大突破,但对于大多数人而言,这个描述是相当不直观的。因此,要了解模型取得了怎样大的突破,我们应该先了解卷积神经网络是怎样工作的。
卷积神经网络可以做些什么?
卷积神经网络用于在图像中寻找特征。在CNN的前几层中,神经网络可以进行简单的"线条"和"角"的识别。我们也可以通过神经网络向下传递进而识别更复杂的特征。这个属性使得CNN能够很好地识别图像中的对象。
卷积神经网络
CNN是一个包含各种层的神经网络,其中一些层是卷积层、池化层、激活函数。
卷积层是如何工作的?
要了解CNN如何工作,你需要了解卷积。卷积涉及浏览图像和应用滤波器等具体内容。
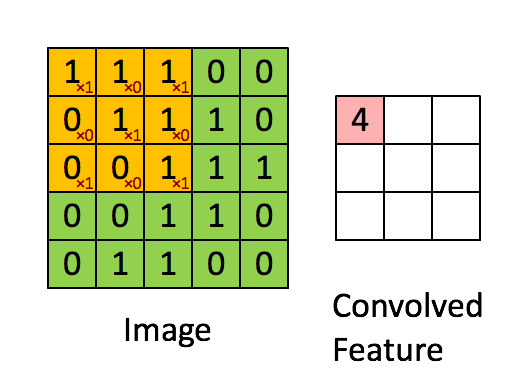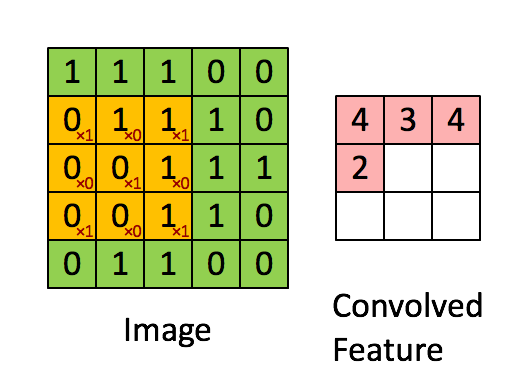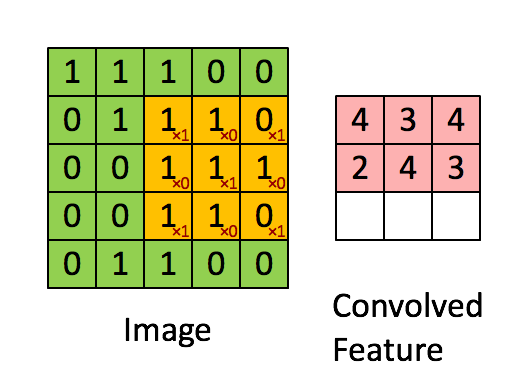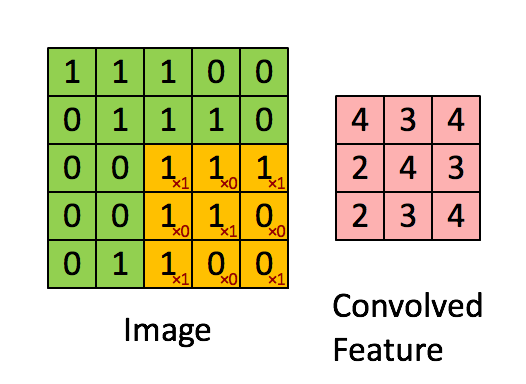
上图是一个5x5的矩阵。现在,你另外选取一个3x3矩阵,然后移动到图像上,将3x3矩阵与被覆盖的图像部分相乘以生成单个值。紧接着,3x3矩阵向右和向下移动以"覆盖"整个图像。最后,我们将获得如上所示的内容。
卷积层的目标是过滤。滤波器是由矢量的权重堆叠乘以卷积输出的值来表示的。当训练图像时,这些权重会发生变化,也就是说当进行图像评估时,它会通过它捕捉到的一些特征来预测出图像的内容。
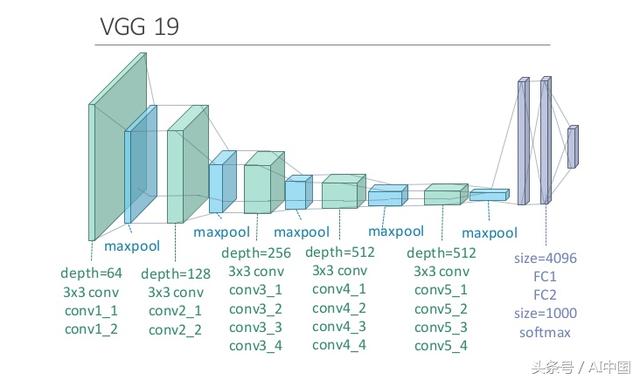
池化层
卷积层之后的层主要是CNN架构中的池化层。它将输入的图像分割为一组不重叠的矩形,并且对于每个子区域都输出一个值。
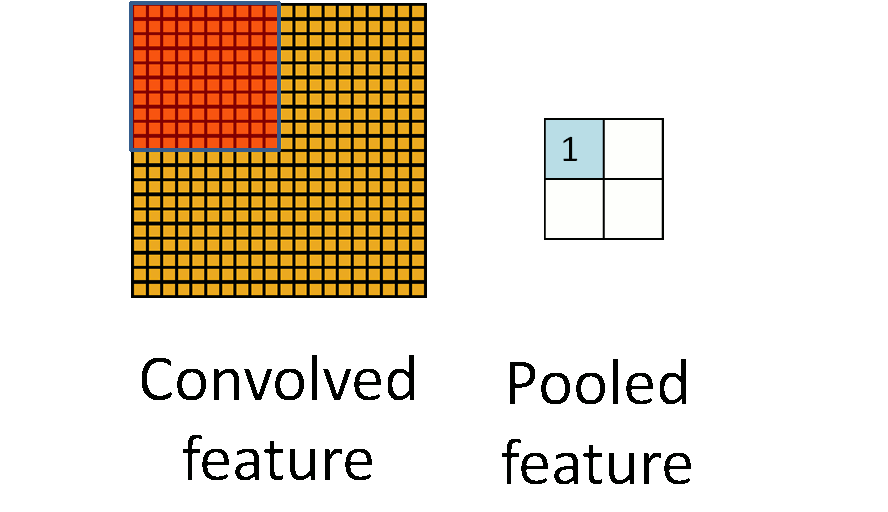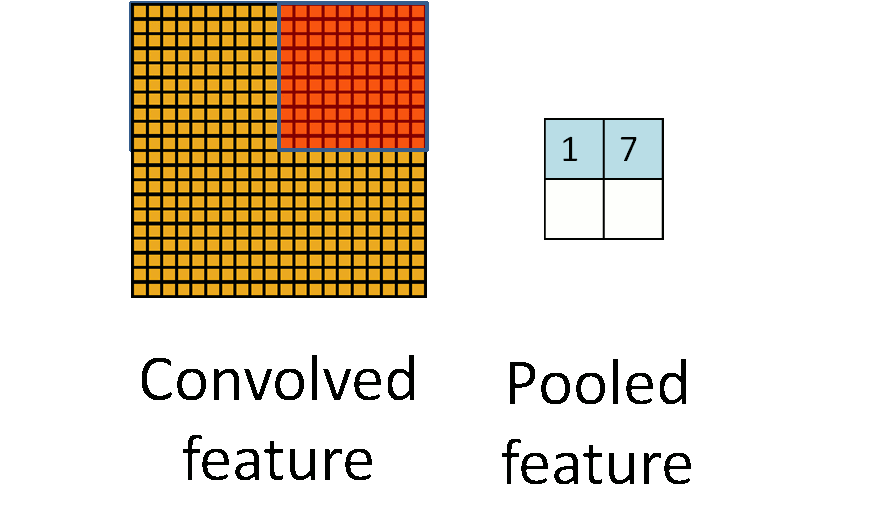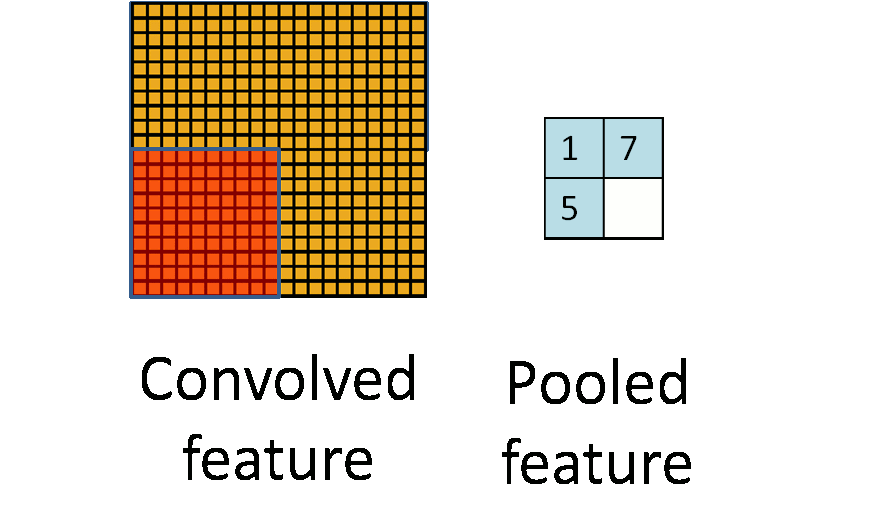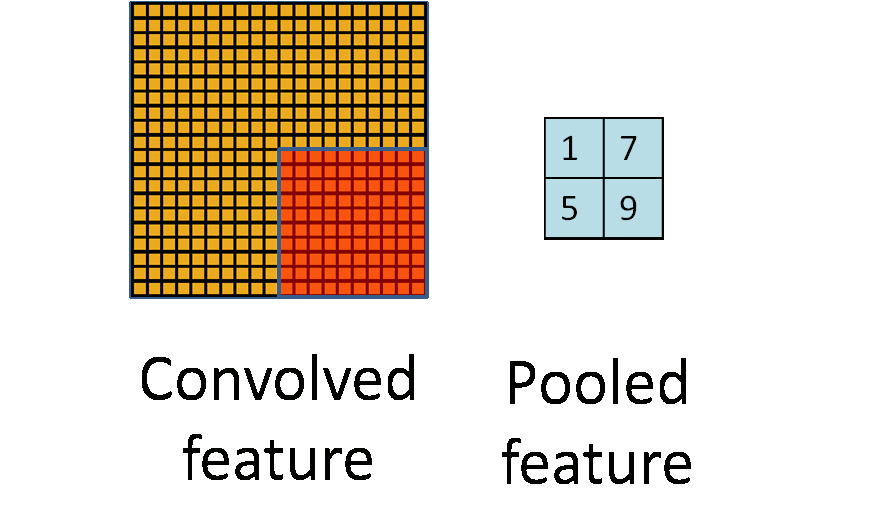
两个主要的池化层是最大池和平均池。
最大池 - 输出子区域的最大值。
平均池 - 输出子区域的平均值。
池化层用于减少空间维度而不是深度。
减少空间维度的主要优点是:
• 通过减少空间信息,可以优化计算性能。
• 通过减少空间信息意味着你可以使用较少的参数来训练模型,从而减少过度拟合的可能性。
• 获得一些固定的值。
激活函数
激活函数的工作方式与其他神经网络完全相同,该函数的主要左右是将值压缩到一个特定的范围内。一些常用的激活函数是:

最常用的激活函数是ReLu激活函数。它需要输入'x'并判断'x'是否为正,如果不为正则返回0。使用ReLu函数的原因是因为它的执行成本很低。
上图是卷积层的一般表示。我们通过池化层进行了卷积和ReLu函数。这些层彼此堆叠。
虽然定义和训练深度神经网络(DNN)比以往任何时候都容易,但大多数人还是会陷入误区。
为此目的,我们使用可视化来理解CNN模型中的各种层。
使用Keras实现可视化
在这部分我们将尝试使用Keras实现可视化。我们将使用Keras可视化输入,最大限度地激活VGG16体系结构的不同层中的滤波器,并对ImageNet进行训练。
首先,让我们从在Keras中定义VGG16模型开始:
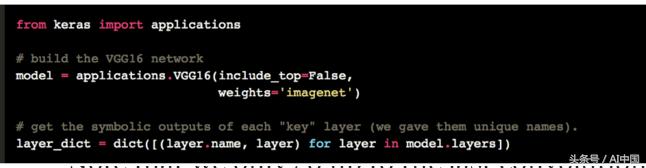
请注意,我们只进入最后一个卷积层。原因是添加完全连接的层会强制你使用模型的固定输入大小(224x224,原始ImageNet格式)。 通过保留卷积模块,我们的模型可以适应任意输入大小。
该模型加载了一组预先在ImageNet上训练过的权重。
现在让我们定义一个损失函数,它将促进特定层(layer_name)中的特定滤波器(filter_index)的激活。我们通过Keras后端函数执行此操作,该函数支持我们的代码在TensorFlow和Theano之上运行。
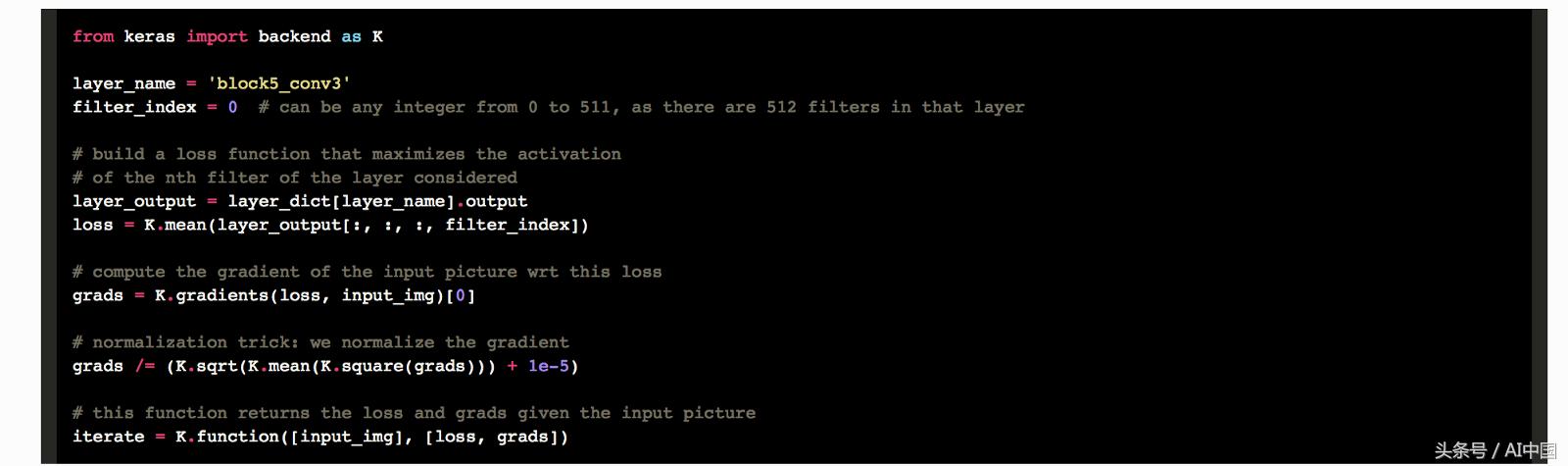
一切都很简单。这里唯一的技巧是规范输入图像的像素梯度,以确保梯度上升足够平滑。
现在我们可以使用我们定义的Keras函数在输入空间中进行梯度上升:

使用TensorFlow在CPU上执行此操作需要几秒钟。
然后我们可以提取并显示生成的输入:

结果:

第一层基本上只是编码方向和颜色。然后将这些方向和滤波器组合成基本网格和斑点纹理。这些纹理逐渐组合成越来越复杂的图案。
你可以将每层中的滤波器视为矢量的基础,它通常是完整的,可用于以紧凑的方式将输入层进行编码。当滤波器开始整合来自越来越大的空间范围的信息时,滤波器会变得更加复杂。
以下是从不同层生成的要素图的图片:

第1层主要生成水平、垂直和对角线。主要用于检测图像中的边缘。 第2层将尝试提供更多的信息。它主要检测角落。第3层我们开始可以检测到一些复杂的图案,如眼睛、脸等。我们可以假设这个特征图是从训练过的人脸检测模型中获得的。在第4层,它可以在面部的更复杂部分(例如眼睛)。
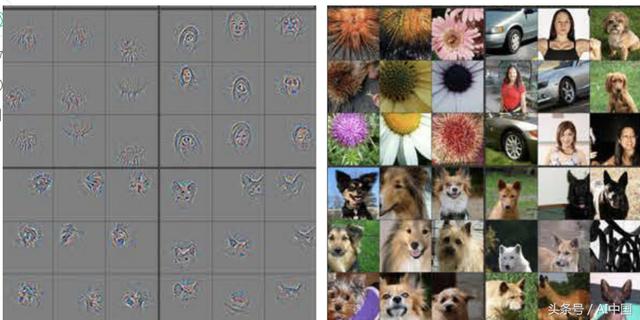
在第5层中,你可以使用要素图生成人的具体面孔、汽车轮胎、动物的面孔等。此要素图包含有关图像中的大多数信息。
结论
一般而言,CNN和其他图像识别模型并没有太大区别。我们可以通过阅读相关书籍加深对这方面的了解。
本文转自:今日头条 - AI中国 ,转载此文目的在于传递更多信息,版权归原作者所有。